 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAACC: Asymmetric Actor-Critic in Contextual Reinforcement Learning
Paper and Code
Aug 03, 2022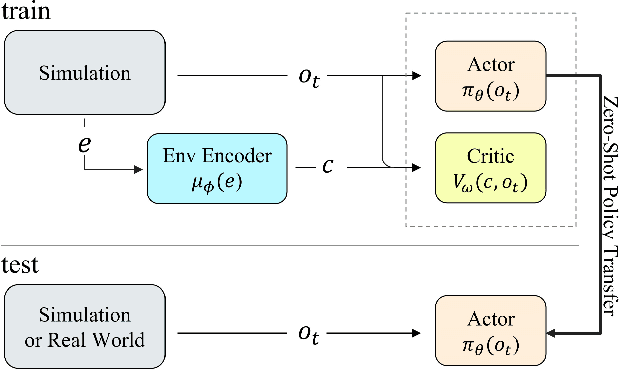

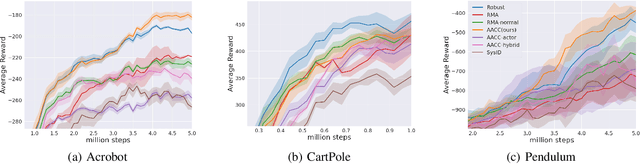

Reinforcement Learning (RL) techniques have drawn great attention in many challenging tasks, but their performance deteriorates dramatically when applied to real-world problems. Various methods, such as domain randomization, have been proposed to deal with such situations by training agents under different environmental setups, and therefore they can be generalized to different environments during deployment. However, they usually do not incorporate the underlying environmental factor information that the agents interact with properly and thus can be overly conservative when facing changes in the surroundings. In this paper, we first formalize the task of adapting to changing environmental dynamics in RL as a generalization problem using Contextual Markov Decision Processes (CMDPs). We then propose the Asymmetric Actor-Critic in Contextual RL (AACC) as an end-to-end actor-critic method to deal with such generalization tasks. We demonstrate the essential improvements in the performance of AACC over existing baselines experimentally in a range of simulated environments.