 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELIANT: Fair Knowledge Distillation for Graph Neural Networks
Jan 04, 2023Graph Neural Networks (GNNs) have shown satisfying performance on various graph learning tasks. To achieve better fitting capability, most GNNs are with a large number of parameters, which makes these GNNs computationally expensive. Therefore, it is difficult to deploy them onto edge devices with scarce computational resources, e.g., mobile phones and wearable smart devices. Knowledge Distillation (KD) is a common solution to compress GNNs, where a light-weighted model (i.e., the student model) is encouraged to mimic the behavior of a computationally expensive GNN (i.e., the teacher GNN model). Nevertheless, most existing GNN-based KD methods lack fairness consideration. As a consequence, the student model usually inherits and even exaggerates the bias from the teacher GNN. To handle such a problem, we take initial steps towards fair knowledge distillation for GNNs. Specifically, we first formulate a novel problem of fair knowledge distillation for GNN-based teacher-student frameworks. Then we propose a principled framework named RELIANT to mitigate the bias exhibited by the student model. Notably, the design of RELIANT is decoupled from any specific teacher and student model structures, and thus can be easily adapted to various GNN-based KD frameworks. We perform extensive experiments on multiple real-world datasets, which corroborates that RELIANT achieves less biased GNN knowledge distillation while maintaining high prediction utility.
Traffic-Aware Transmission Mode Selection in D2D-enabled Cellular Networks with Token System
Jun 13, 2017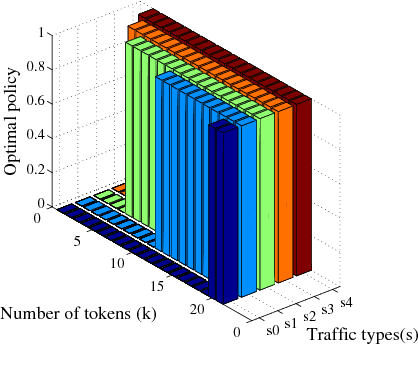
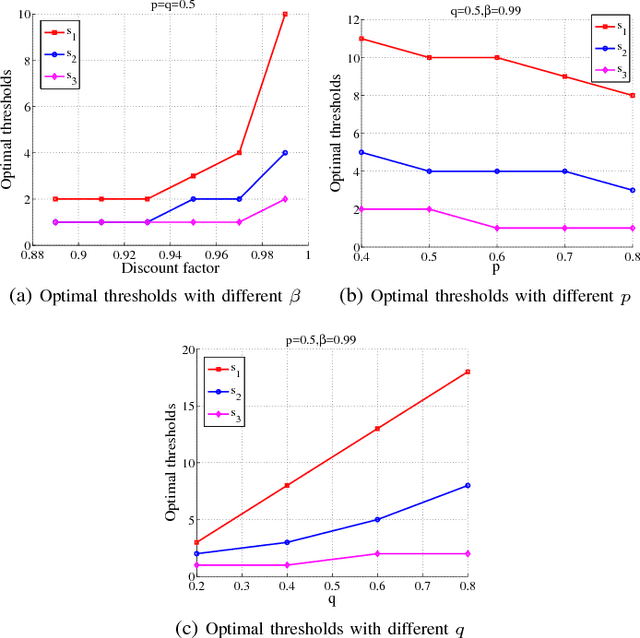
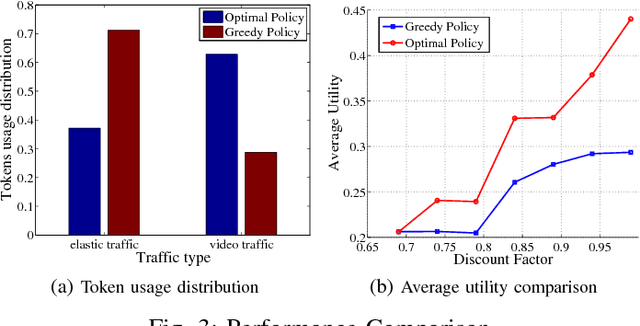

We consider a D2D-enabled cellular network where user equipments (UEs) owned by rational users are incentivized to form D2D pairs using tokens. They exchange tokens electronically to "buy" and "sell" D2D services. Meanwhile the devices have the ability to choose the transmission mode, i.e. receiving data via cellular links or D2D links. Thus taking the different benefits brought by diverse traffic types as a prior, the UEs can utilize their tokens more efficiently via transmission mode selection. In this paper, the optimal transmission mode selection strategy as well as token collection policy are investigated to maximize the long-term utility in the dynamic network environment. The optimal policy is proved to be a threshold strategy, and the thresholds have a monotonicity property. Numerical simulations verify our observations and the gain from transmission mode selection is observed.