 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinSage: A Multi-aspect RAG System for Financial Filings Question Answering
Apr 20, 2025Leveraging large language models in real-world settings often entails a need to utilize domain-specific data and tools in order to follow the complex regulations that need to be followed for acceptable use. Within financial sectors, modern enterprises increasingly rely on Retrieval-Augmented Generation (RAG) systems to address complex compliance requirements in financial document workflows. However, existing solutions struggle to account for the inherent heterogeneity of data (e.g., text, tables, diagrams) and evolving nature of regulatory standards used in financial filings, leading to compromised accuracy in critical information extraction. We propose the FinSage framework as a solution, utilizing a multi-aspect RAG framework tailored for regulatory compliance analysis in multi-modal financial documents. FinSage introduces three innovative components: (1) a multi-modal pre-processing pipeline that unifies diverse data formats and generates chunk-level metadata summaries, (2) a multi-path sparse-dense retrieval system augmented with query expansion (HyDE) and metadata-aware semantic search, and (3) a domain-specialized re-ranking module fine-tuned via Direct Preference Optimization (DPO) to prioritize compliance-critical content. Extensive experiments demonstrate that FinSage achieves an impressive recall of 92.51% on 75 expert-curated questions derived from surpasses the best baseline method on the FinanceBench question answering datasets by 24.06% in accuracy. Moreover, FinSage has been successfully deployed as financial question-answering agent in online meetings, where it has already served more than 1,200 people.
AACC: Asymmetric Actor-Critic in Contextual Reinforcement Learning
Aug 03, 2022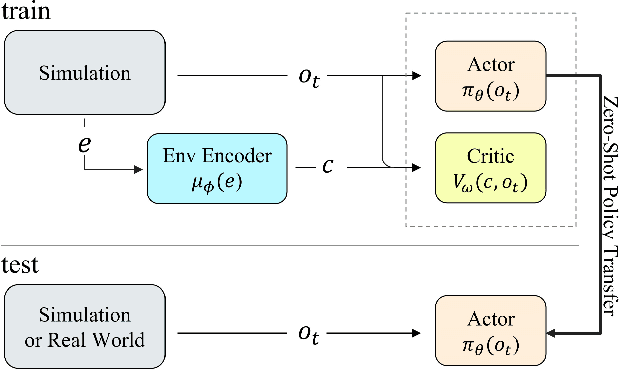

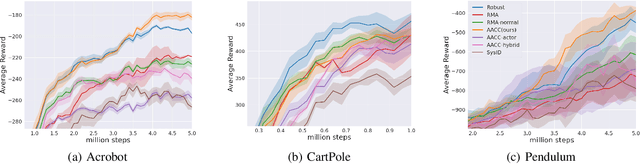

Reinforcement Learning (RL) techniques have drawn great attention in many challenging tasks, but their performance deteriorates dramatically when applied to real-world problems. Various methods, such as domain randomization, have been proposed to deal with such situations by training agents under different environmental setups, and therefore they can be generalized to different environments during deployment. However, they usually do not incorporate the underlying environmental factor information that the agents interact with properly and thus can be overly conservative when facing changes in the surroundings. In this paper, we first formalize the task of adapting to changing environmental dynamics in RL as a generalization problem using Contextual Markov Decision Processes (CMDPs). We then propose the Asymmetric Actor-Critic in Contextual RL (AACC) as an end-to-end actor-critic method to deal with such generalization tasks. We demonstrate the essential improvements in the performance of AACC over existing baselines experimentally in a range of simulated environments.