 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Program Synthesis By Self-Learning
Oct 13, 2019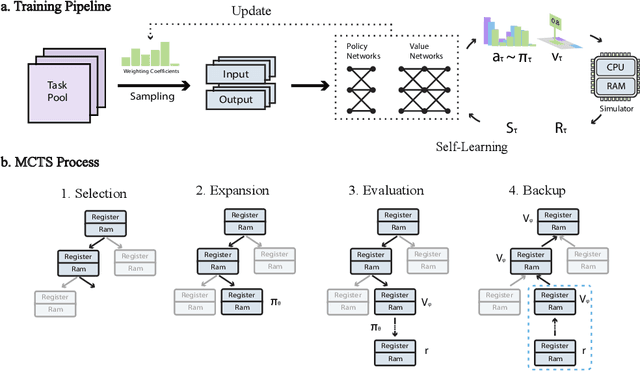
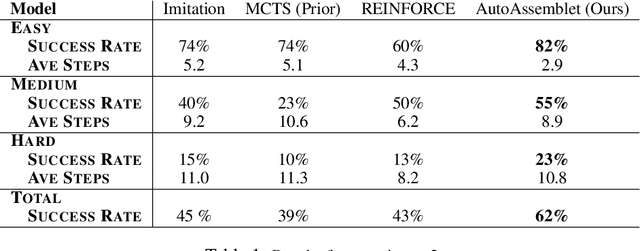

Neural inductive program synthesis is a task generating instructions that can produce desired outputs from given inputs. In this paper, we focus on the generation of a chunk of assembly code that can be executed to match a state change inside the CPU and RAM. We develop a neural program synthesis algorithm, AutoAssemblet, learned via self-learning reinforcement learning that explores the large code space efficiently. Policy networks and value networks are learned to reduce the breadth and depth of the Monte Carlo Tree Search, resulting in better synthesis performance. We also propose an effective multi-entropy policy sampling technique to alleviate online update correlations. We apply AutoAssemblet to basic programming tasks and show significant higher success rates compared to several competing baselines.
Rethinking Exposure Bias In Language Modeling
Oct 13, 2019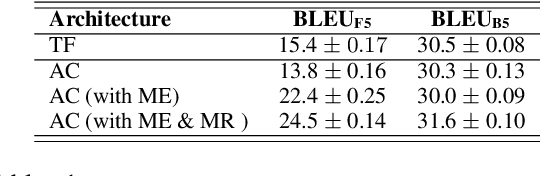
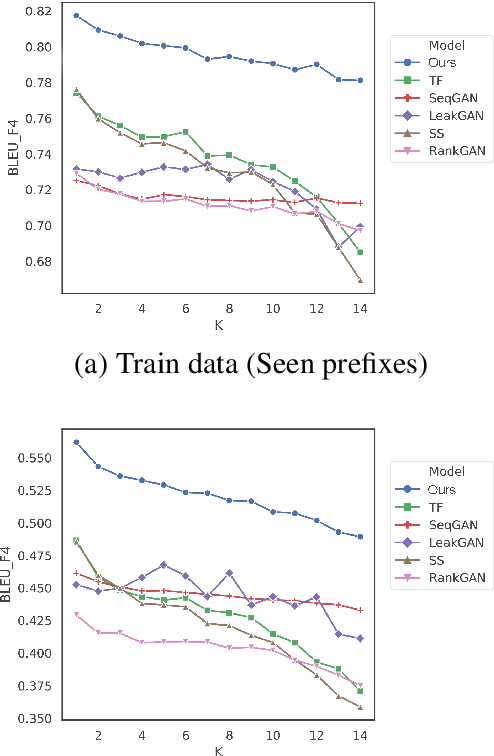


Exposure bias describes the phenomenon that a language model trained under the teacher forcing schema may perform poorly at the inference stage when its predictions are conditioned on its previous predictions unseen from the training corpus. Recently, several generative adversarial networks (GANs) and reinforcement learning (RL) methods have been introduced to alleviate this problem. Nonetheless, a common issue in RL and GANs training is the sparsity of reward signals. In this paper, we adopt two simple strategies, multi-range reinforcing, and multi-entropy sampling, to amplify and denoise the reward signal. Our model produces an improvement over competing models with regards to BLEU scores and road exam, a new metric we designed to measure the robustness against exposure bias in language models.