 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation with Contrastive Learning for OCT Segmentation
Paper and Code
Mar 07, 2022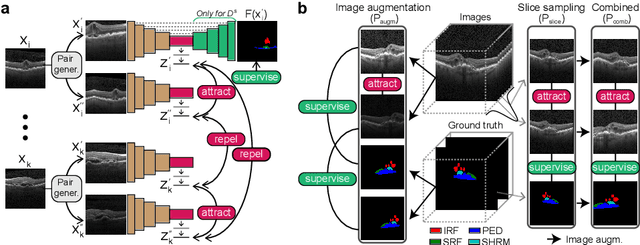
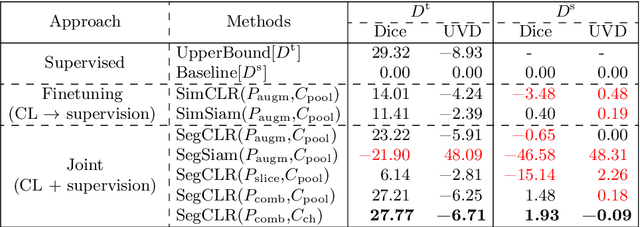

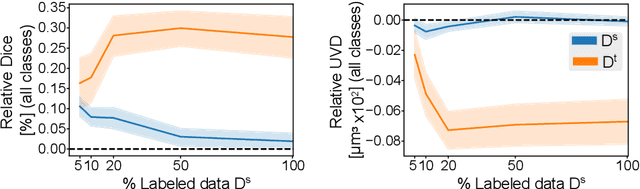
Accurate segmentation of retinal fluids in 3D Optical Coherence Tomography images is key for diagnosis and personalized treatment of eye diseases. While deep learning has been successful at this task, trained supervised models often fail for images that do not resemble labeled examples, e.g. for images acquired using different devices. We hereby propose a novel semi-supervised learning framework for segmentation of volumetric images from new unlabeled domains. We jointly use supervised and contrastive learning, also introducing a contrastive pairing scheme that leverages similarity between nearby slices in 3D. In addition, we propose channel-wise aggregation as an alternative to conventional spatial-pooling aggregation for contrastive feature map projection. We evaluate our methods for domain adaptation from a (labeled) source domain to an (unlabeled) target domain, each containing images acquired with different acquisition devices. In the target domain, our method achieves a Dice coefficient 13.8% higher than SimCLR (a state-of-the-art contrastive framework), and leads to results comparable to an upper bound with supervised training in that domain. In the source domain, our model also improves the results by 5.4% Dice, by successfully leveraging information from many unlabeled images.