 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2-GNN: Graph Neural Networks for Graphs with Incomplete Features and Structure via Teacher-Student Distillation
Dec 24, 2022



Graph Neural Networks (GNNs) have been a prevailing technique for tackling various analysis tasks on graph data. A key premise for the remarkable performance of GNNs relies on complete and trustworthy initial graph descriptions (i.e., node features and graph structure), which is often not satisfied since real-world graphs are often incomplete due to various unavoidable factors. In particular, GNNs face greater challenges when both node features and graph structure are incomplete at the same time. The existing methods either focus on feature completion or structure completion. They usually rely on the matching relationship between features and structure, or employ joint learning of node representation and feature (or structure) completion in the hope of achieving mutual benefit. However, recent studies confirm that the mutual interference between features and structure leads to the degradation of GNN performance. When both features and structure are incomplete, the mismatch between features and structure caused by the missing randomness exacerbates the interference between the two, which may trigger incorrect completions that negatively affect node representation. To this end, in this paper we propose a general GNN framework based on teacher-student distillation to improve the performance of GNNs on incomplete graphs, namely T2-GNN. To avoid the interference between features and structure, we separately design feature-level and structure-level teacher models to provide targeted guidance for student model (base GNNs, such as GCN) through distillation. Then we design two personalized methods to obtain well-trained feature and structure teachers. To ensure that the knowledge of the teacher model is comprehensively and effectively distilled to the student model, we further propose a dual distillation mode to enable the student to acquire as much expert knowledge as possible.
From Easy to Hard: Two-stage Selector and Reader for Multi-hop Question Answering
May 24, 2022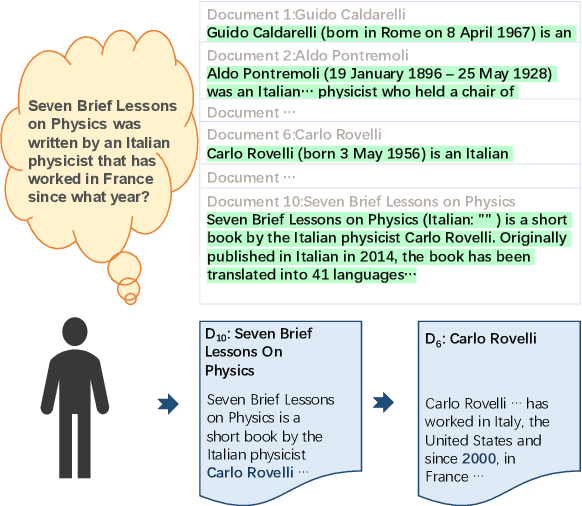
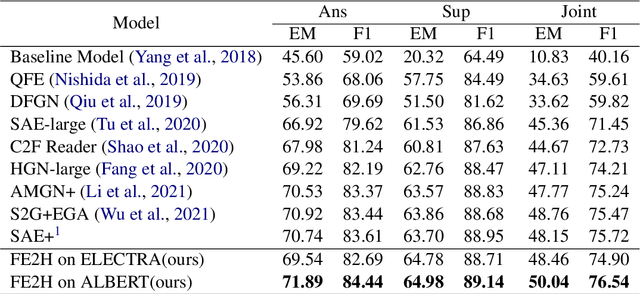
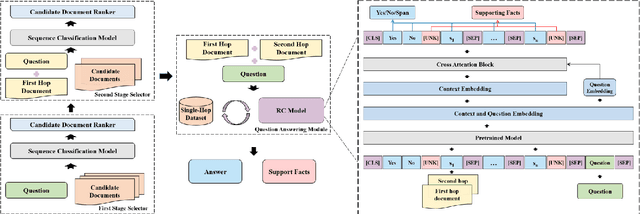
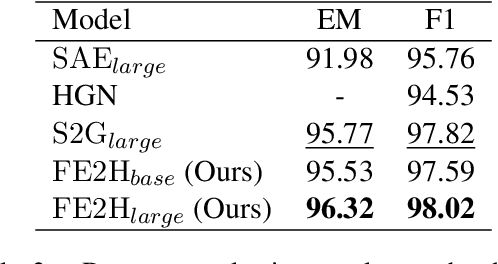
Multi-hop question answering (QA) is a challenging task requiring QA systems to perform complex reasoning over multiple documents and provide supporting facts together with the exact answer. Existing works tend to utilize graph-based reasoning and question decomposition to obtain the reasoning chain, which inevitably introduces additional complexity and cumulative error to the system. To address the above issue, we propose a simple yet effective novel framework, From Easy to Hard (FE2H), to remove distracting information and obtain better contextual representations for the multi-hop QA task. Inspired by the iterative document selection process and the progressive learning custom of humans, FE2H divides both the document selector and reader into two stages following an easy-to-hard manner. Specifically, we first select the document most relevant to the question and then utilize the question together with this document to select other pertinent documents. As for the QA phase, our reader is first trained on a single-hop QA dataset and then transferred into the multi-hop QA task. We comprehensively evaluate our model on the popular multi-hop QA benchmark HotpotQA. Experimental results demonstrate that our method ourperforms all other methods in the leaderboard of HotpotQA (distractor setting).
ResT V2: Simpler, Faster and Stronger
Apr 15, 2022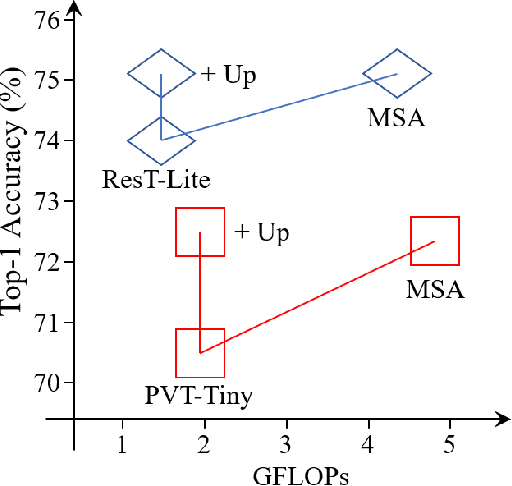
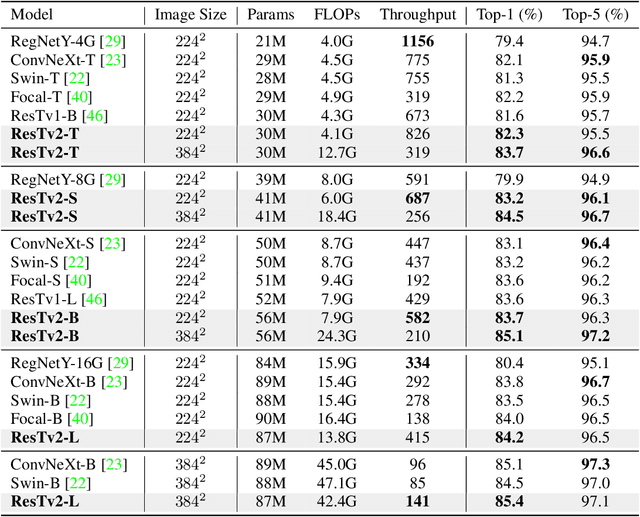
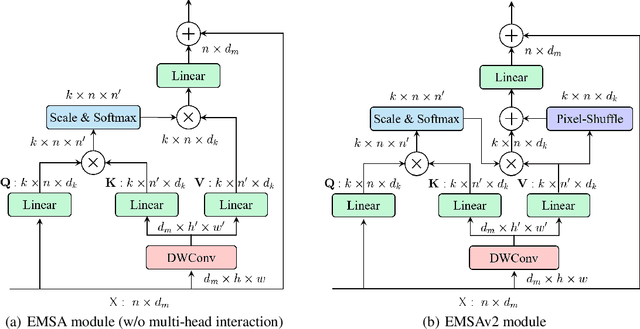

This paper proposes ResTv2, a simpler, faster, and stronger multi-scale vision Transformer for visual recognition. ResTv2 simplifies the EMSA structure in ResTv1 (i.e., eliminating the multi-head interaction part) and employs an upsample operation to reconstruct the lost medium- and high-frequency information caused by the downsampling operation. In addition, we explore different techniques for better apply ResTv2 backbones to downstream tasks. We found that although combining EMSAv2 and window attention can greatly reduce the theoretical matrix multiply FLOPs, it may significantly decrease the computation density, thus causing lower actual speed. We comprehensively validate ResTv2 on ImageNet classification, COCO detection, and ADE20K semantic segmentation. Experimental results show that the proposed ResTv2 can outperform the recently state-of-the-art backbones by a large margin, demonstrating the potential of ResTv2 as solid backbones. The code and models will be made publicly available at \url{https://github.com/wofmanaf/ResT}
Optimisation of Air-Ground Swarm Teaming for Target Search, using Differential Evolution
Sep 13, 2019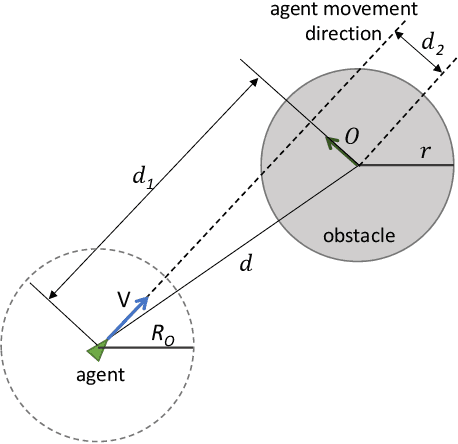
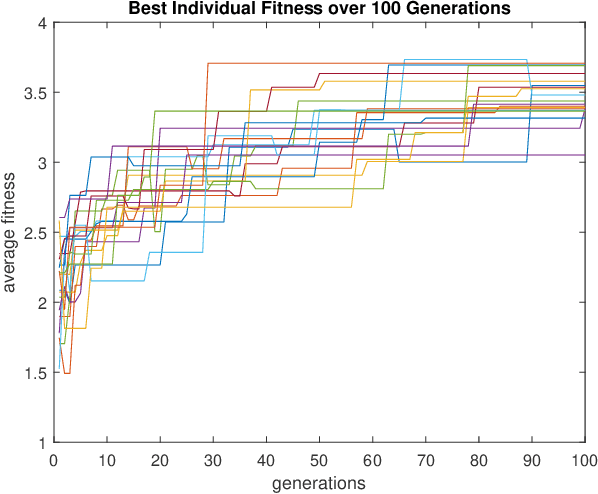
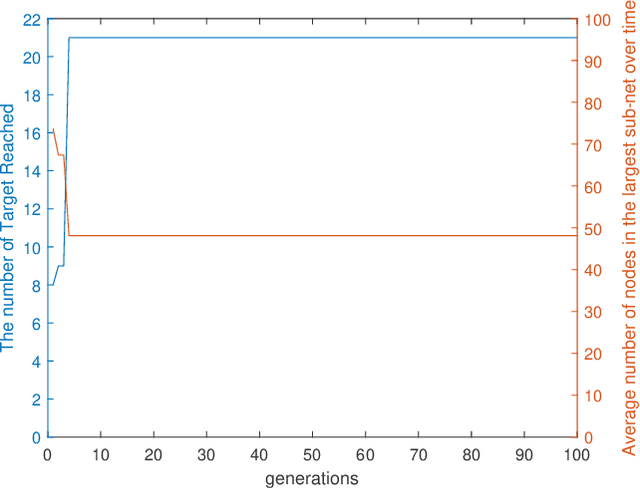
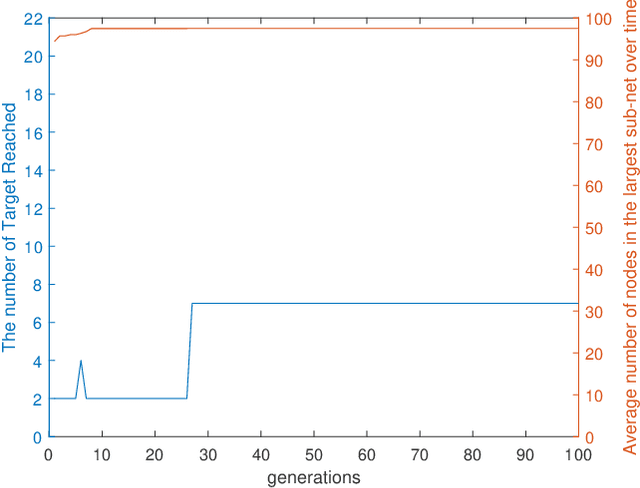
This paper presents a swarm teaming perspective that enhances the scope of classic investigations on survivable networks. A target searching generic context is considered as test-bed, in which a swarm of ground agents and a swarm of UAVs cooperate so that the ground agents reach as many targets as possible in the field while also remaining connected as much as possible at all times. To optimise the system against both these objectives in the same time, we use an evolutionary computation approach in the form of a differential evolution algorithm. Results are encouraging, showing a good evolution of the fitness function used as part of the differential evolution, and a good performance of the evolved dual-swarm system, which exhibits an optimal trade-off between target reaching and connectivity.
Learning Deep Representations Using Convolutional Auto-encoders with Symmetric Skip Connections
Mar 28, 2017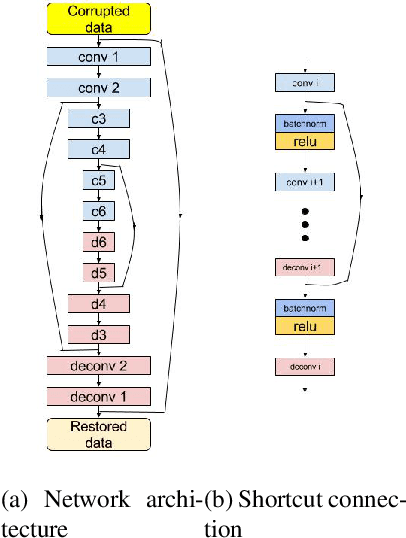
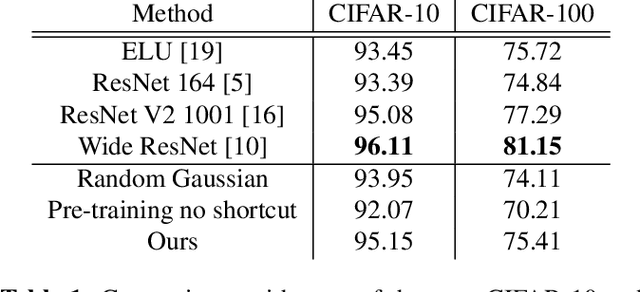
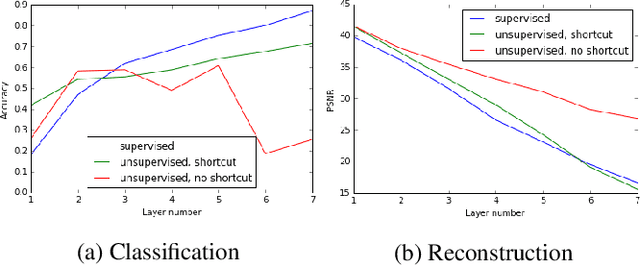
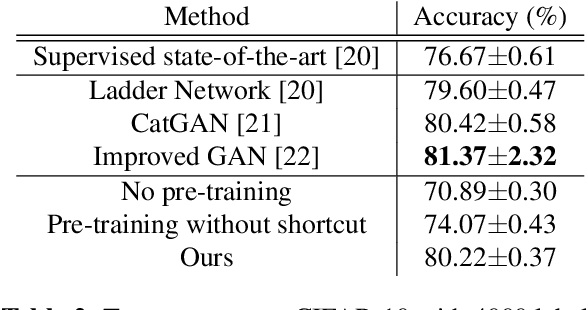
Unsupervised pre-training was a critical technique for training deep neural networks years ago. With sufficient labeled data and modern training techniques, it is possible to train very deep neural networks from scratch in a purely supervised manner nowadays. However, unlabeled data is easier to obtain and usually of very large scale. How to make use of them better to help supervised learning is still a well-valued topic. In this paper, we investigate convolutional denoising auto-encoders to show that unsupervised pre-training can still improve the performance of high-level image related tasks such as image classification and semantic segmentation. The architecture we use is a convolutional auto-encoder network with symmetric shortcut connections. We empirically show that symmetric shortcut connections are very important for learning abstract representations via image reconstruction. When no extra unlabeled data are available, unsupervised pre-training with our network can regularize the supervised training and therefore lead to better generalization performance. With the help of unsupervised pre-training, our method achieves very competitive results in image classification using very simple all-convolution networks. When labeled data are limited but extra unlabeled data are available, our method achieves good results in several semi-supervised learning tasks.
Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections
Sep 01, 2016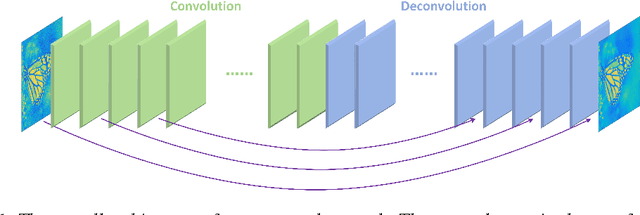
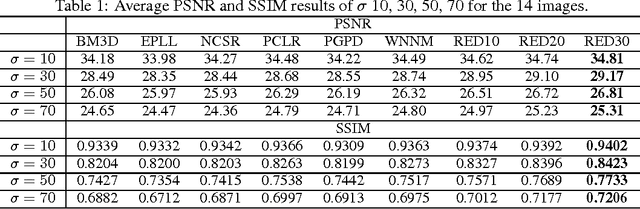
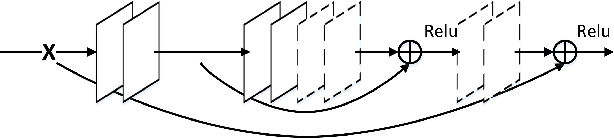
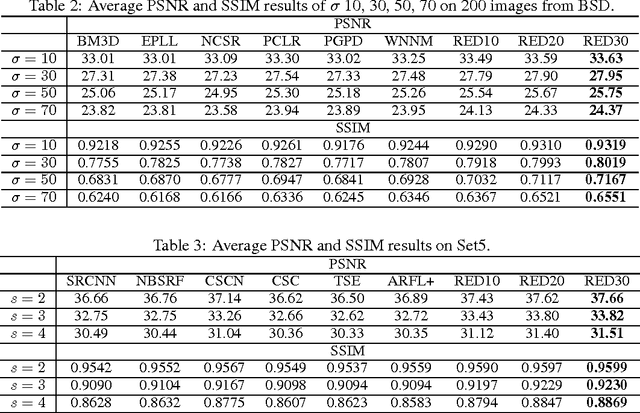
In this paper, we propose a very deep fully convolutional encoding-decoding framework for image restoration such as denoising and super-resolution. The network is composed of multiple layers of convolution and de-convolution operators, learning end-to-end mappings from corrupted images to the original ones. The convolutional layers act as the feature extractor, which capture the abstraction of image contents while eliminating noises/corruptions. De-convolutional layers are then used to recover the image details. We propose to symmetrically link convolutional and de-convolutional layers with skip-layer connections, with which the training converges much faster and attains a higher-quality local optimum. First, The skip connections allow the signal to be back-propagated to bottom layers directly, and thus tackles the problem of gradient vanishing, making training deep networks easier and achieving restoration performance gains consequently. Second, these skip connections pass image details from convolutional layers to de-convolutional layers, which is beneficial in recovering the original image. Significantly, with the large capacity, we can handle different levels of noises using a single model. Experimental results show that our network achieves better performance than all previously reported state-of-the-art methods.
Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections
Aug 30, 2016
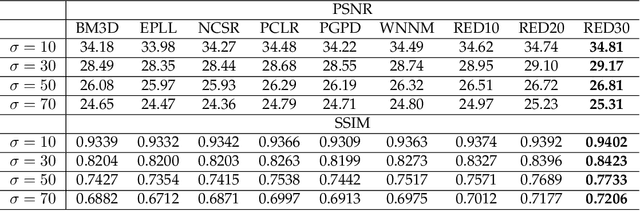

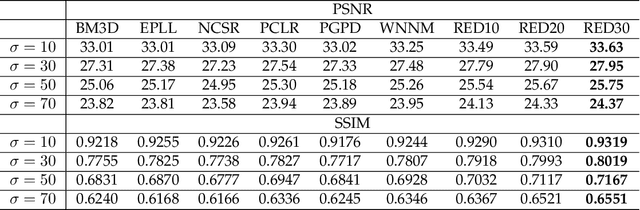
Image restoration, including image denoising, super resolution, inpainting, and so on, is a well-studied problem in computer vision and image processing, as well as a test bed for low-level image modeling algorithms. In this work, we propose a very deep fully convolutional auto-encoder network for image restoration, which is a encoding-decoding framework with symmetric convolutional-deconvolutional layers. In other words, the network is composed of multiple layers of convolution and de-convolution operators, learning end-to-end mappings from corrupted images to the original ones. The convolutional layers capture the abstraction of image contents while eliminating corruptions. Deconvolutional layers have the capability to upsample the feature maps and recover the image details. To deal with the problem that deeper networks tend to be more difficult to train, we propose to symmetrically link convolutional and deconvolutional layers with skip-layer connections, with which the training converges much faster and attains better results.