 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniSch: A Multimodal PCB Schematic Benchmark For Structured Diagram Visual Reasoning
Mar 31, 2026Recent large multimodal models (LMMs) have made rapid progress in visual grounding, document understanding, and diagram reasoning tasks. However, their ability to convert Printed Circuit Board (PCB) schematic diagrams into machine-readable spatially weighted netlist graphs, jointly capturing component attributes, connectivity, and geometry, remains largely underexplored, despite such graph representations are the backbone of practical electronic design automation (EDA) workflows. To bridge this gap, we introduce OmniSch, the first comprehensive benchmark designed to assess LMMs on schematic understanding and spatial netlist graph construction. OmniSch contains 1,854 real-world schematic diagrams and includes four tasks: (1) visual grounding for schematic entities, with 109.9K grounded instances aligning 423.4K diagram semantic labels to their visual regions; (2) diagram-to-graph reasoning, understanding topological relationship among diagram elements; (3) geometric reasoning, constructing layout-dependent weights for each connection; and (4) tool-augmented agentic reasoning for visual search, invoking external tools to accomplish (1)-(3). Our results reveal substantial gaps of current LMMs in interpreting schematic engineering artifacts, including unreliable fine-grained grounding, brittle layout-to-graph parsing, inconsistent global connectivity reasoning and inefficient visual exploration.
Learning to Advertise with Adaptive Exposure via Constrained Two-Level Reinforcement Learning
Sep 10, 2018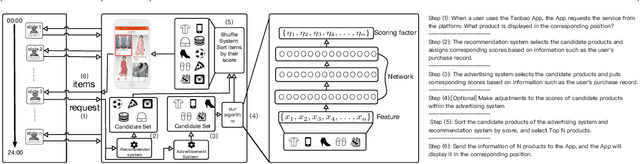
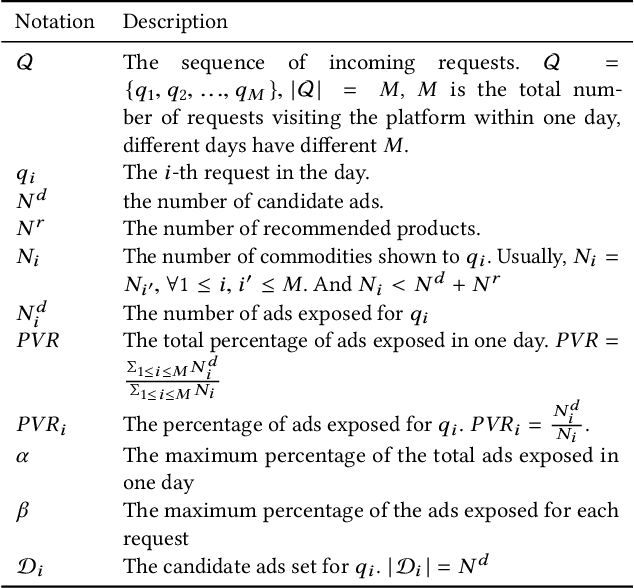
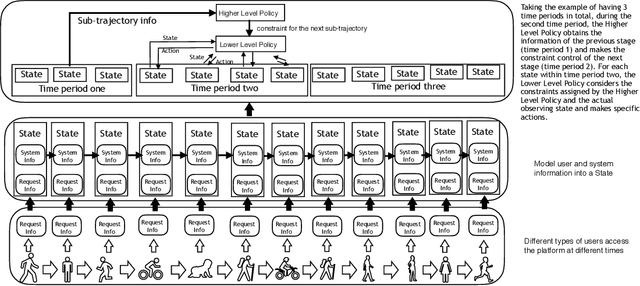

For online advertising in e-commerce, the traditional problem is to assign the right ad to the right user on fixed ad slots. In this paper, we investigate the problem of advertising with adaptive exposure, in which the number of ad slots and their locations can dynamically change over time based on their relative scores with recommendation products. In order to maintain user retention and long-term revenue, there are two types of constraints that need to be met in exposure: query-level and day-level constraints. We model this problem as constrained markov decision process with per-state constraint (psCMDP) and propose a constrained two-level reinforcement learning to decouple the original advertising exposure optimization problem into two relatively independent sub-optimization problems. We also propose a constrained hindsight experience replay mechanism to accelerate the policy training process. Experimental results show that our method can improve the advertising revenue while satisfying different levels of constraints under the real-world datasets. Besides, the proposal of constrained hindsight experience replay mechanism can significantly improve the training speed and the stability of policy performance.
Towards Cooperation in Sequential Prisoner's Dilemmas: a Deep Multiagent Reinforcement Learning Approach
Mar 01, 2018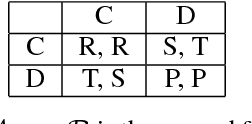
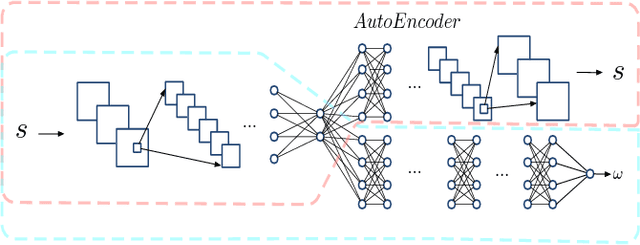
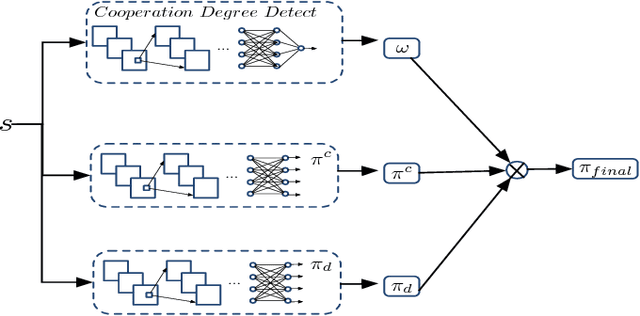

The Iterated Prisoner's Dilemma has guided research on social dilemmas for decades. However, it distinguishes between only two atomic actions: cooperate and defect. In real-world prisoner's dilemmas, these choices are temporally extended and different strategies may correspond to sequences of actions, reflecting grades of cooperation. We introduce a Sequential Prisoner's Dilemma (SPD) game to better capture the aforementioned characteristics. In this work, we propose a deep multiagent reinforcement learning approach that investigates the evolution of mutual cooperation in SPD games. Our approach consists of two phases. The first phase is offline: it synthesizes policies with different cooperation degrees and then trains a cooperation degree detection network. The second phase is online: an agent adaptively selects its policy based on the detected degree of opponent cooperation. The effectiveness of our approach is demonstrated in two representative SPD 2D games: the Apple-Pear game and the Fruit Gathering game. Experimental results show that our strategy can avoid being exploited by exploitative opponents and achieve cooperation with cooperative opponents.