 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Deep Neural Networks for Collaborative Filtering
Nov 15, 2021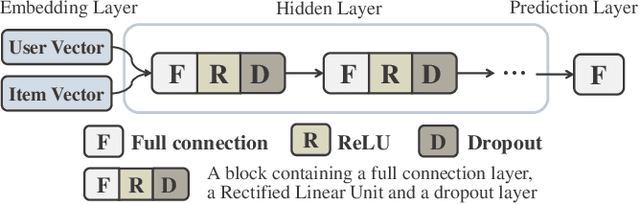
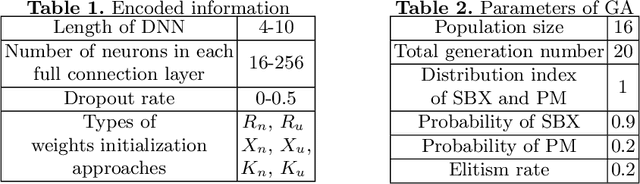
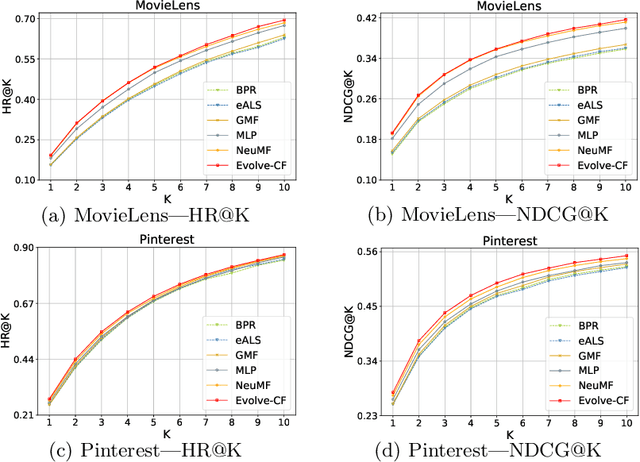
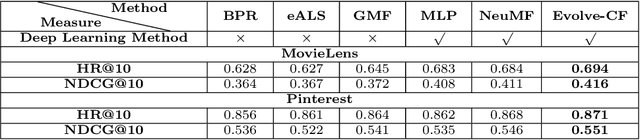
Collaborative Filtering (CF) is widely used in recommender systems to model user-item interactions. With the great success of Deep Neural Networks (DNNs) in various fields, advanced works recently have proposed several DNN-based models for CF, which have been proven effective. However, the neural networks are all designed manually. As a consequence, it requires the designers to develop expertise in both CF and DNNs, which limits the application of deep learning methods in CF and the accuracy of recommended results. In this paper, we introduce the genetic algorithm into the process of designing DNNs. By means of genetic operations like crossover, mutation, and environmental selection strategy, the architectures and the connection weights initialization of the DNNs can be designed automatically. We conduct extensive experiments on two benchmark datasets. The results demonstrate the proposed algorithm outperforms several manually designed state-of-the-art neural networks.
A Novel Training Protocol for Performance Predictors of Evolutionary Neural Architecture Search Algorithms
Sep 07, 2020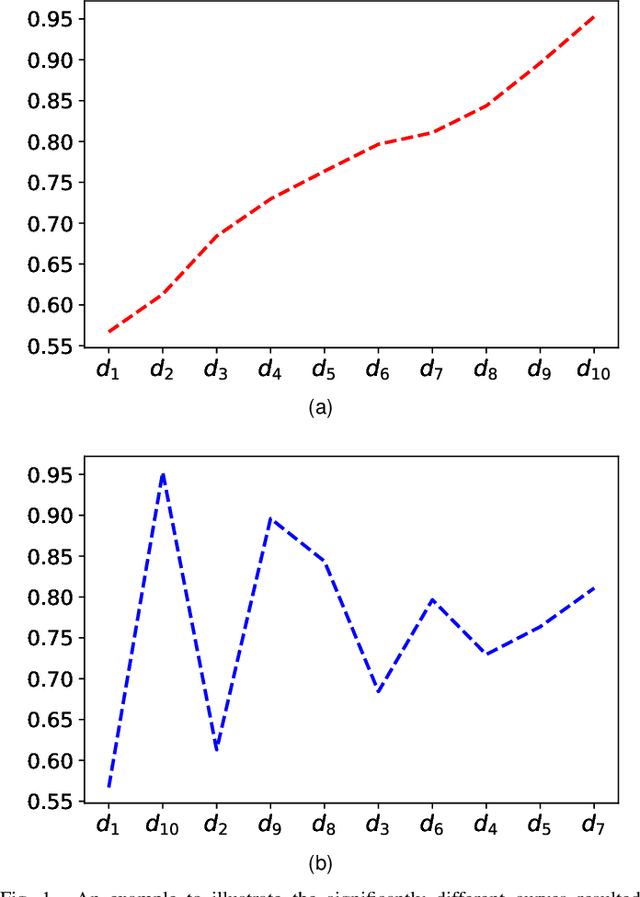
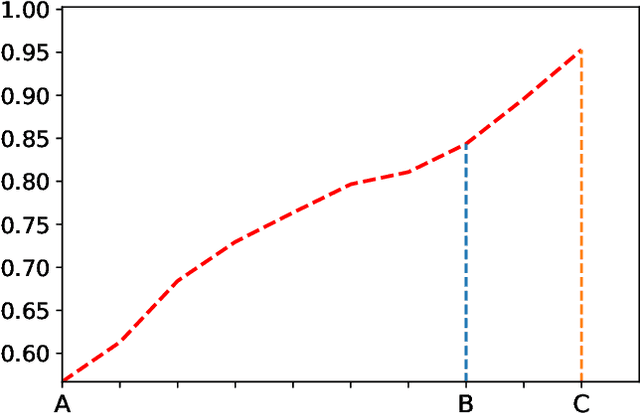
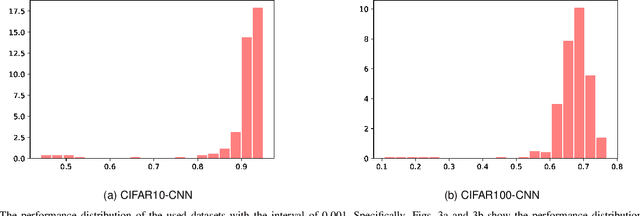

Evolutionary Neural Architecture Search (ENAS) can automatically design the architectures of Deep Neural Networks (DNNs) using evolutionary computation algorithms. However, most ENAS algorithms require intensive computational resource, which is not necessarily available to the users interested. Performance predictors are a type of regression models which can assist to accomplish the search, while without exerting much computational resource. Despite various performance predictors have been designed, they employ the same training protocol to build the regression models: 1) sampling a set of DNNs with performance as the training dataset, 2) training the model with the mean square error criterion, and 3) predicting the performance of DNNs newly generated during the ENAS. In this paper, we point out that the three steps constituting the training protocol are not well though-out through intuitive and illustrative examples. Furthermore, we propose a new training protocol to address these issues, consisting of designing a pairwise ranking indicator to construct the training target, proposing to use the logistic regression to fit the training samples, and developing a differential method to building the training instances. To verify the effectiveness of the proposed training protocol, four widely used regression models in the field of machine learning have been chosen to perform the comparisons on two benchmark datasets. The experimental results of all the comparisons demonstrate that the proposed training protocol can significantly improve the performance prediction accuracy against the traditional training protocols.