 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multi-Modal Multi-LiDAR-Inertial Odometry and Mapping for Indoor Environments
Mar 05, 2023



Integrating multiple LiDAR sensors can significantly enhance a robot's perception of the environment, enabling it to capture adequate measurements for simultaneous localization and mapping (SLAM). Indeed, solid-state LiDARs can bring in high resolution at a low cost to traditional spinning LiDARs in robotic applications. However, their reduced field of view (FoV) limits performance, particularly indoors. In this paper, we propose a tightly-coupled multi-modal multi-LiDAR-inertial SLAM system for surveying and mapping tasks. By taking advantage of both solid-state and spinnings LiDARs, and built-in inertial measurement units (IMU), we achieve both robust and low-drift ego-estimation as well as high-resolution maps in diverse challenging indoor environments (e.g., small, featureless rooms). First, we use spatial-temporal calibration modules to align the timestamp and calibrate extrinsic parameters between sensors. Then, we extract two groups of feature points including edge and plane points, from LiDAR data. Next, with pre-integrated IMU data, an undistortion module is applied to the LiDAR point cloud data. Finally, the undistorted point clouds are merged into one point cloud and processed with a sliding window based optimization module. From extensive experiment results, our method shows competitive performance with state-of-the-art spinning-LiDAR-only or solid-state-LiDAR-only SLAM systems in diverse environments. More results, code, and dataset can be found at \href{https://github.com/TIERS/multi-modal-loam}{https://github.com/TIERS/multi-modal-loam}.
A Benchmark for Multi-Modal Lidar SLAM with Ground Truth in GNSS-Denied Environments
Oct 03, 2022


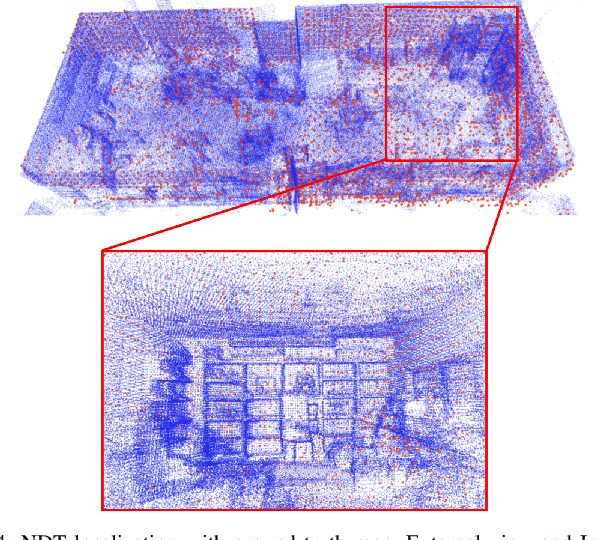
Lidar-based simultaneous localization and mapping (SLAM) approaches have obtained considerable success in autonomous robotic systems. This is in part owing to the high-accuracy of robust SLAM algorithms and the emergence of new and lower-cost lidar products. This study benchmarks current state-of-the-art lidar SLAM algorithms with a multi-modal lidar sensor setup showcasing diverse scanning modalities (spinning and solid-state) and sensing technologies, and lidar cameras, mounted on a mobile sensing and computing platform. We extend our previous multi-modal multi-lidar dataset with additional sequences and new sources of ground truth data. Specifically, we propose a new multi-modal multi-lidar SLAM-assisted and ICP-based sensor fusion method for generating ground truth maps. With these maps, we then match real-time pointcloud data using a natural distribution transform (NDT) method to obtain the ground truth with full 6 DOF pose estimation. This novel ground truth data leverages high-resolution spinning and solid-state lidars. We also include new open road sequences with GNSS-RTK data and additional indoor sequences with motion capture (MOCAP) ground truth, complementing the previous forest sequences with MOCAP data. We perform an analysis of the positioning accuracy achieved with ten different SLAM algorithm and lidar combinations. We also report the resource utilization in four different computational platforms and a total of five settings (Intel and Jetson ARM CPUs). Our experimental results show that current state-of-the-art lidar SLAM algorithms perform very differently for different types of sensors. More results, code, and the dataset can be found at: \href{https://github.com/TIERS/tiers-lidars-dataset-enhanced}{github.com/TIERS/tiers-lidars-dataset-enhanced.
Analyzing General-Purpose Deep-Learning Detection and Segmentation Models with Images from a Lidar as a Camera Sensor
Mar 08, 2022


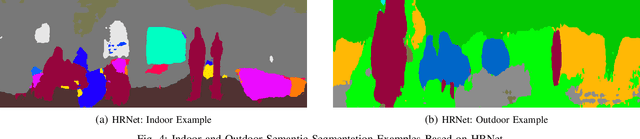
Over the last decade, robotic perception algorithms have significantly benefited from the rapid advances in deep learning (DL). Indeed, a significant amount of the autonomy stack of different commercial and research platforms relies on DL for situational awareness, especially vision sensors. This work explores the potential of general-purpose DL perception algorithms, specifically detection and segmentation neural networks, for processing image-like outputs of advanced lidar sensors. Rather than processing the three-dimensional point cloud data, this is, to the best of our knowledge, the first work to focus on low-resolution images with 360\textdegree field of view obtained with lidar sensors by encoding either depth, reflectivity, or near-infrared light in the image pixels. We show that with adequate preprocessing, general-purpose DL models can process these images, opening the door to their usage in environmental conditions where vision sensors present inherent limitations. We provide both a qualitative and quantitative analysis of the performance of a variety of neural network architectures. We believe that using DL models built for visual cameras offers significant advantages due to the much wider availability and maturity compared to point cloud-based perception.
An Overview of Federated Learning at the Edge and Distributed Ledger Technologies for Robotic and Autonomous Systems
Apr 21, 2021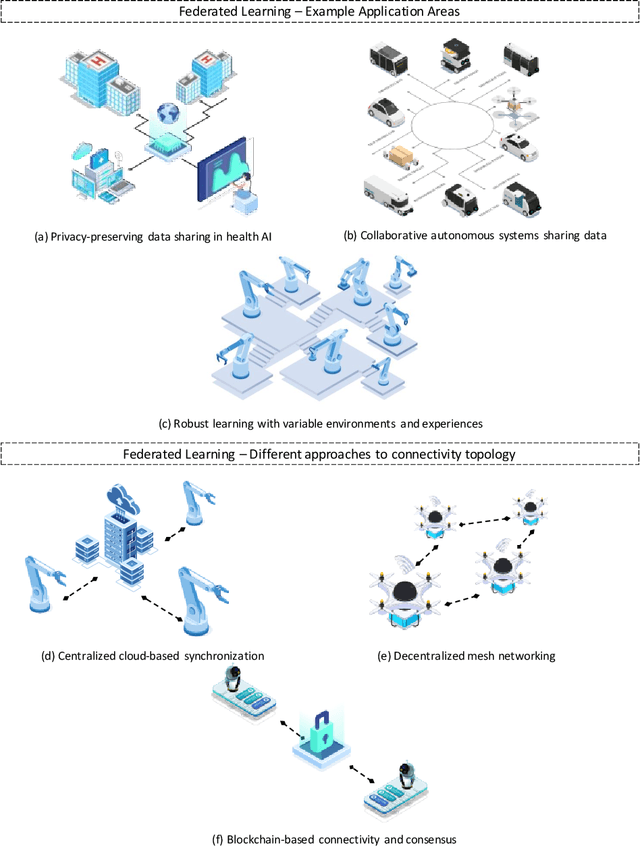
Autonomous systems are becoming inherently ubiquitous with the advancements of computing and communication solutions enabling low-latency offloading and real-time collaboration of distributed devices. Decentralized technologies with blockchain and distributed ledger technologies (DLTs) are playing a key role. At the same time, advances in deep learning (DL) have significantly raised the degree of autonomy and level of intelligence of robotic and autonomous systems. While these technological revolutions were taking place, raising concerns in terms of data security and end-user privacy has become an inescapable research consideration. Federated learning (FL) is a promising solution to privacy-preserving DL at the edge, with an inherently distributed nature by learning on isolated data islands and communicating only model updates. However, FL by itself does not provide the levels of security and robustness required by today's standards in distributed autonomous systems. This survey covers applications of FL to autonomous robots, analyzes the role of DLT and FL for these systems, and introduces the key background concepts and considerations in current research.
Cooperative UWB-Based Localization for Outdoors Positioning and Navigation of UAVs aided by Ground Robots
Apr 01, 2021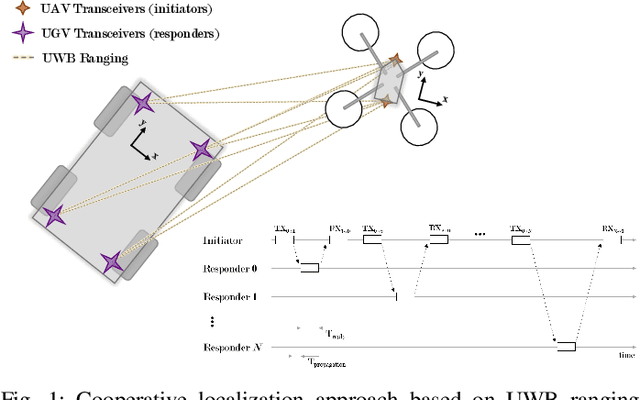
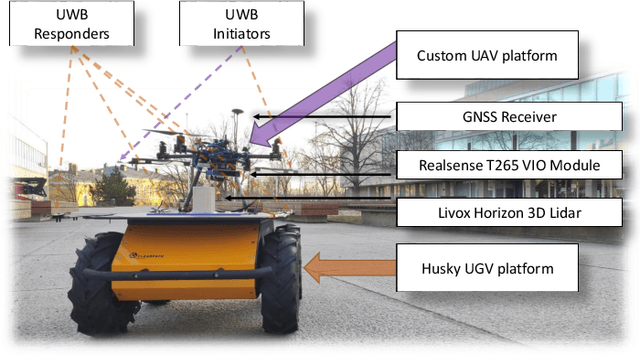
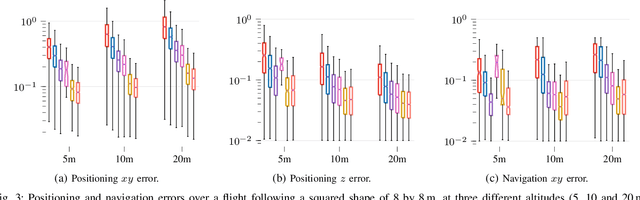

Unmanned aerial vehicles (UAVs) are becoming largely ubiquitous with an increasing demand for aerial data. Accurate navigation and localization, required for precise data collection in many industrial applications, often relies on RTK GNSS. These systems, able of centimeter-level accuracy, require a setup and calibration process and are relatively expensive. This paper addresses the problem of accurate positioning and navigation of UAVs through cooperative localization. Inexpensive ultra-wideband (UWB) transceivers installed on both the UAV and a support ground robot enable centimeter-level relative positioning. With fast deployment and wide setup flexibility, the proposed system is able to accommodate different environments and can also be utilized in GNSS-denied environments. Through extensive simulations and test fields, we evaluate the accuracy of the system and compare it to GNSS in urban environments where multipath transmission degrades accuracy. For completeness, we include visual-inertial odometry in the experiments and compare the performance with the UWB-based cooperative localization.
Adaptive Lidar Scan Frame Integration: Tracking Known MAVs in 3D Point Clouds
Mar 06, 2021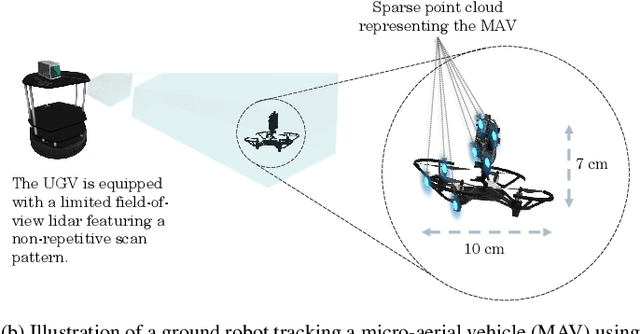
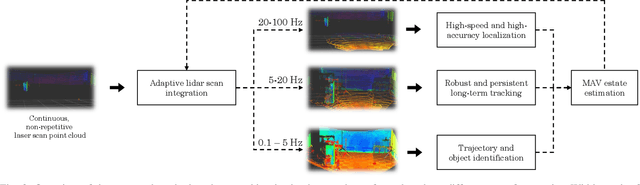


Micro-aerial vehicles (MAVs) are becoming ubiquitous across multiple industries and application domains. Lightweight MAVs with only an onboard flight controller and a minimal sensor suite (e.g., IMU, vision, and vertical ranging sensors) have potential as mobile and easily deployable sensing platforms. When deployed from a ground robot, a key parameter is a relative localization between the ground robot and the MAV. This paper proposes a novel method for tracking MAVs in lidar point clouds. In lidar point clouds, we consider the speed and distance of the MAV to actively adapt the lidar's frame integration time and, in essence, the density and size of the point cloud to be processed. We show that this method enables more persistent and robust tracking when the speed of the MAV or its distance to the tracking sensor changes. In addition, we propose a multi-modal tracking method that relies on high-frequency scans for accurate state estimation, lower-frequency scans for robust and persistent tracking, and sub-Hz processing for trajectory and object identification. These three integration and processing modalities allow for an overall accurate and robust MAV tracking while ensuring the object being tracked meets shape and size constraints.