 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLQ: Bridging Modalities via Shared Latent Queries for Retrieval with Frozen MLLMs
Apr 16, 2026Multimodal Large Language Models (MLLMs) exhibit strong reasoning and world knowledge, yet adapting them for retrieval remains challenging. Existing approaches rely on invasive parameter updates, such as full fine-tuning and LoRA, which may disrupt the pre-trained semantic space and impair the structured knowledge essential for reasoning. In this work, we argue that adapting MLLMs for retrieval should focus on eliciting pre-trained representations rather than overwriting them. To this end, we propose SLQ, an effective and efficient framework that adapts a frozen MLLM into a retriever through a small set of Shared Latent Queries. Appended to the end of both text and image token sequences, these queries leverage the model's native causal attention to serve as global aggregation interfaces, producing compact embeddings in a unified space while keeping the backbone unchanged. Furthermore, to better evaluate retrieval beyond superficial pattern matching, we construct KARR-Bench, a benchmark designed for knowledge-aware reasoning retrieval. Extensive experiments show that SLQ outperforms full fine-tuning and LoRA on COCO and Flickr30K, while achieving competitive performance on MMEB and yielding substantial gains on KARR-Bench. The results demonstrate that SLQ, which preserves pre-trained representations, provides an effective and efficient framework for adapting MLLMs to retrieval.
PCANet-II: When PCANet Meets the Second Order Pooling
Sep 30, 2017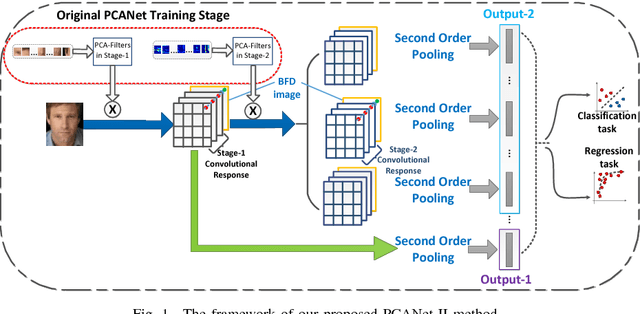

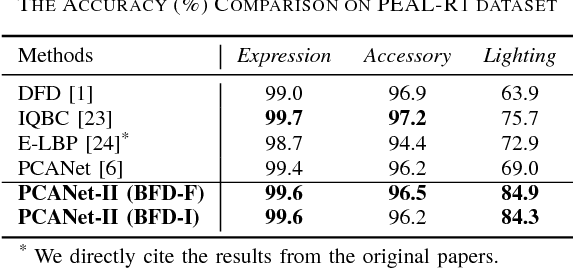
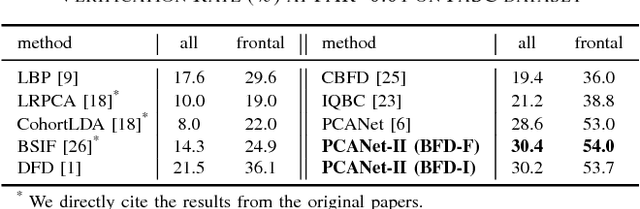
PCANet, as one noticeable shallow network, employs the histogram representation for feature pooling. However, there are three main problems about this kind of pooling method. First, the histogram-based pooling method binarizes the feature maps and leads to inevitable discriminative information loss. Second, it is difficult to effectively combine other visual cues into a compact representation, because the simple concatenation of various visual cues leads to feature representation inefficiency. Third, the dimensionality of histogram-based output grows exponentially with the number of feature maps used. In order to overcome these problems, we propose a novel shallow network model, named as PCANet-II. Compared with the histogram-based output, the second order pooling not only provides more discriminative information by preserving both the magnitude and sign of convolutional responses, but also dramatically reduces the size of output features. Thus we combine the second order statistical pooling method with the shallow network, i.e., PCANet. Moreover, it is easy to combine other discriminative and robust cues by using the second order pooling. So we introduce the binary feature difference encoding scheme into our PCANet-II to further improve robustness. Experiments demonstrate the effectiveness and robustness of our proposed PCANet-II method.
Improving Deep Neural Network with Multiple Parametric Exponential Linear Units
Jan 17, 2017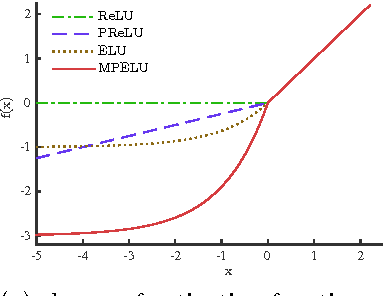


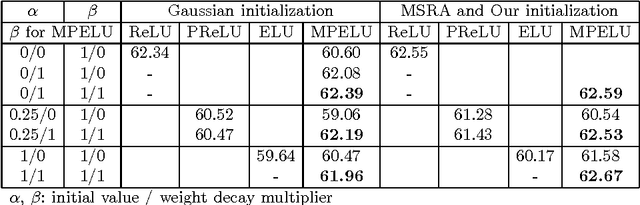
Activation function is crucial to the recent successes of deep neural networks. In this paper, we first propose a new activation function, Multiple Parametric Exponential Linear Units (MPELU), aiming to generalize and unify the rectified and exponential linear units. As the generalized form, MPELU shares the advantages of Parametric Rectified Linear Unit (PReLU) and Exponential Linear Unit (ELU), leading to better classification performance and convergence property. In addition, weight initialization is very important to train very deep networks. The existing methods laid a solid foundation for networks using rectified linear units but not for exponential linear units. This paper complements the current theory and extends it to the wider range. Specifically, we put forward a way of initialization, enabling training of very deep networks using exponential linear units. Experiments demonstrate that the proposed initialization not only helps the training process but leads to better generalization performance. Finally, utilizing the proposed activation function and initialization, we present a deep MPELU residual architecture that achieves state-of-the-art performance on the CIFAR-10/100 datasets. The code is available at https://github.com/Coldmooon/Code-for-MPELU.