 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint semi-supervised and contrastive learning enables zero-shot domain-adaptation and multi-domain segmentation
May 08, 2024



Despite their effectiveness, current deep learning models face challenges with images coming from different domains with varying appearance and content. We introduce SegCLR, a versatile framework designed to segment volumetric images across different domains, employing supervised and contrastive learning simultaneously to effectively learn from both labeled and unlabeled data. We demonstrate the superior performance of SegCLR through a comprehensive evaluation involving three diverse clinical datasets of retinal fluid segmentation in 3D Optical Coherence Tomography (OCT), various network configurations, and verification across 10 different network initializations. In an unsupervised domain adaptation context, SegCLR achieves results on par with a supervised upper-bound model trained on the intended target domain. Notably, we discover that the segmentation performance of SegCLR framework is marginally impacted by the abundance of unlabeled data from the target domain, thereby we also propose an effective zero-shot domain adaptation extension of SegCLR, eliminating the need for any target domain information. This shows that our proposed addition of contrastive loss in standard supervised training for segmentation leads to superior models, inherently more generalizable to both in- and out-of-domain test data. We additionally propose a pragmatic solution for SegCLR deployment in realistic scenarios with multiple domains containing labeled data. Accordingly, our framework pushes the boundaries of deep-learning based segmentation in multi-domain applications, regardless of data availability - labeled, unlabeled, or nonexistent.
Quantum Vision Transformers
Sep 16, 2022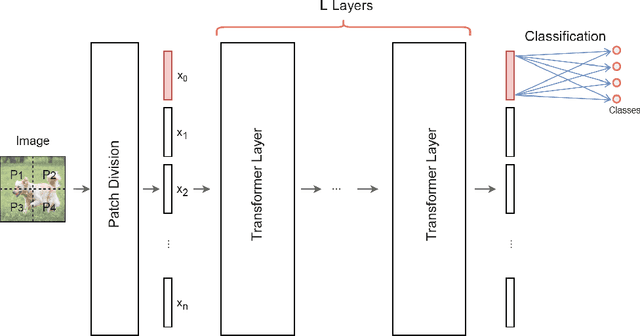
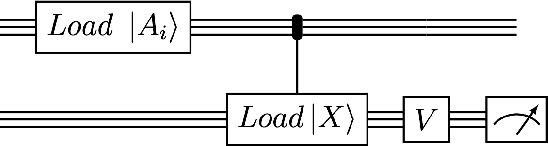
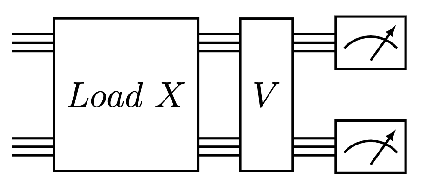
We design and analyse quantum transformers, extending the state-of-the-art classical transformer neural network architectures known to be very performant in natural language processing and image analysis. Building upon the previous work of parametrised quantum circuits for data loading and orthogonal neural layers, we introduce three quantum attention mechanisms, including a quantum transformer based on compound matrices. These quantum architectures can be built using shallow quantum circuits and can provide qualitatively different classification models. We performed extensive simulations of the quantum transformers on standard medical image datasets that showed competitive, and at times better, performance compared with the best classical transformers and other classical benchmarks. The computational complexity of our quantum attention layer proves to be advantageous compared with the classical algorithm with respect to the size of the classified images. Our quantum architectures have thousands of parameters compared with the best classical methods with millions of parameters. Finally, we have implemented our quantum transformers on superconducting quantum computers and obtained encouraging results for up to six qubit experiments.
Unsupervised Domain Adaptation with Contrastive Learning for OCT Segmentation
Mar 07, 2022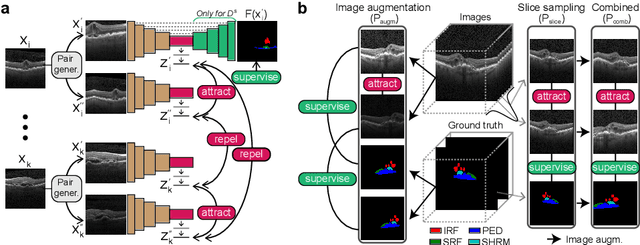
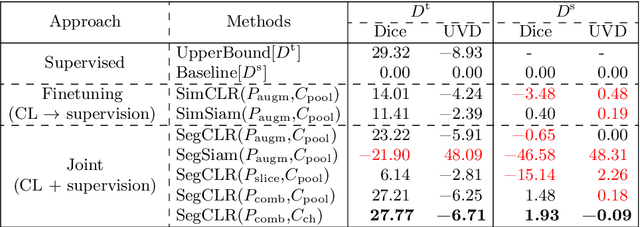

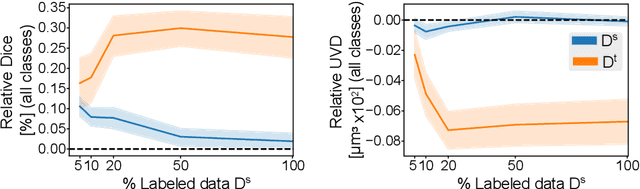
Accurate segmentation of retinal fluids in 3D Optical Coherence Tomography images is key for diagnosis and personalized treatment of eye diseases. While deep learning has been successful at this task, trained supervised models often fail for images that do not resemble labeled examples, e.g. for images acquired using different devices. We hereby propose a novel semi-supervised learning framework for segmentation of volumetric images from new unlabeled domains. We jointly use supervised and contrastive learning, also introducing a contrastive pairing scheme that leverages similarity between nearby slices in 3D. In addition, we propose channel-wise aggregation as an alternative to conventional spatial-pooling aggregation for contrastive feature map projection. We evaluate our methods for domain adaptation from a (labeled) source domain to an (unlabeled) target domain, each containing images acquired with different acquisition devices. In the target domain, our method achieves a Dice coefficient 13.8% higher than SimCLR (a state-of-the-art contrastive framework), and leads to results comparable to an upper bound with supervised training in that domain. In the source domain, our model also improves the results by 5.4% Dice, by successfully leveraging information from many unlabeled images.