 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneReason Technical Report
Jun 04, 2026Generative recommendation models in the OneRec family have been widely deployed in many real-world services, such as short-video, live-streaming, advertising, and e-commerce. However, these generative models can only benefit from the scaling advantage, while their reasoning ability is hard to activate, since we cannot construct meaningful Chain-of-Thought (CoT) sequences consisting of itemic tokens only. Inspired by the success of the reasoning-style ``think before answer'' paradigm in the LLM field, we conduct preliminary studies (i.e., OneRec-Think, OpenOneRec) to explore reasoning capability in generative recommendation. Nevertheless, we notice an unexpected phenomenon: the thinking mode does not show advantages over the non-thinking mode. Drawing insights from recent findings on CoT robustness in multi-modal language models, we argue that effective reasoning in recommendation rests on two factors: perception, the ability to ground itemic tokens in their underlying language semantics, and cognition, the ability to reorganize a user's behavior sequence into coherent latent interest points. We therefore propose OneReason, which includes: (1) strong itemic token perception in pre-training, (2) a three-level cognition-enhanced CoT format for recommendation tasks in SFT, and (3) a specialize-then-unify training recipe in RL to enhance the thinking ability.
Reasoning over Semantic IDs Enhances Generative Recommendation
Mar 24, 2026Recent advances in generative recommendation have leveraged pretrained LLMs by formulating sequential recommendation as autoregressive generation over a unified token space comprising language tokens and itemic identifiers, where each item is represented by a compact sequence of discrete tokens, namely Semantic IDs (SIDs). This SID-based formulation enables efficient decoding over large-scale item corpora and provides a natural interface for LLM-based recommenders to leverage rich world knowledge. Meanwhile, breakthroughs in LLM reasoning motivate reasoning-enhanced recommendation, yet effective reasoning over SIDs remains underexplored and challenging. Itemic tokens are not natively meaningful to LLMs; moreover, recommendation-oriented SID reasoning is hard to evaluate, making high-quality supervision scarce. To address these challenges, we propose SIDReasoner, a two-stage framework that elicits reasoning over SIDs by strengthening SID--language alignment to unlock transferable LLM reasoning, rather than relying on large amounts of recommendation-specific reasoning traces. Concretely, SIDReasoner first enhances SID-language alignment via multi-task training on an enriched SID-centered corpus synthesized by a stronger teacher model, grounding itemic tokens in diverse semantic and behavioral contexts. Building on this enhanced alignment, SIDReasoner further improves recommendation reasoning through outcome-driven reinforced optimization, which guides the model toward effective reasoning trajectories without requiring explicit reasoning annotations. Extensive experiments on three real-world datasets demonstrate the effectiveness of our reasoning-augmented SID-based generative recommendation. Beyond accuracy, the results highlight the broader potential of large reasoning models for generative recommendation, including improved interpretability and cross-domain generalization.
CIRP: Cross-Item Relational Pre-training for Multimodal Product Bundling
Apr 02, 2024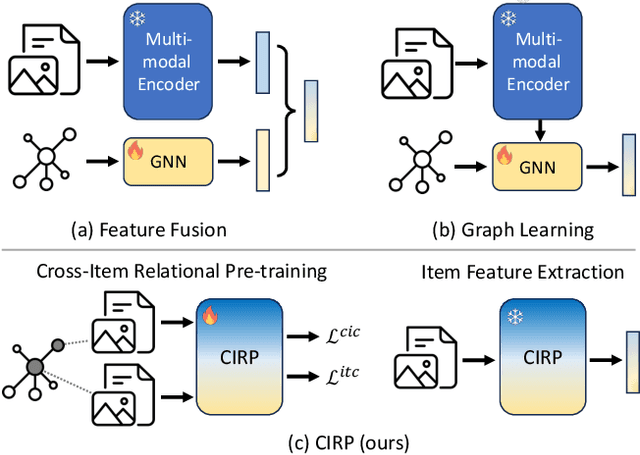

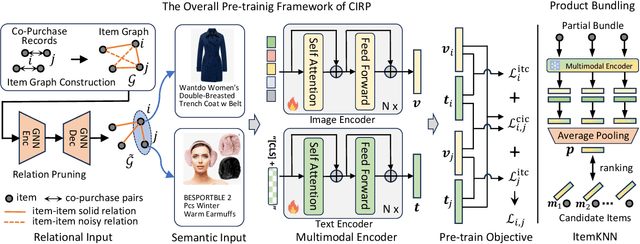
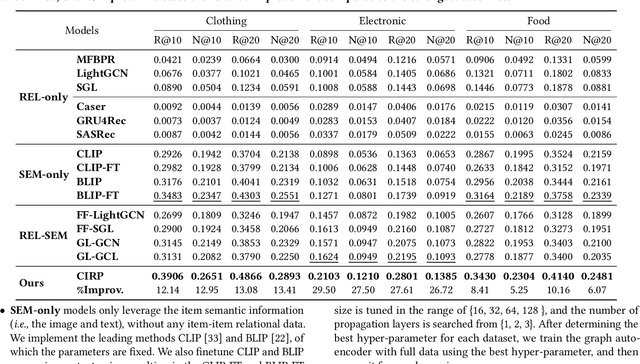
Product bundling has been a prevailing marketing strategy that is beneficial in the online shopping scenario. Effective product bundling methods depend on high-quality item representations, which need to capture both the individual items' semantics and cross-item relations. However, previous item representation learning methods, either feature fusion or graph learning, suffer from inadequate cross-modal alignment and struggle to capture the cross-item relations for cold-start items. Multimodal pre-train models could be the potential solutions given their promising performance on various multimodal downstream tasks. However, the cross-item relations have been under-explored in the current multimodal pre-train models. To bridge this gap, we propose a novel and simple framework Cross-Item Relational Pre-training (CIRP) for item representation learning in product bundling. Specifically, we employ a multimodal encoder to generate image and text representations. Then we leverage both the cross-item contrastive loss (CIC) and individual item's image-text contrastive loss (ITC) as the pre-train objectives. Our method seeks to integrate cross-item relation modeling capability into the multimodal encoder, while preserving the in-depth aligned multimodal semantics. Therefore, even for cold-start items that have no relations, their representations are still relation-aware. Furthermore, to eliminate the potential noise and reduce the computational cost, we harness a relation pruning module to remove the noisy and redundant relations. We apply the item representations extracted by CIRP to the product bundling model ItemKNN, and experiments on three e-commerce datasets demonstrate that CIRP outperforms various leading representation learning methods.
MultiCBR: Multi-view Contrastive Learning for Bundle Recommendation
Nov 28, 2023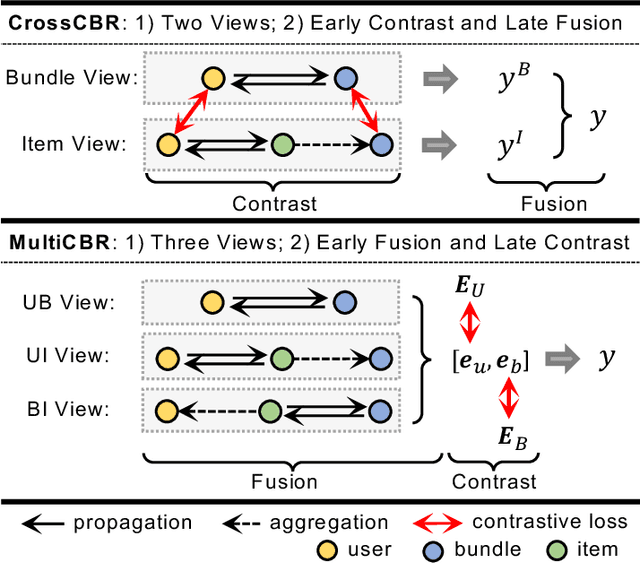

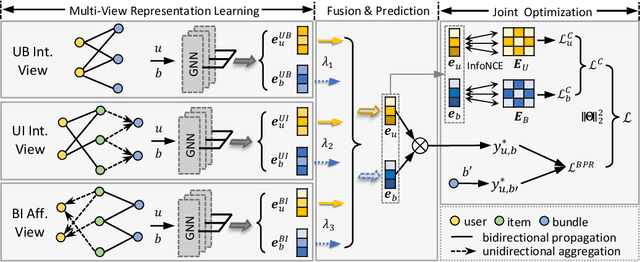
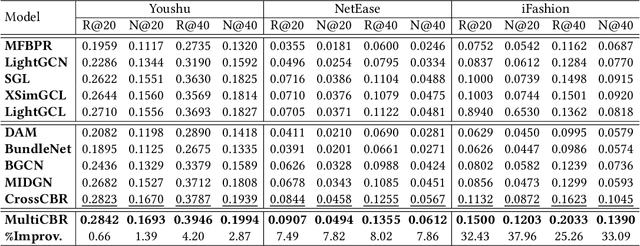
Bundle recommendation seeks to recommend a bundle of related items to users to improve both user experience and the profits of platform. Existing bundle recommendation models have progressed from capturing only user-bundle interactions to the modeling of multiple relations among users, bundles and items. CrossCBR, in particular, incorporates cross-view contrastive learning into a two-view preference learning framework, significantly improving SOTA performance. It does, however, have two limitations: 1) the two-view formulation does not fully exploit all the heterogeneous relations among users, bundles and items; and 2) the "early contrast and late fusion" framework is less effective in capturing user preference and difficult to generalize to multiple views. In this paper, we present MultiCBR, a novel Multi-view Contrastive learning framework for Bundle Recommendation. First, we devise a multi-view representation learning framework capable of capturing all the user-bundle, user-item and bundle-item relations, especially better utilizing the bundle-item affiliations to enhance sparse bundles' representations. Second, we innovatively adopt an "early fusion and late contrast" design that first fuses the multi-view representations before performing self-supervised contrastive learning. In comparison to existing approaches, our framework reverses the order of fusion and contrast, introducing the following advantages: 1)our framework is capable of modeling both cross-view and ego-view preferences, allowing us to achieve enhanced user preference modeling; and 2) instead of requiring quadratic number of cross-view contrastive losses, we only require two self-supervised contrastive losses, resulting in minimal extra costs. Experimental results on three public datasets indicate that our method outperforms SOTA methods.
CrossCBR: Cross-view Contrastive Learning for Bundle Recommendation
Jun 08, 2022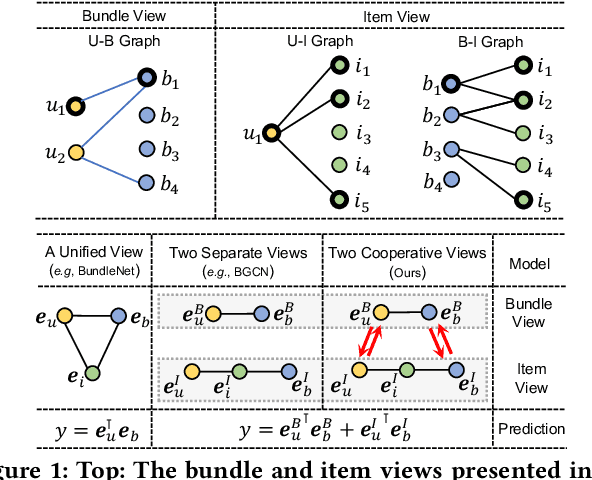
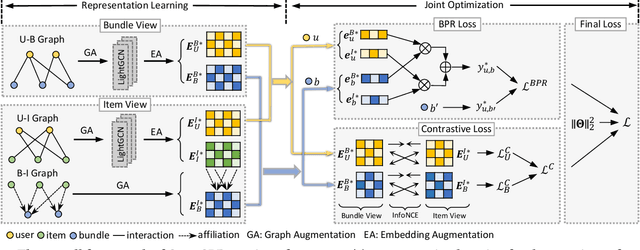
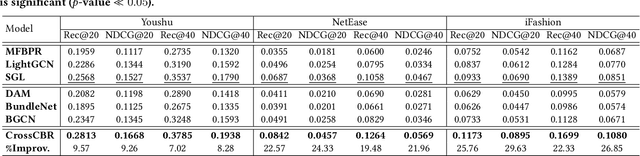
Bundle recommendation aims to recommend a bundle of related items to users, which can satisfy the users' various needs with one-stop convenience. Recent methods usually take advantage of both user-bundle and user-item interactions information to obtain informative representations for users and bundles, corresponding to bundle view and item view, respectively. However, they either use a unified view without differentiation or loosely combine the predictions of two separate views, while the crucial cooperative association between the two views' representations is overlooked. In this work, we propose to model the cooperative association between the two different views through cross-view contrastive learning. By encouraging the alignment of the two separately learned views, each view can distill complementary information from the other view, achieving mutual enhancement. Moreover, by enlarging the dispersion of different users/bundles, the self-discrimination of representations is enhanced. Extensive experiments on three public datasets demonstrate that our method outperforms SOTA baselines by a large margin. Meanwhile, our method requires minimal parameters of three set of embeddings (user, bundle, and item) and the computational costs are largely reduced due to more concise graph structure and graph learning module. In addition, various ablation and model studies demystify the working mechanism and justify our hypothesis. Codes and datasets are available at https://github.com/mysbupt/CrossCBR.
* 9 pages, 5 figures, 5 tables