 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Synthetic Images Serve as Effective and Efficient Class Prototypes?
Dec 19, 2025


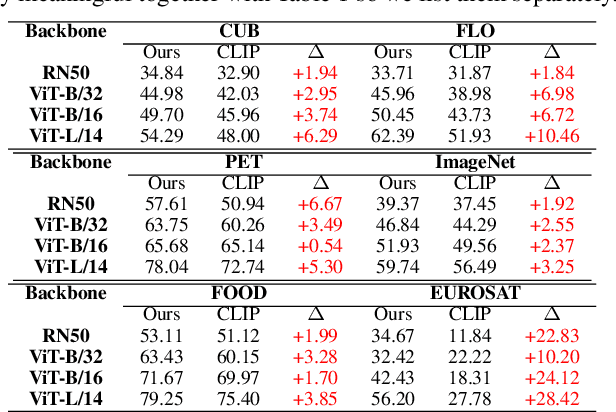
Vision-Language Models (VLMs) have shown strong performance in zero-shot image classification tasks. However, existing methods, including Contrastive Language-Image Pre-training (CLIP), all rely on annotated text-to-image pairs for aligning visual and textual modalities. This dependency introduces substantial cost and accuracy requirement in preparing high-quality datasets. At the same time, processing data from two modes also requires dual-tower encoders for most models, which also hinders their lightweight. To address these limitations, we introduce a ``Contrastive Language-Image Pre-training via Large-Language-Model-based Generation (LGCLIP)" framework. LGCLIP leverages a Large Language Model (LLM) to generate class-specific prompts that guide a diffusion model in synthesizing reference images. Afterwards these generated images serve as visual prototypes, and the visual features of real images are extracted and compared with the visual features of these prototypes to achieve comparative prediction. By optimizing prompt generation through the LLM and employing only a visual encoder, LGCLIP remains lightweight and efficient. Crucially, our framework requires only class labels as input during whole experimental procedure, eliminating the need for manually annotated image-text pairs and extra pre-processing. Experimental results validate the feasibility and efficiency of LGCLIP, demonstrating great performance in zero-shot classification tasks and establishing a novel paradigm for classification.
DAS: Neural Architecture Search via Distinguishing Activation Score
Dec 23, 2022

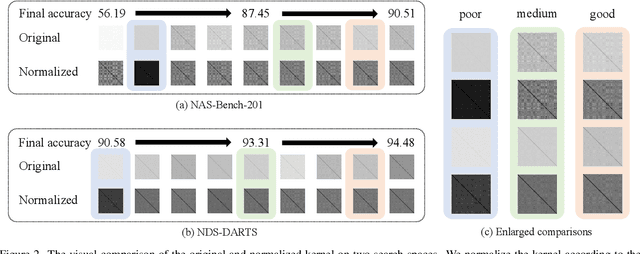

Neural Architecture Search (NAS) is an automatic technique that can search for well-performed architectures for a specific task. Although NAS surpasses human-designed architecture in many fields, the high computational cost of architecture evaluation it requires hinders its development. A feasible solution is to directly evaluate some metrics in the initial stage of the architecture without any training. NAS without training (WOT) score is such a metric, which estimates the final trained accuracy of the architecture through the ability to distinguish different inputs in the activation layer. However, WOT score is not an atomic metric, meaning that it does not represent a fundamental indicator of the architecture. The contributions of this paper are in three folds. First, we decouple WOT into two atomic metrics which represent the distinguishing ability of the network and the number of activation units, and explore better combination rules named (Distinguishing Activation Score) DAS. We prove the correctness of decoupling theoretically and confirmed the effectiveness of the rules experimentally. Second, in order to improve the prediction accuracy of DAS to meet practical search requirements, we propose a fast training strategy. When DAS is used in combination with the fast training strategy, it yields more improvements. Third, we propose a dataset called Darts-training-bench (DTB), which fills the gap that no training states of architecture in existing datasets. Our proposed method has 1.04$\times$ - 1.56$\times$ improvements on NAS-Bench-101, Network Design Spaces, and the proposed DTB.
Architecture Augmentation for Performance Predictor Based on Graph Isomorphism
Jul 03, 2022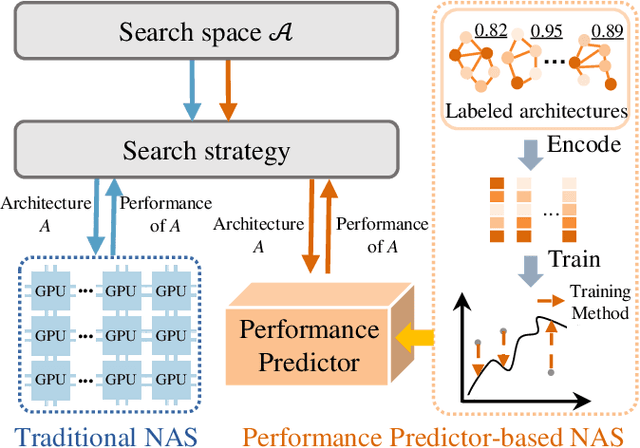
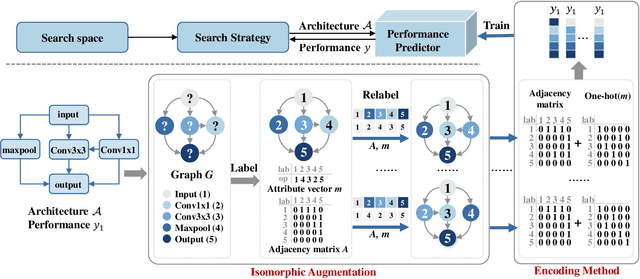
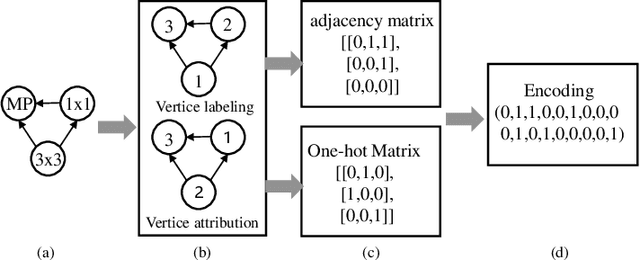
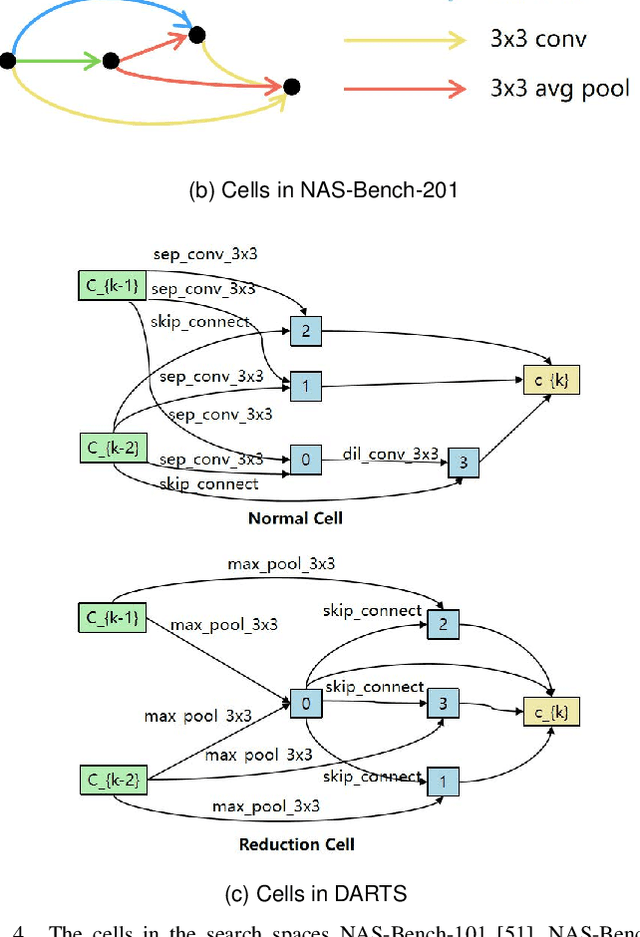
Neural Architecture Search (NAS) can automatically design architectures for deep neural networks (DNNs) and has become one of the hottest research topics in the current machine learning community. However, NAS is often computationally expensive because a large number of DNNs require to be trained for obtaining performance during the search process. Performance predictors can greatly alleviate the prohibitive cost of NAS by directly predicting the performance of DNNs. However, building satisfactory performance predictors highly depends on enough trained DNN architectures, which are difficult to obtain in most scenarios. To solve this critical issue, we propose an effective DNN architecture augmentation method named GIAug in this paper. Specifically, we first propose a mechanism based on graph isomorphism, which has the merit of efficiently generating a factorial of $\boldsymbol n$ (i.e., $\boldsymbol n!$) diverse annotated architectures upon a single architecture having $\boldsymbol n$ nodes. In addition, we also design a generic method to encode the architectures into the form suitable to most prediction models. As a result, GIAug can be flexibly utilized by various existing performance predictors-based NAS algorithms. We perform extensive experiments on CIFAR-10 and ImageNet benchmark datasets on small-, medium- and large-scale search space. The experiments show that GIAug can significantly enhance the performance of most state-of-the-art peer predictors. In addition, GIAug can save three magnitude order of computation cost at most on ImageNet yet with similar performance when compared with state-of-the-art NAS algorithms.
Evolving Deep Neural Networks for Collaborative Filtering
Nov 15, 2021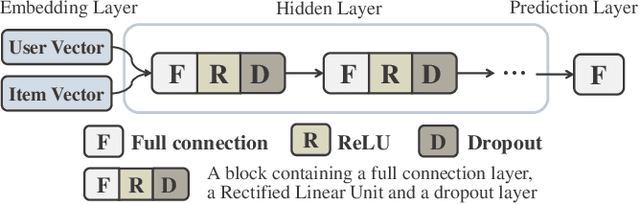
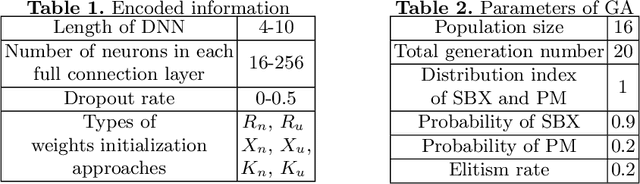
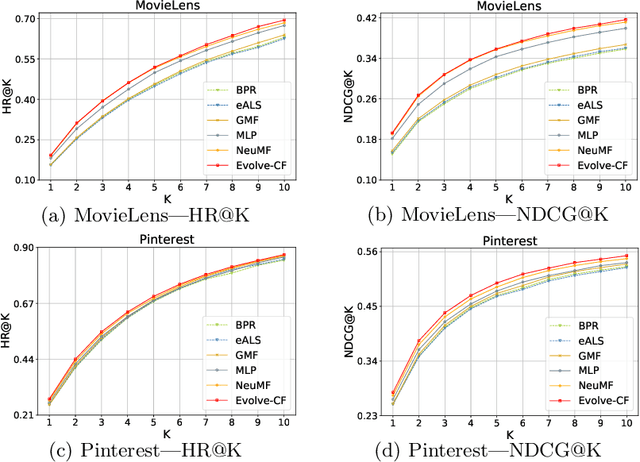
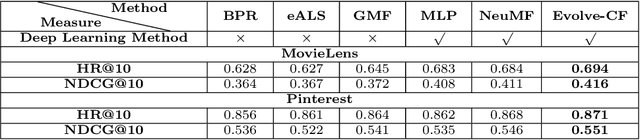
Collaborative Filtering (CF) is widely used in recommender systems to model user-item interactions. With the great success of Deep Neural Networks (DNNs) in various fields, advanced works recently have proposed several DNN-based models for CF, which have been proven effective. However, the neural networks are all designed manually. As a consequence, it requires the designers to develop expertise in both CF and DNNs, which limits the application of deep learning methods in CF and the accuracy of recommended results. In this paper, we introduce the genetic algorithm into the process of designing DNNs. By means of genetic operations like crossover, mutation, and environmental selection strategy, the architectures and the connection weights initialization of the DNNs can be designed automatically. We conduct extensive experiments on two benchmark datasets. The results demonstrate the proposed algorithm outperforms several manually designed state-of-the-art neural networks.
BenchENAS: A Benchmarking Platform for Evolutionary Neural Architecture Search
Aug 14, 2021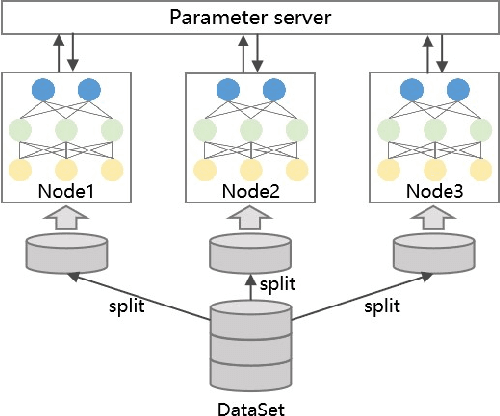
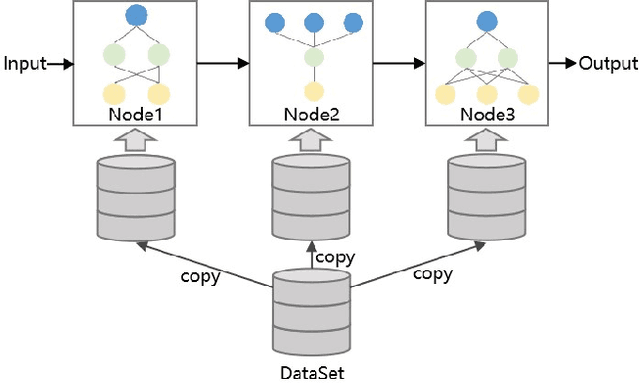
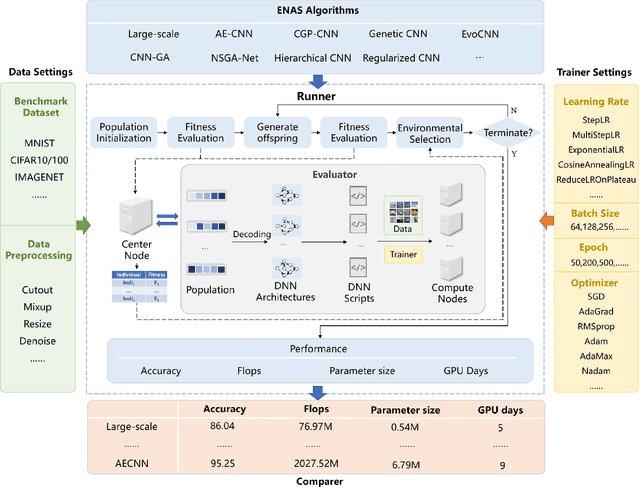
Neural architecture search (NAS), which automatically designs the architectures of deep neural networks, has achieved breakthrough success over many applications in the past few years. Among different classes of NAS methods, evolutionary computation based NAS (ENAS) methods have recently gained much attention. Unfortunately, the issues of fair comparisons and efficient evaluations have hindered the development of ENAS. The current benchmark architecture datasets designed for fair comparisons only provide the datasets, not the ENAS algorithms or the platform to run the algorithms. The existing efficient evaluation methods are either not suitable for the population-based ENAS algorithm or are too complex to use. This paper develops a platform named BenchENAS to address these issues. BenchENAS aims to achieve fair comparisons by running different algorithms in the same environment and with the same settings. To achieve efficient evaluation in a common lab environment, BenchENAS designs a parallel component and a cache component with high maintainability. Furthermore, BenchENAS is easy to install and highly configurable and modular, which brings benefits in good usability and easy extensibility. The paper conducts efficient comparison experiments on eight ENAS algorithms with high GPU utilization on this platform. The experiments validate that the fair comparison issue does exist, and BenchENAS can alleviate this issue. A website has been built to promote BenchENAS at https://benchenas.com, where interested researchers can obtain the source code and document of BenchENAS for free.
Homogeneous Architecture Augmentation for Neural Predictor
Jul 28, 2021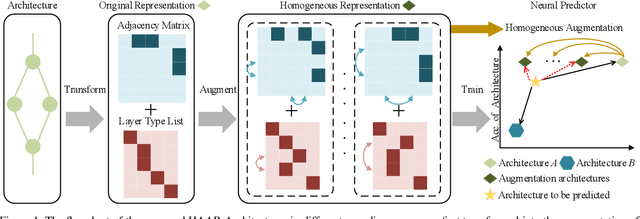
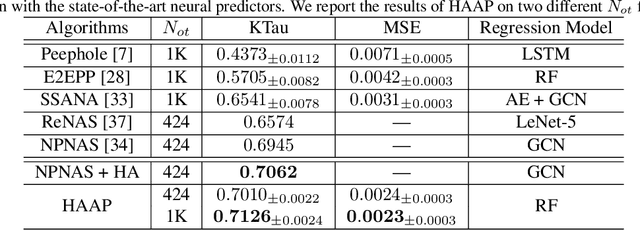
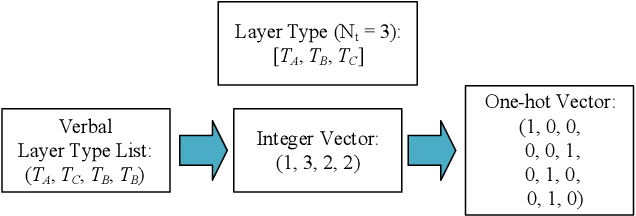
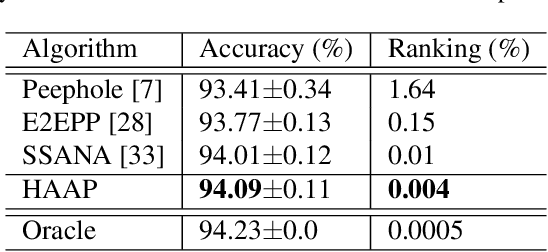
Neural Architecture Search (NAS) can automatically design well-performed architectures of Deep Neural Networks (DNNs) for the tasks at hand. However, one bottleneck of NAS is the prohibitively computational cost largely due to the expensive performance evaluation. The neural predictors can directly estimate the performance without any training of the DNNs to be evaluated, thus have drawn increasing attention from researchers. Despite their popularity, they also suffer a severe limitation: the shortage of annotated DNN architectures for effectively training the neural predictors. In this paper, we proposed Homogeneous Architecture Augmentation for Neural Predictor (HAAP) of DNN architectures to address the issue aforementioned. Specifically, a homogeneous architecture augmentation algorithm is proposed in HAAP to generate sufficient training data taking the use of homogeneous representation. Furthermore, the one-hot encoding strategy is introduced into HAAP to make the representation of DNN architectures more effective. The experiments have been conducted on both NAS-Benchmark-101 and NAS-Bench-201 dataset. The experimental results demonstrate that the proposed HAAP algorithm outperforms the state of the arts compared, yet with much less training data. In addition, the ablation studies on both benchmark datasets have also shown the universality of the homogeneous architecture augmentation.
A Survey on Evolutionary Neural Architecture Search
Aug 25, 2020
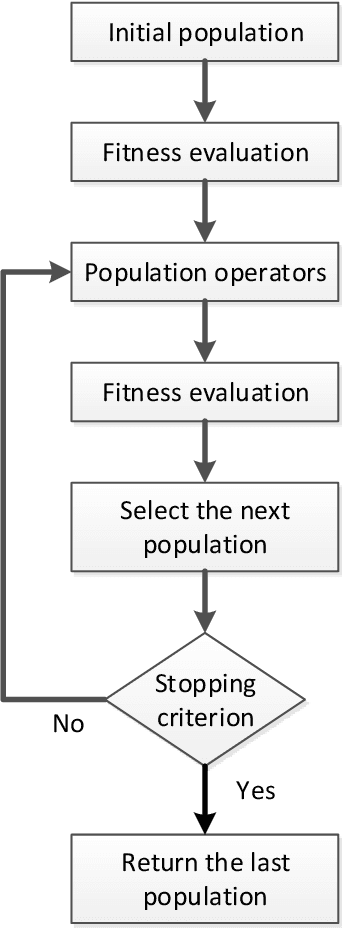


Deep Neural Networks (DNNs) have achieved great success in many applications, such as image classification, natural language processing and speech recognition. The architectures of DNNs have been proved to play a crucial role in its performance. However, designing architectures for different tasks is a difficult and time-consuming process of trial and error. Neural Architecture Search (NAS), which received great attention in recent years, can design the architecture automatically. Among different kinds of NAS methods, Evolutionary Computation (EC) based NAS methods have recently gained much attention and success. Unfortunately, there is not a comprehensive summary of the EC-based methods. This paper reviews 100+ papers of EC-based NAS methods in light of the common process. Four steps of the process have been covered in this paper including population initialization, population operators, evaluation and selection. Furthermore, current challenges and issues are also discussed to identify future research in this field.
Evolving Deep Convolutional Neural Networks for Hyperspectral Image Denoising
Aug 15, 2020



Hyperspectral images (HSIs) are susceptible to various noise factors leading to the loss of information, and the noise restricts the subsequent HSIs object detection and classification tasks. In recent years, learning-based methods have demonstrated their superior strengths in denoising the HSIs. Unfortunately, most of the methods are manually designed based on the extensive expertise that is not necessarily available to the users interested. In this paper, we propose a novel algorithm to automatically build an optimal Convolutional Neural Network (CNN) to effectively denoise HSIs. Particularly, the proposed algorithm focuses on the architectures and the initialization of the connection weights of the CNN. The experiments of the proposed algorithm have been well-designed and compared against the state-of-the-art peer competitors, and the experimental results demonstrate the competitive performance of the proposed algorithm in terms of the different evaluation metrics, visual assessments, and the computational complexity.