 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint semi-supervised and contrastive learning enables zero-shot domain-adaptation and multi-domain segmentation
May 08, 2024



Despite their effectiveness, current deep learning models face challenges with images coming from different domains with varying appearance and content. We introduce SegCLR, a versatile framework designed to segment volumetric images across different domains, employing supervised and contrastive learning simultaneously to effectively learn from both labeled and unlabeled data. We demonstrate the superior performance of SegCLR through a comprehensive evaluation involving three diverse clinical datasets of retinal fluid segmentation in 3D Optical Coherence Tomography (OCT), various network configurations, and verification across 10 different network initializations. In an unsupervised domain adaptation context, SegCLR achieves results on par with a supervised upper-bound model trained on the intended target domain. Notably, we discover that the segmentation performance of SegCLR framework is marginally impacted by the abundance of unlabeled data from the target domain, thereby we also propose an effective zero-shot domain adaptation extension of SegCLR, eliminating the need for any target domain information. This shows that our proposed addition of contrastive loss in standard supervised training for segmentation leads to superior models, inherently more generalizable to both in- and out-of-domain test data. We additionally propose a pragmatic solution for SegCLR deployment in realistic scenarios with multiple domains containing labeled data. Accordingly, our framework pushes the boundaries of deep-learning based segmentation in multi-domain applications, regardless of data availability - labeled, unlabeled, or nonexistent.
Transfer Learning for Retinal Vascular Disease Detection: A Pilot Study with Diabetic Retinopathy and Retinopathy of Prematurity
Jan 04, 2022

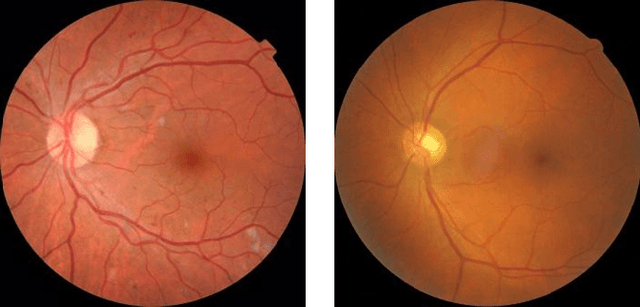

Retinal vascular diseases affect the well-being of human body and sometimes provide vital signs of otherwise undetected bodily damage. Recently, deep learning techniques have been successfully applied for detection of diabetic retinopathy (DR). The main obstacle of applying deep learning techniques to detect most other retinal vascular diseases is the limited amount of data available. In this paper, we propose a transfer learning technique that aims to utilize the feature similarities for detecting retinal vascular diseases. We choose the well-studied DR detection as a source task and identify the early detection of retinopathy of prematurity (ROP) as the target task. Our experimental results demonstrate that our DR-pretrained approach dominates in all metrics the conventional ImageNet-pretrained transfer learning approach, currently adopted in medical image analysis. Moreover, our approach is more robust with respect to the stochasticity in the training process and with respect to reduced training samples. This study suggests the potential of our proposed transfer learning approach for a broad range of retinal vascular diseases or pathologies, where data is limited.
Early Detection of Retinopathy of Prematurity in Retinal Fundus Images Via Convolutional Neural Networks
Jun 12, 2020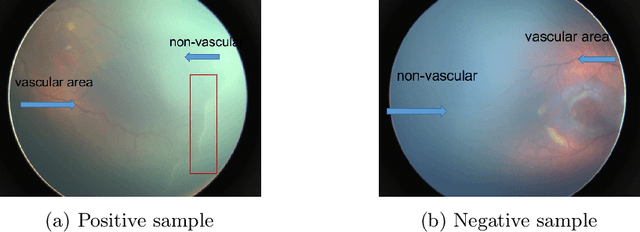


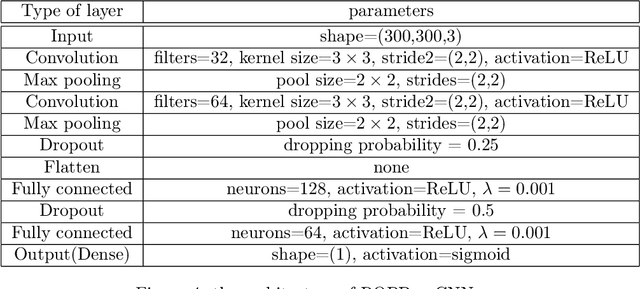
Retinopathy of prematurity (ROP) is an abnormal blood vessel development in the retina of a prematurely-born infant or an infant with low birth weight. ROP is one of the leading causes for infant blindness globally. Early detection of ROP is critical to slow down and avert the progression to vision impairment caused by ROP. Yet there is limited awareness of ROP even among medical professionals. Consequently, dataset for ROP is limited if ever available, and is in general extremely imbalanced in terms of the ratio between negative images and positive ones. In this study, we formulate the problem of detecting ROP in retinal fundus images in an optimization framework, and apply state-of-art convolutional neural network techniques to solve this problem. Experimental results based on our models achieve 100 percent sensitivity, 96 percent specificity, 98 percent accuracy, and 96 percent precision. In addition, our study shows that as the network gets deeper, more significant features can be extracted for better understanding of ROP.