 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Testing for LLM Applications: Characteristics, Challenges, and a Lightweight Interaction Protocol
Aug 28, 2025Applications of Large Language Models~(LLMs) have evolved from simple text generators into complex software systems that integrate retrieval augmentation, tool invocation, and multi-turn interactions. Their inherent non-determinism, dynamism, and context dependence pose fundamental challenges for quality assurance. This paper decomposes LLM applications into a three-layer architecture: \textbf{\textit{System Shell Layer}}, \textbf{\textit{Prompt Orchestration Layer}}, and \textbf{\textit{LLM Inference Core}}. We then assess the applicability of traditional software testing methods in each layer: directly applicable at the shell layer, requiring semantic reinterpretation at the orchestration layer, and necessitating paradigm shifts at the inference core. A comparative analysis of Testing AI methods from the software engineering community and safety analysis techniques from the AI community reveals structural disconnects in testing unit abstraction, evaluation metrics, and lifecycle management. We identify four fundamental differences that underlie 6 core challenges. To address these, we propose four types of collaborative strategies (\emph{Retain}, \emph{Translate}, \emph{Integrate}, and \emph{Runtime}) and explore a closed-loop, trustworthy quality assurance framework that combines pre-deployment validation with runtime monitoring. Based on these strategies, we offer practical guidance and a protocol proposal to support the standardization and tooling of LLM application testing. We propose a protocol \textbf{\textit{Agent Interaction Communication Language}} (AICL) that is used to communicate between AI agents. AICL has the test-oriented features and is easily integrated in the current agent framework.
Single-shot Phase Retrieval from a Fractional Fourier Transform Perspective
Nov 18, 2023



The realm of classical phase retrieval concerns itself with the arduous task of recovering a signal from its Fourier magnitude measurements, which are fraught with inherent ambiguities. A single-exposure intensity measurement is commonly deemed insufficient for the reconstruction of the primal signal, given that the absent phase component is imperative for the inverse transformation. In this work, we present a novel single-shot phase retrieval paradigm from a fractional Fourier transform (FrFT) perspective, which involves integrating the FrFT-based physical measurement model within a self-supervised reconstruction scheme. Specifically, the proposed FrFT-based measurement model addresses the aliasing artifacts problem in the numerical calculation of Fresnel diffraction, featuring adaptability to both short-distance and long-distance propagation scenarios. Moreover, the intensity measurement in the FrFT domain proves highly effective in alleviating the ambiguities of phase retrieval and relaxing the previous conditions on oversampled or multiple measurements in the Fourier domain. Furthermore, the proposed self-supervised reconstruction approach harnesses the fast discrete algorithm of FrFT alongside untrained neural network priors, thereby attaining preeminent results. Through numerical simulations, we demonstrate that both amplitude and phase objects can be effectively retrieved from a single-shot intensity measurement using the proposed approach and provide a promising technique for support-free coherent diffraction imaging.
Dynamic Proximal Unrolling Network for Compressive Sensing Imaging
Jul 23, 2021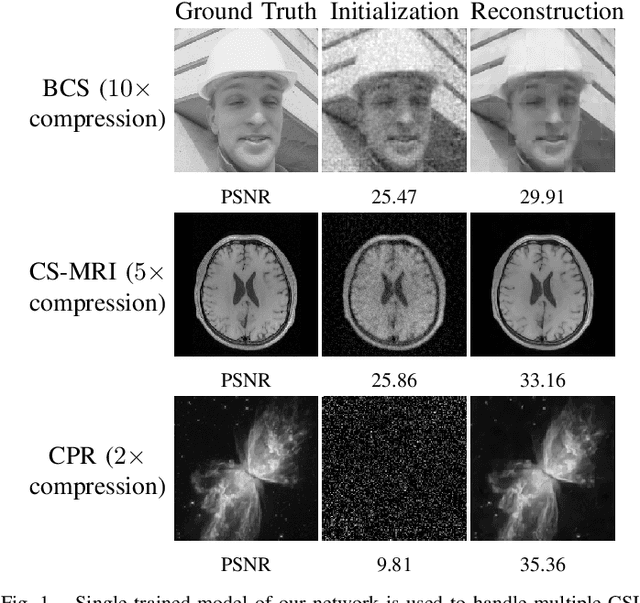
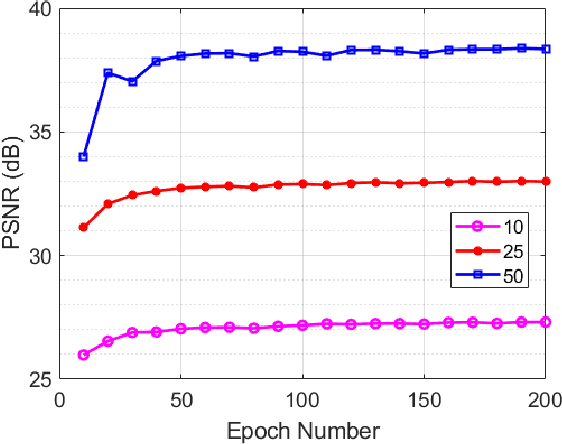
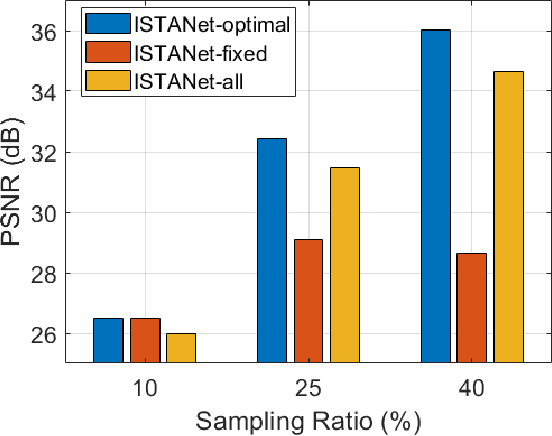
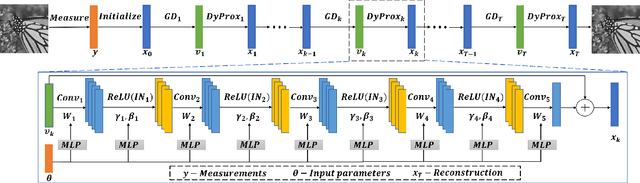
Recovering an underlying image from under-sampled measurements, Compressive Sensing Imaging (CSI) is a challenging problem and has many practical applications. Recently, deep neural networks have been applied to this problem with promising results, owing to its implicitly learned prior to alleviate the ill-poseness of CSI. However, existing neural network approaches require separate models for each imaging parameter like sampling ratios, leading to training difficulties and overfitting to specific settings. In this paper, we present a dynamic proximal unrolling network (dubbed DPUNet), which can handle a variety of measurement matrices via one single model without retraining. Specifically, DPUNet can exploit both embedded physical model via gradient descent and imposing image prior with learned dynamic proximal mapping leading to joint reconstruction. A key component of DPUNet is a dynamic proximal mapping module, whose parameters can be dynamically adjusted at inference stage and make it adapt to any given imaging setting. Experimental results demonstrate that the proposed DPUNet can effectively handle multiple CSI modalities under varying sampling ratios and noise levels with only one model, and outperform the state-of-the-art approaches.
Integrating Circle Kernels into Convolutional Neural Networks
Jul 07, 2021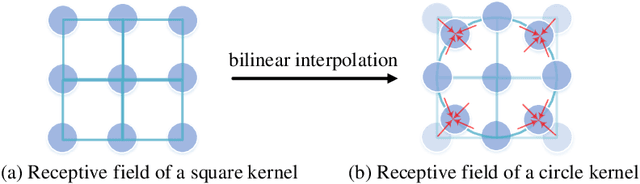
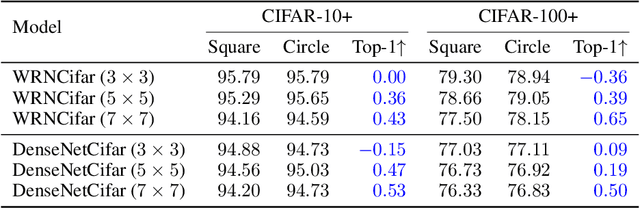
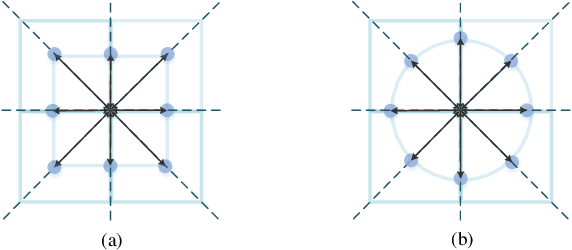
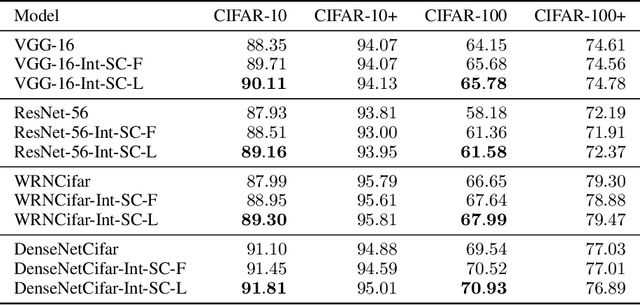
The square kernel is a standard unit for contemporary Convolutional Neural Networks (CNNs), as it fits well on the tensor computation for the convolution operation. However, the receptive field in the human visual system is actually isotropic like a circle. Motivated by this observation, we propose using circle kernels with isotropic receptive fields for the convolution, and our training takes approximately equivalent amount of calculation when compared with the corresponding CNN with square kernels. Our preliminary experiments demonstrate the rationality of circle kernels. We then propose a kernel boosting strategy that integrates the circle kernels with square kernels for the training and inference, and we further let the kernel size/radius be learnable during the training. Note that we reparameterize the circle kernels or integrated kernels before the inference, thus taking no extra computation as well as the number of parameter overhead for the testing. Extensive experiments on several standard datasets, ImageNet, CIFAR-10 and CIFAR-100, using the circle kernels or integrated kernels on typical existing CNNs, show that our approach exhibits highly competitive performance. Specifically, on ImageNet with standard data augmentation, our approach dramatically boosts the performance of MobileNetV3-Small by 5.20% top-1 accuracy and 3.39% top-5 accuracy, and boosts the performance of MobileNetV3-Large by 2.16% top-1 accuracy and 1.18% top-5 accuracy.
Single Image Reflection Removal through Cascaded Refinement
Nov 15, 2019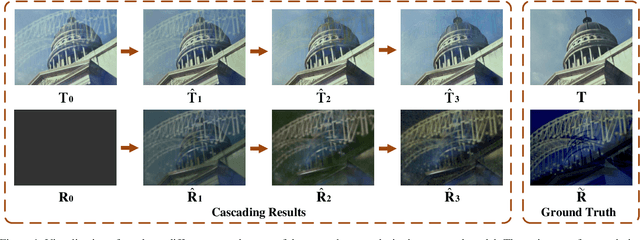
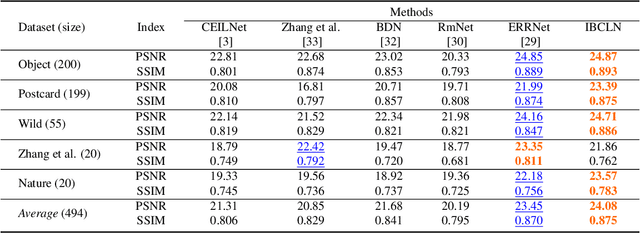
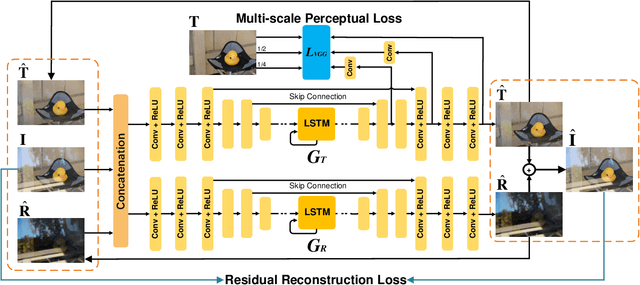
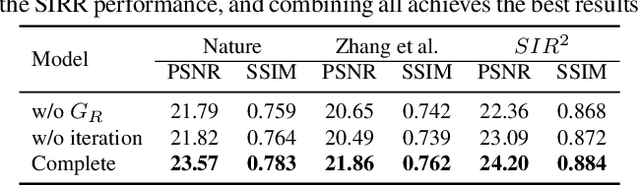
We address the problem of removing undesirable reflections from a single image captured through a glass surface, which is an ill-posed, challenging but practically important problem for photo enhancement. Inspired by iterative structure reduction for hidden community detection in social networks, we propose an Iterative Boost Convolutional LSTM Network (IBCLN) that enables cascaded prediction for reflection removal. IBCLN iteratively refines estimates of the transmission and reflection layers at each step in a manner that they can boost the prediction quality for each other. The intuition is that progressive refinement of the transmission or reflection layer is aided by increasingly better estimates of these quantities as input, and that transmission and reflection are complementary to each other in a single image and thus provide helpful auxiliary information for each other's prediction. To facilitate training over multiple cascade steps, we employ LSTM to address the vanishing gradient problem, and incorporate a reconstruction loss as further training guidance at each step. In addition, we create a dataset of real-world images with reflection and ground-truth transmission layers to mitigate the problem of insufficient data. Through comprehensive experiments, IBCLN demonstrates performance that surpasses state-of-the-art reflection removal methods.