 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementation and Evaluation of a Multivariate Abstraction-Based, Interval-Based Dynamic Time-Warping Method as a Similarity Measure for Longitudinal Medical Records
May 18, 2021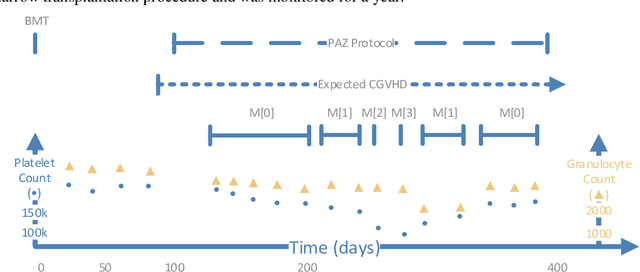


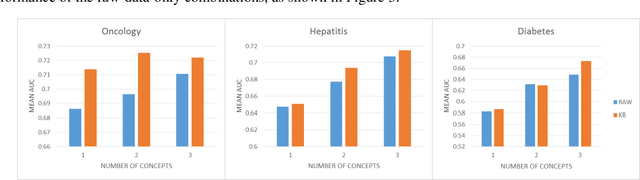
We extended dynamic time warping (DTW) into interval-based dynamic time warping (iDTW), including (A) interval-based representation (iRep): [1] abstracting raw, time-stamped data into interval-based abstractions, [2] comparison-period scoping, [3] partitioning abstract intervals into a given temporal granularity; (B) interval-based matching (iMatch): matching partitioned, abstract-concepts records, using a modified DTW. Using domain knowledge, we abstracted the raw data of medical records, for up to three concepts out of four or five relevant concepts, into two interval types: State abstractions (e.g. LOW, HIGH) and Gradient abstractions (e.g. INCREASING, DECREASING). We created all uni-dimensional (State or Gradient) or multi-dimensional (State and Gradient) abstraction combinations. Tasks: Classifying 161 oncology patients records as autologous or allogenic bone-marrow transplantation; classifying 125 hepatitis patients records as B or C hepatitis; predicting micro- or macro-albuminuria in the next year for 151 Type 2 diabetes patients. We used a k-Nearest-Neighbors majority, k=1 to SQRT(N), N = set size. 50,328 10-fold cross-validation experiments were performed: 23,400 (Oncology), 19,800 (Hepatitis), 7,128 (Diabetes). Measures: Area Under the Curve (AUC), optimal Youden's Index. Paired t-tests compared result vectors for equivalent configurations other than a tested variable, to determine a significant mean accuracy difference (P<0.05). Mean classification and prediction using abstractions was significantly better than using only raw time-stamped data. In each domain, at least one abstraction combination led to a significantly better performance than using raw data. Increasing feature number, and using multi-dimensional abstractions, enhanced performance. Unlike when using raw data, optimal performance was often reached with k=5, using abstractions.