 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsect-Computer Hybrid Speaker: Speaker using Chirp of the Cicada Controlled by Electrical Muscle Stimulation
Apr 23, 2025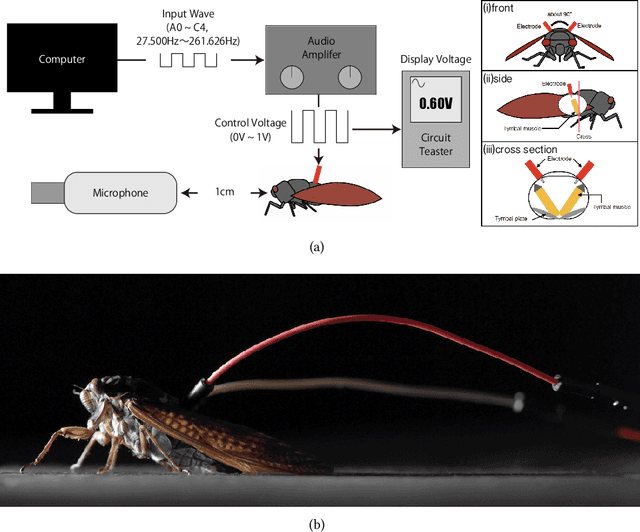

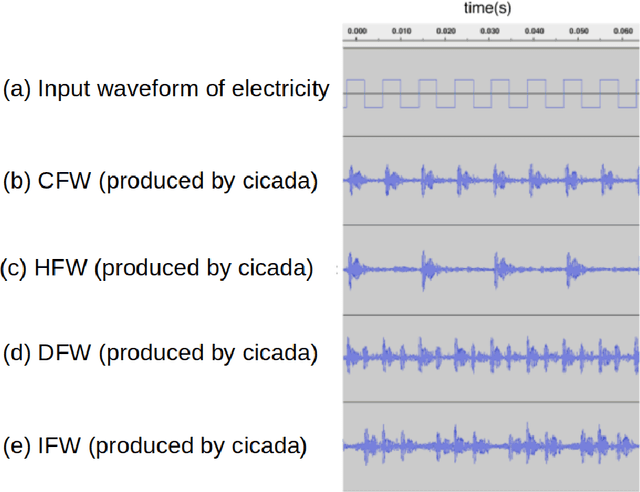
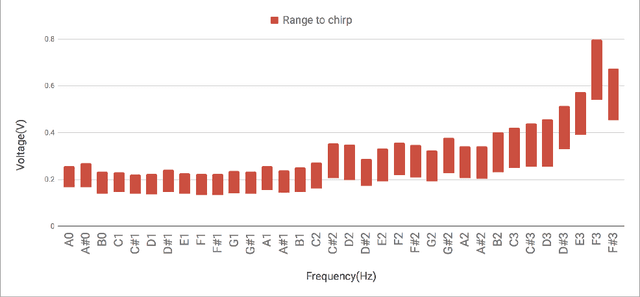
We propose "Insect-Computer Hybrid Speaker", which enables us to make musics made from combinations of computer and insects. Lots of studies have proposed methods and interfaces for controlling insects and obtaining feedback. However, there have been less research on the use of insects for interaction with third parties. In this paper, we propose a method in which cicadas are used as speakers triggered by using Electrical Muscle Stimulation (EMS). We explored and investigated the suitable waveform of chirp to be controlled, the appropriate voltage range, and the maximum pitch at which cicadas can chirp.
Generative Artificial Intelligence-Guided User Studies: An Application for Air Taxi Services
Jun 18, 2024



User studies are crucial for meeting user needs. In user studies, real experimental scenarios and participants are constructed and recruited. However, emerging and unfamiliar studies face limitations, including safety concerns and iterative efficiency. To address these challenges, this study utilizes a large language model (LLM) to create generative AI virtual scenarios for user experience. By recruiting real users to evaluate this experience, we can collect feedback that enables rapid iteration in the early design phase. The air taxi is particularly representative of these challenges and has been chosen as the case study for this research. The key contribution was designing a virtual ATJ using OpenAI's GPT-4 model and AI image and video generators. Based on the LLM-generated scripts, key visuals were created for the air taxi, and the ATJ was evaluated by 72 participants. Furthermore, the LLM demonstrated the ability to identify and suggest environments that significantly improve participants' attitudes toward air taxis. Education level and gender significantly influenced participants' attitudes and their satisfaction with the ATJ. Our study confirms the capability of generative AI to support user studies, providing a feasible approach and valuable insights for designing air taxi user experiences in the early design phase.
Expanding Horizons in HCI Research Through LLM-Driven Qualitative Analysis
Jan 07, 2024How would research be like if we still needed to "send" papers typed with a typewriter? Our life and research environment have continually evolved, often accompanied by controversial opinions about new methodologies. In this paper, we embrace this change by introducing a new approach to qualitative analysis in HCI using Large Language Models (LLMs). We detail a method that uses LLMs for qualitative data analysis and present a quantitative framework using SBART cosine similarity for performance evaluation. Our findings indicate that LLMs not only match the efficacy of traditional analysis methods but also offer unique insights. Through a novel dataset and benchmark, we explore LLMs' characteristics in HCI research, suggesting potential avenues for further exploration and application in the field.
Dance Generation by Sound Symbolic Words
Jun 06, 2023



This study introduces a novel approach to generate dance motions using onomatopoeia as input, with the aim of enhancing creativity and diversity in dance generation. Unlike text and music, onomatopoeia conveys rhythm and meaning through abstract word expressions without constraints on expression and without need for specialized knowledge. We adapt the AI Choreographer framework and employ the Sakamoto system, a feature extraction method for onomatopoeia focusing on phonemes and syllables. Additionally, we present a new dataset of 40 onomatopoeia-dance motion pairs collected through a user survey. Our results demonstrate that the proposed method enables more intuitive dance generation and can create dance motions using sound-symbolic words from a variety of languages, including those without onomatopoeia. This highlights the potential for diverse dance creation across different languages and cultures, accessible to a wider audience. Qualitative samples from our model can be found at: https://sites.google.com/view/onomatopoeia-dance/home/.
VaxNeRF: Revisiting the Classic for Voxel-Accelerated Neural Radiance Field
Nov 25, 2021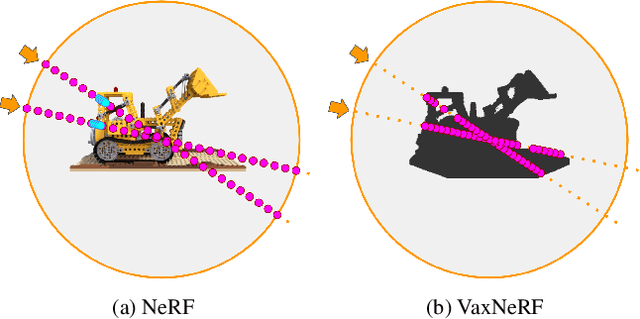
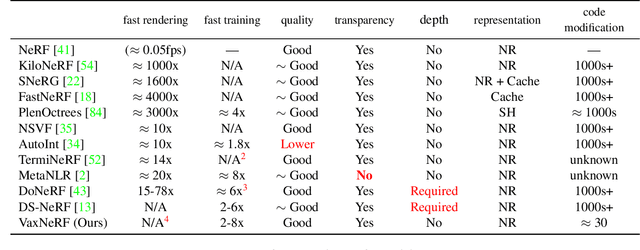

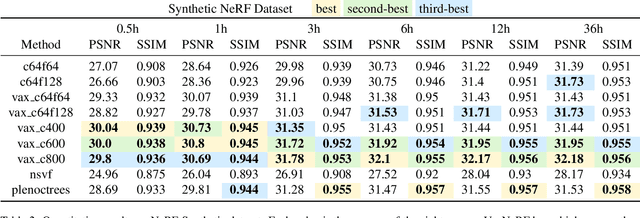
Neural Radiance Field (NeRF) is a popular method in data-driven 3D reconstruction. Given its simplicity and high quality rendering, many NeRF applications are being developed. However, NeRF's big limitation is its slow speed. Many attempts are made to speeding up NeRF training and inference, including intricate code-level optimization and caching, use of sophisticated data structures, and amortization through multi-task and meta learning. In this work, we revisit the basic building blocks of NeRF through the lens of classic techniques before NeRF. We propose Voxel-Accelearated NeRF (VaxNeRF), integrating NeRF with visual hull, a classic 3D reconstruction technique only requiring binary foreground-background pixel labels per image. Visual hull, which can be optimized in about 10 seconds, can provide coarse in-out field separation to omit substantial amounts of network evaluations in NeRF. We provide a clean fully-pythonic, JAX-based implementation on the popular JaxNeRF codebase, consisting of only about 30 lines of code changes and a modular visual hull subroutine, and achieve about 2-8x faster learning on top of the highly-performative JaxNeRF baseline with zero degradation in rendering quality. With sufficient compute, this effectively brings down full NeRF training from hours to 30 minutes. We hope VaxNeRF -- a careful combination of a classic technique with a deep method (that arguably replaced it) -- can empower and accelerate new NeRF extensions and applications, with its simplicity, portability, and reliable performance gains. Codes are available at https://github.com/naruya/VaxNeRF .
A Preliminary Study for Identification of Additive Manufactured Objects with Transmitted Images
May 25, 2020



Additive manufacturing has the potential to become a standard method for manufacturing products, and product information is indispensable for the item distribution system. While most products are given barcodes to the exterior surfaces, research on embedding barcodes inside products is underway. This is because additive manufacturing makes it possible to carry out manufacturing and information adding at the same time, and embedding information inside does not impair the exterior appearance of the product. However, products that have not been embedded information can not be identified, and embedded information can not be rewritten later. In this study, we have developed a product identification system that does not require embedding barcodes inside. This system uses a transmission image of the product which contains information of each product such as different inner support structures and manufacturing errors. We have shown through experiments that if datasets of transmission images are available, objects can be identified with an accuracy of over 90%. This result suggests that our approach can be useful for identifying objects without embedded information.