 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Compact Parameter Representations for Architecture-Agnostic Neural Network Compression
Nov 19, 2021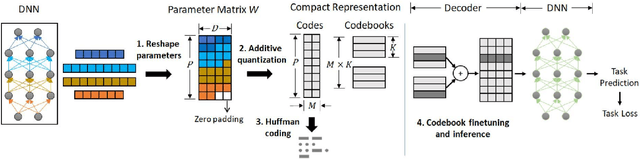
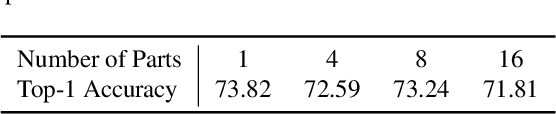


This paper investigates deep neural network (DNN) compression from the perspective of compactly representing and storing trained parameters. We explore the previously overlooked opportunity of cross-layer architecture-agnostic representation sharing for DNN parameters. To do this, we decouple feedforward parameters from DNN architectures and leverage additive quantization, an extreme lossy compression method invented for image descriptors, to compactly represent the parameters. The representations are then finetuned on task objectives to improve task accuracy. We conduct extensive experiments on MobileNet-v2, VGG-11, ResNet-50, Feature Pyramid Networks, and pruned DNNs trained for classification, detection, and segmentation tasks. The conceptually simple scheme consistently outperforms iterative unstructured pruning. Applied to ResNet-50 with 76.1% top-1 accuracy on the ILSVRC12 classification challenge, it achieves a $7.2\times$ compression ratio with no accuracy loss and a $15.3\times$ compression ratio at 74.79% accuracy. Further analyses suggest that representation sharing can frequently happen across network layers and that learning shared representations for an entire DNN can achieve better accuracy at the same compression ratio than compressing the model as multiple separate parts. We release PyTorch code to facilitate DNN deployment on resource-constrained devices and spur future research on efficient representations and storage of DNN parameters.
Rethinking Exposure Bias In Language Modeling
Oct 13, 2019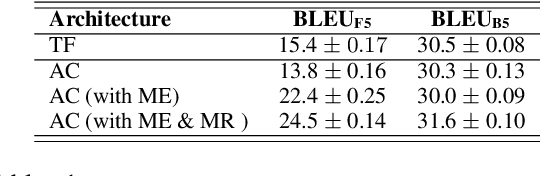
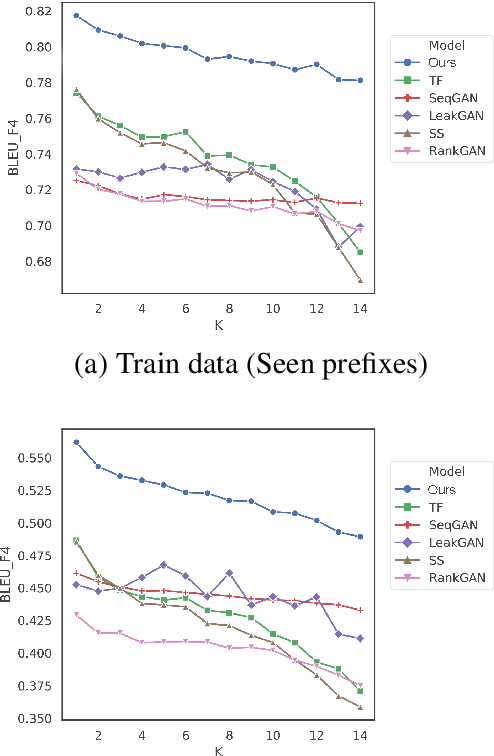


Exposure bias describes the phenomenon that a language model trained under the teacher forcing schema may perform poorly at the inference stage when its predictions are conditioned on its previous predictions unseen from the training corpus. Recently, several generative adversarial networks (GANs) and reinforcement learning (RL) methods have been introduced to alleviate this problem. Nonetheless, a common issue in RL and GANs training is the sparsity of reward signals. In this paper, we adopt two simple strategies, multi-range reinforcing, and multi-entropy sampling, to amplify and denoise the reward signal. Our model produces an improvement over competing models with regards to BLEU scores and road exam, a new metric we designed to measure the robustness against exposure bias in language models.