 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransductive Kernels for Gaussian Processes on Graphs
Nov 28, 2022
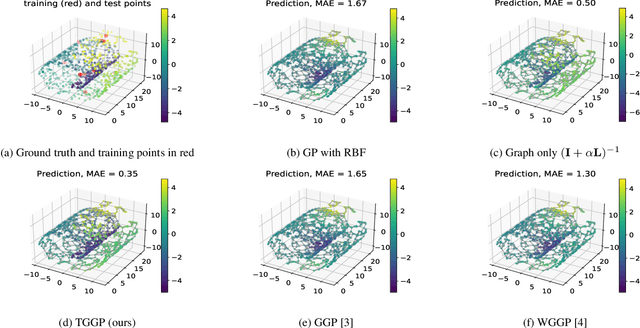
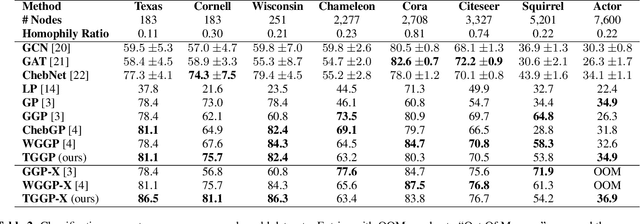
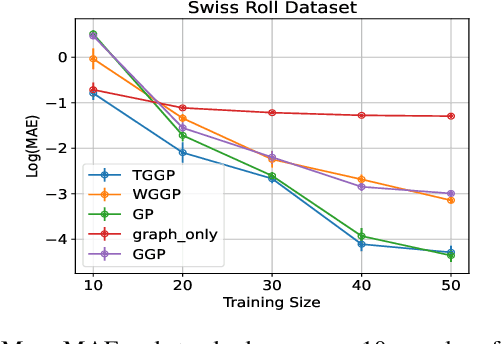
Kernels on graphs have had limited options for node-level problems. To address this, we present a novel, generalized kernel for graphs with node feature data for semi-supervised learning. The kernel is derived from a regularization framework by treating the graph and feature data as two Hilbert spaces. We also show how numerous kernel-based models on graphs are instances of our design. A kernel defined this way has transductive properties, and this leads to improved ability to learn on fewer training points, as well as better handling of highly non-Euclidean data. We demonstrate these advantages using synthetic data where the distribution of the whole graph can inform the pattern of the labels. Finally, by utilizing a flexible polynomial of the graph Laplacian within the kernel, the model also performed effectively in semi-supervised classification on graphs of various levels of homophily.
Gaussian Processes on Graphs via Spectral Kernel Learning
Jun 12, 2020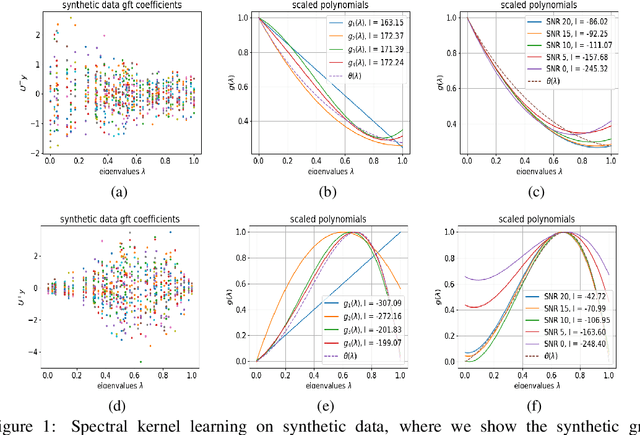

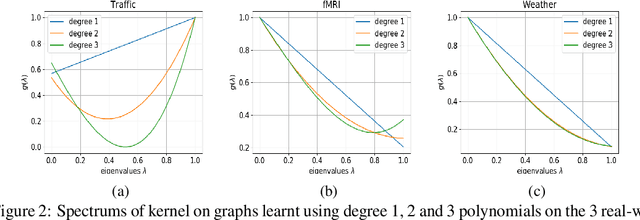
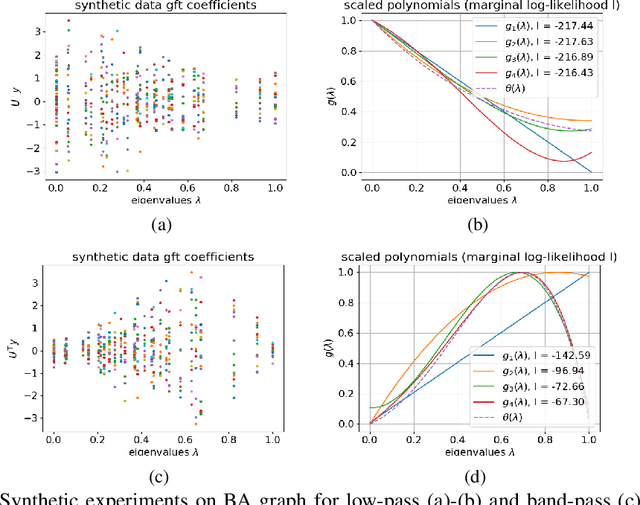
We propose a graph spectrum-based Gaussian process for prediction of signals defined on nodes of the graph. The model is designed to capture various graph signal structures through a highly adaptive kernel that incorporates a flexible polynomial function in the graph spectral domain. Unlike most existing approaches, we propose to learn such a spectral kernel, where the polynomial setup enables learning without the need for eigen-decomposition of the graph Laplacian. In addition, this kernel has the interpretability of graph filtering achieved by a bespoke maximum likelihood learning algorithm that enforces the positivity of the spectrum. We demonstrate the interpretability of the model in synthetic experiments from which we show the various ground truth spectral filters can be accurately recovered, and the adaptability translates to superior performances in the prediction of real-world graph data of various characteristics.
Bayesian Semi-supervised Learning with Graph Gaussian Processes
Oct 12, 2018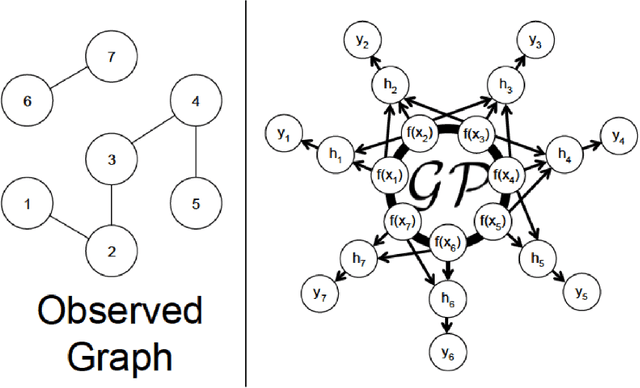
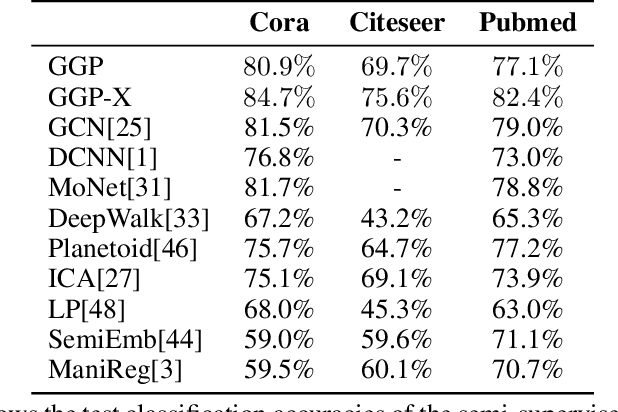

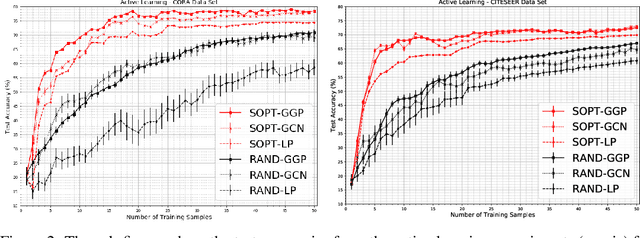
We propose a data-efficient Gaussian process-based Bayesian approach to the semi-supervised learning problem on graphs. The proposed model shows extremely competitive performance when compared to the state-of-the-art graph neural networks on semi-supervised learning benchmark experiments, and outperforms the neural networks in active learning experiments where labels are scarce. Furthermore, the model does not require a validation data set for early stopping to control over-fitting. Our model can be viewed as an instance of empirical distribution regression weighted locally by network connectivity. We further motivate the intuitive construction of the model with a Bayesian linear model interpretation where the node features are filtered by an operator related to the graph Laplacian. The method can be easily implemented by adapting off-the-shelf scalable variational inference algorithms for Gaussian processes.
A Dynamic Edge Exchangeable Model for Sparse Temporal Networks
Oct 11, 2017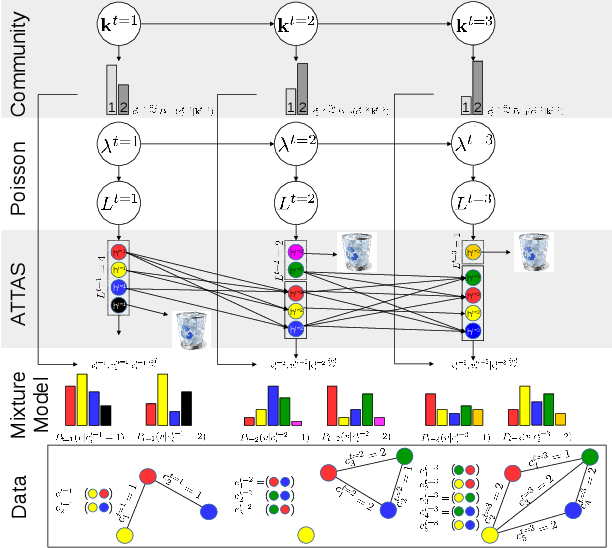
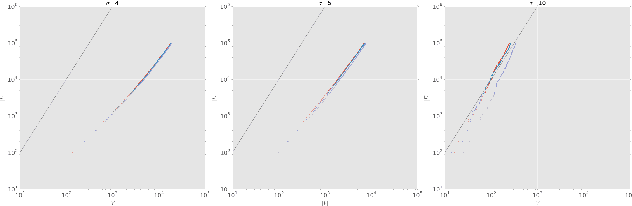
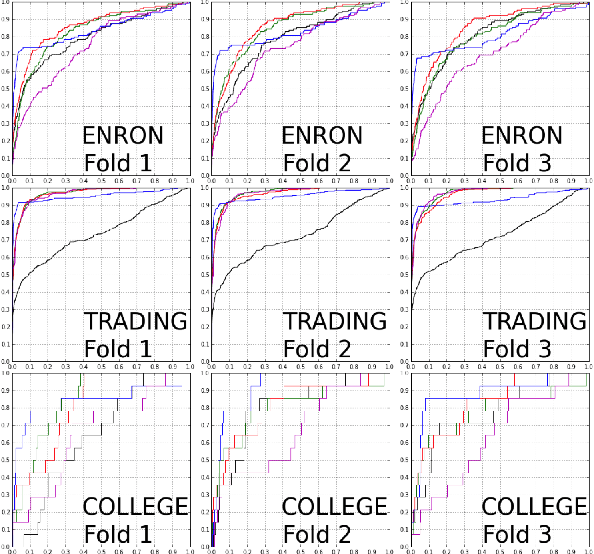
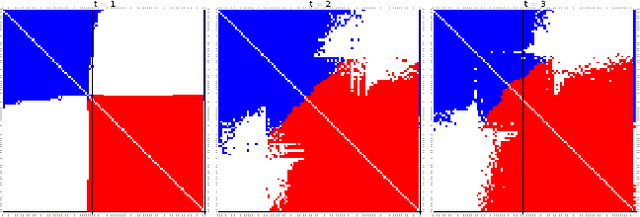
We propose a dynamic edge exchangeable network model that can capture sparse connections observed in real temporal networks, in contrast to existing models which are dense. The model achieved superior link prediction accuracy on multiple data sets when compared to a dynamic variant of the blockmodel, and is able to extract interpretable time-varying community structures from the data. In addition to sparsity, the model accounts for the effect of social influence on vertices' future behaviours. Compared to the dynamic blockmodels, our model has a smaller latent space. The compact latent space requires a smaller number of parameters to be estimated in variational inference and results in a computationally friendly inference algorithm.
Scaling Factorial Hidden Markov Models: Stochastic Variational Inference without Messages
Oct 28, 2016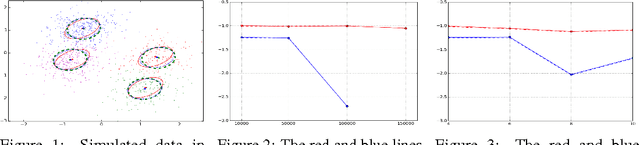
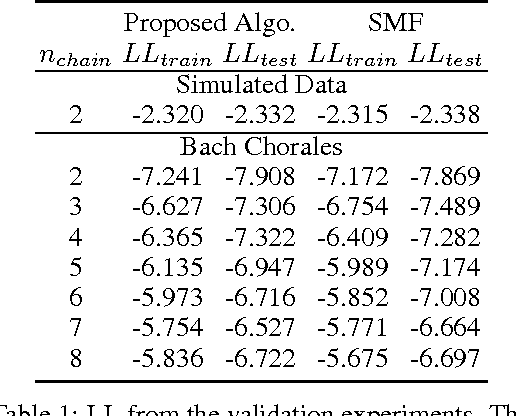

Factorial Hidden Markov Models (FHMMs) are powerful models for sequential data but they do not scale well with long sequences. We propose a scalable inference and learning algorithm for FHMMs that draws on ideas from the stochastic variational inference, neural network and copula literatures. Unlike existing approaches, the proposed algorithm requires no message passing procedure among latent variables and can be distributed to a network of computers to speed up learning. Our experiments corroborate that the proposed algorithm does not introduce further approximation bias compared to the proven structured mean-field algorithm, and achieves better performance with long sequences and large FHMMs.