 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem Design of the Ultra Mobility Vehicle: A Driving, Balancing, and Jumping Bicycle Robot
Feb 25, 2026Trials cyclists and mountain bike riders can hop, jump, balance, and drive on one or both wheels. This versatility allows them to achieve speed and energy-efficiency on smooth terrain and agility over rough terrain. Inspired by these athletes, we present the design and control of a robotic platform, Ultra Mobility Vehicle (UMV), which combines a bicycle and a reaction mass to move dynamically with minimal actuated degrees of freedom. We employ a simulation-driven design optimization process to synthesize a spatial linkage topology with a focus on vertical jump height and momentum-based balancing on a single wheel contact. Using a constrained Reinforcement Learning (RL) framework, we demonstrate zero-shot transfer of diverse athletic behaviors, including track-stands, jumps, wheelies, rear wheel hopping, and front flips. This 23.5 kg robot is capable of high speeds (8 m/s) and jumping on and over large obstacles (1 m tall, or 130% of the robot's nominal height).
Reinforcement Learning for Reduced-order Models of Legged Robots
Oct 15, 2023



Model-based approaches for planning and control for bipedal locomotion have a long history of success. It can provide stability and safety guarantees while being effective in accomplishing many locomotion tasks. Model-free reinforcement learning, on the other hand, has gained much popularity in recent years due to computational advancements. It can achieve high performance in specific tasks, but it lacks physical interpretability and flexibility in re-purposing the policy for a different set of tasks. For instance, we can initially train a neural network (NN) policy using velocity commands as inputs. However, to handle new task commands like desired hand or footstep locations at a desired walking velocity, we must retrain a new NN policy. In this work, we attempt to bridge the gap between these two bodies of work on a bipedal platform. We formulate a model-based reinforcement learning problem to learn a reduced-order model (ROM) within a model predictive control (MPC). Results show a 49% improvement in viable task region size and a 21% reduction in motor torque cost. All videos and code are available at https://sites.google.com/view/ymchen/research/rl-for-roms.
Beyond Inverted Pendulums: Task-optimal Simple Models of Legged Locomotion
Jan 05, 2023Reduced-order models (ROM) are popular in online motion planning due to their simplicity. A good ROM captures the bulk of the full model's dynamics while remaining low dimension. However, planning within the reduced-order space unavoidably constrains the full model, and hence we sacrifice the full potential of the robot. In the community of legged locomotion, this has lead to a search for better model extensions, but many of these extensions require human intuition, and there has not existed a principled way of evaluating the model performance and discovering new models. In this work, we propose a model optimization algorithm that automatically synthesizes reduced-order models, optimal with respect to any user-specified cost function. To demonstrate our work, we optimized models for a bipedal robot Cassie. We show in hardware experiment that the optimal ROM is simple enough for real time planning application and that the real robot achieves higher performance by using the optimal ROM.
Angular Center of Mass for Humanoid Robots
Oct 14, 2022
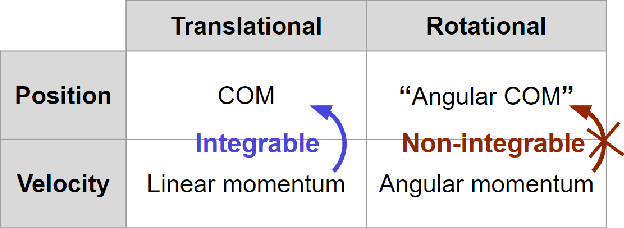
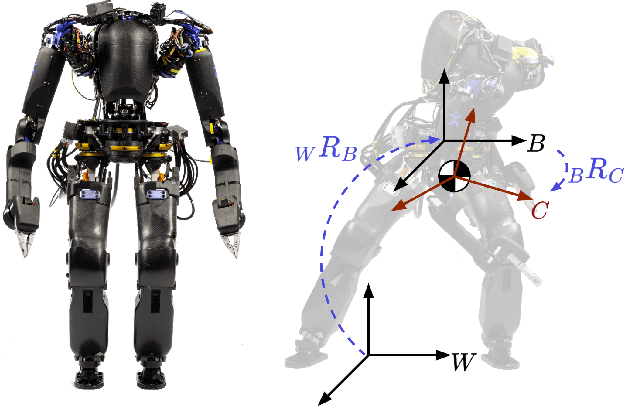
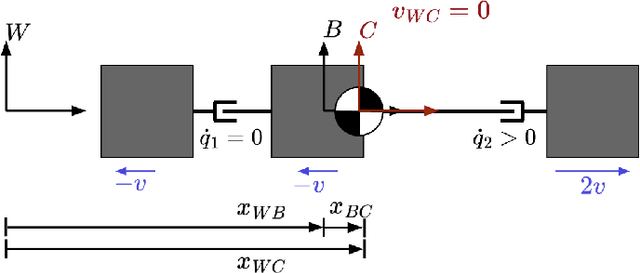
The center of mass (CoM) has been widely used in planning and control for humanoid locomotion, because it carries key information about the position of a robot. In contrast, an ''angular center of mass'' (ACoM), which provides an ''average'' orientation of a robot, is less well-known in the community, although the concept has been in the literature for about a decade. In this paper, we introduce the ACoM from a CoM perspective. We optimize for an ACoM on the humanoid robot Nadia, and demonstrate its application in walking with natural upper body motion on hardware.
Optimal Reduced-order Modeling of Bipedal Locomotion
Sep 23, 2019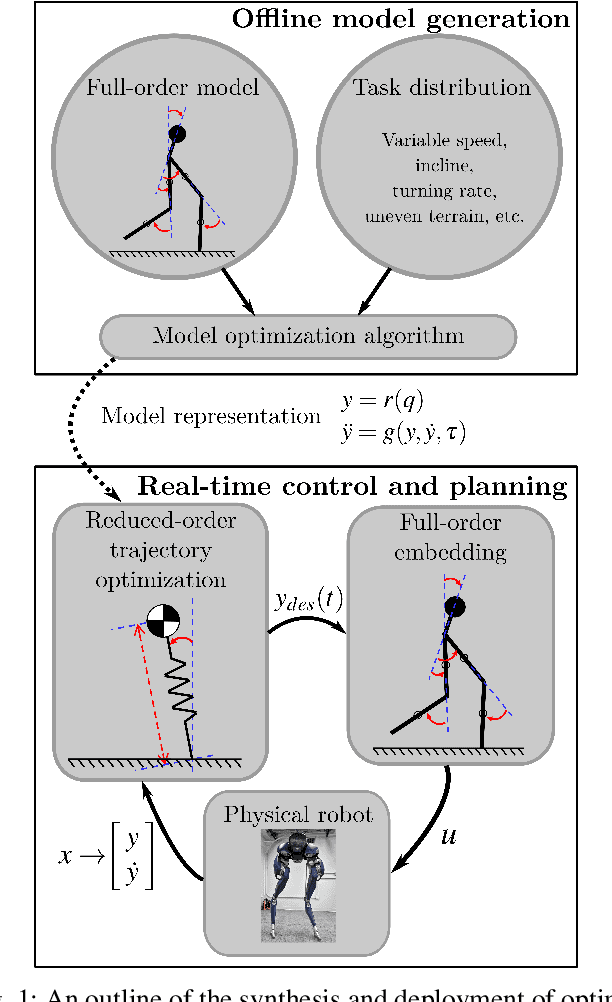
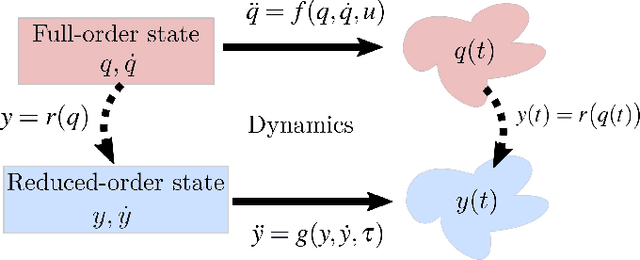
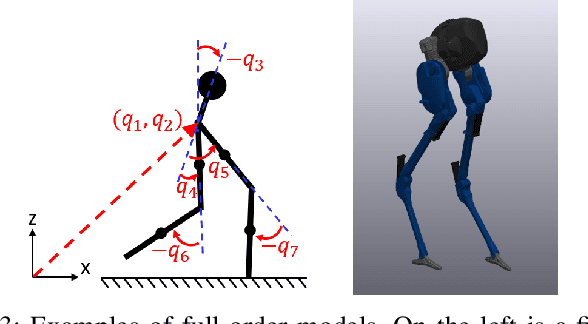
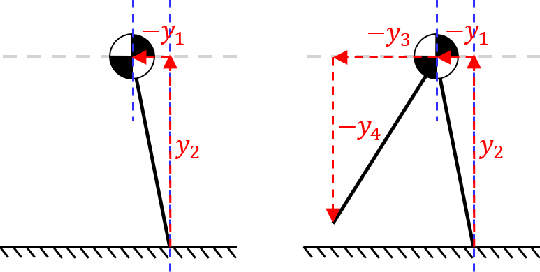
State-of-the-art approaches to legged locomotion are widely dependent on the use of models like the linear inverted pendulum (LIP) and the spring-loaded inverted pendulum (SLIP), popular because their simplicity enables a wide array of tools for planning, control, and analysis. However, they inevitably limit the ability to execute complex tasks or agile maneuvers. In this work, we aim to automatically synthesize models that remain low-dimensional but retain the capabilities of the high-dimensional system. For example, if one were to restore a small degree of complexity to LIP, SLIP, or a similar model, our approach discovers the form of that additional complexity which optimizes performance. In this paper, we define a class of reduced-order models and provide an algorithm for optimization within this class. To demonstrate our method, we optimize models for walking at a range of speeds and ground inclines, for both a five-link model and the Cassie bipedal robot.
Learning Stable and Energetically Economical Walking with RAMone
Nov 03, 2017
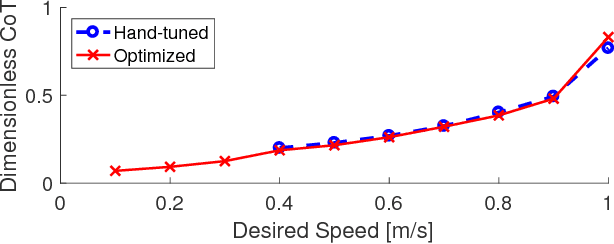
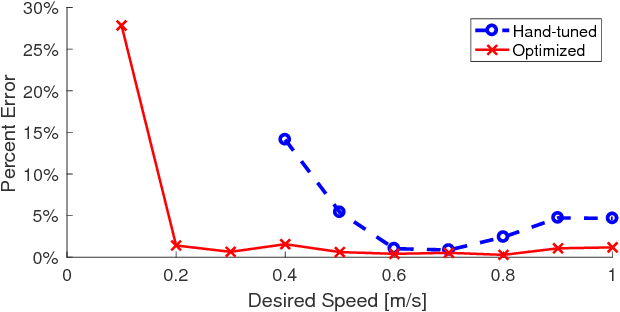
In this paper, we optimize over the control parameter space of our planar-bipedal robot, RAMone, for stable and energetically economical walking at various speeds. We formulate this task as an episodic reinforcement learning problem and use Covariance Matrix Adaptation. The parameters we are interested in modifying include gains from our Hybrid Zero Dynamics style controller and from RAMone's low-level motor controllers.