 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIRP: Cross-Item Relational Pre-training for Multimodal Product Bundling
Paper and Code
Apr 02, 2024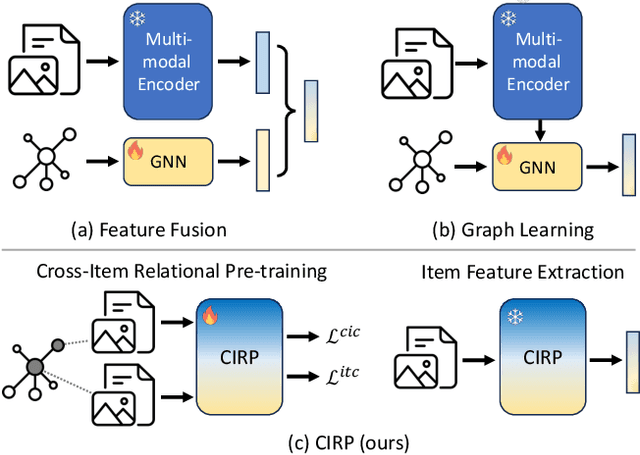

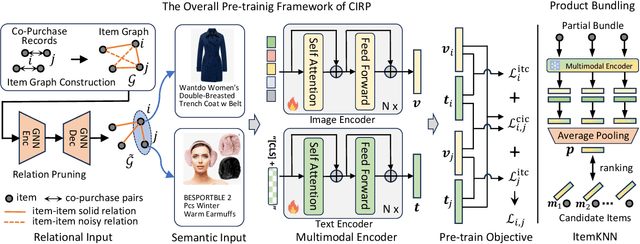
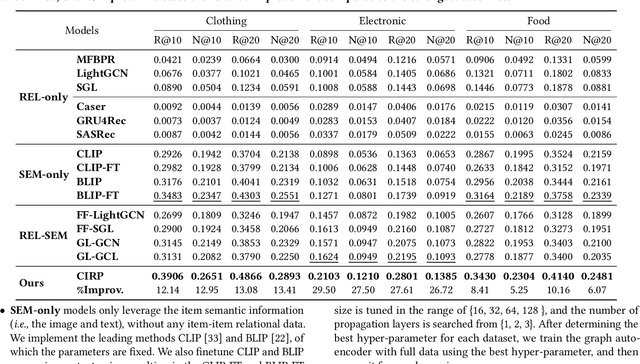
Product bundling has been a prevailing marketing strategy that is beneficial in the online shopping scenario. Effective product bundling methods depend on high-quality item representations, which need to capture both the individual items' semantics and cross-item relations. However, previous item representation learning methods, either feature fusion or graph learning, suffer from inadequate cross-modal alignment and struggle to capture the cross-item relations for cold-start items. Multimodal pre-train models could be the potential solutions given their promising performance on various multimodal downstream tasks. However, the cross-item relations have been under-explored in the current multimodal pre-train models. To bridge this gap, we propose a novel and simple framework Cross-Item Relational Pre-training (CIRP) for item representation learning in product bundling. Specifically, we employ a multimodal encoder to generate image and text representations. Then we leverage both the cross-item contrastive loss (CIC) and individual item's image-text contrastive loss (ITC) as the pre-train objectives. Our method seeks to integrate cross-item relation modeling capability into the multimodal encoder, while preserving the in-depth aligned multimodal semantics. Therefore, even for cold-start items that have no relations, their representations are still relation-aware. Furthermore, to eliminate the potential noise and reduce the computational cost, we harness a relation pruning module to remove the noisy and redundant relations. We apply the item representations extracted by CIRP to the product bundling model ItemKNN, and experiments on three e-commerce datasets demonstrate that CIRP outperforms various leading representation learning methods.