 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMErroR: A Benchmark for Erroneous Reasoning in Vision-Language Models
Jan 06, 2026Recent advances in Vision-Language Models (VLMs) have improved performance in multi-modal learning, raising the question of whether these models truly understand the content they process. Crucially, can VLMs detect when a reasoning process is wrong and identify its error type? To answer this, we present MMErroR, a multi-modal benchmark of 2,013 samples, each embedding a single coherent reasoning error. These samples span 24 subdomains across six top-level domains, ensuring broad coverage and taxonomic richness. Unlike existing benchmarks that focus on answer correctness, MMErroR targets a process-level, error-centric evaluation that requires models to detect incorrect reasoning and classify the error type within both visual and linguistic contexts. We evaluate 20 advanced VLMs, even the best model (Gemini-3.0-Pro) classifies the error in only 66.47\% of cases, underscoring the challenge of identifying erroneous reasoning. Furthermore, the ability to accurately identify errors offers valuable insights into the capabilities of multi-modal reasoning models. Project Page: https://mmerror-benchmark.github.io
A Survey on Post-training of Large Language Models
Mar 08, 2025The emergence of Large Language Models (LLMs) has fundamentally transformed natural language processing, making them indispensable across domains ranging from conversational systems to scientific exploration. However, their pre-trained architectures often reveal limitations in specialized contexts, including restricted reasoning capacities, ethical uncertainties, and suboptimal domain-specific performance. These challenges necessitate advanced post-training language models (PoLMs) to address these shortcomings, such as OpenAI-o1/o3 and DeepSeek-R1 (collectively known as Large Reasoning Models, or LRMs). This paper presents the first comprehensive survey of PoLMs, systematically tracing their evolution across five core paradigms: Fine-tuning, which enhances task-specific accuracy; Alignment, which ensures alignment with human preferences; Reasoning, which advances multi-step inference despite challenges in reward design; Efficiency, which optimizes resource utilization amidst increasing complexity; and Integration and Adaptation, which extend capabilities across diverse modalities while addressing coherence issues. Charting progress from ChatGPT's foundational alignment strategies to DeepSeek-R1's innovative reasoning advancements, we illustrate how PoLMs leverage datasets to mitigate biases, deepen reasoning capabilities, and enhance domain adaptability. Our contributions include a pioneering synthesis of PoLM evolution, a structured taxonomy categorizing techniques and datasets, and a strategic agenda emphasizing the role of LRMs in improving reasoning proficiency and domain flexibility. As the first survey of its scope, this work consolidates recent PoLM advancements and establishes a rigorous intellectual framework for future research, fostering the development of LLMs that excel in precision, ethical robustness, and versatility across scientific and societal applications.
MLP-KAN: Unifying Deep Representation and Function Learning
Oct 03, 2024



Recent advancements in both representation learning and function learning have demonstrated substantial promise across diverse domains of artificial intelligence. However, the effective integration of these paradigms poses a significant challenge, particularly in cases where users must manually decide whether to apply a representation learning or function learning model based on dataset characteristics. To address this issue, we introduce MLP-KAN, a unified method designed to eliminate the need for manual model selection. By integrating Multi-Layer Perceptrons (MLPs) for representation learning and Kolmogorov-Arnold Networks (KANs) for function learning within a Mixture-of-Experts (MoE) architecture, MLP-KAN dynamically adapts to the specific characteristics of the task at hand, ensuring optimal performance. Embedded within a transformer-based framework, our work achieves remarkable results on four widely-used datasets across diverse domains. Extensive experimental evaluation demonstrates its superior versatility, delivering competitive performance across both deep representation and function learning tasks. These findings highlight the potential of MLP-KAN to simplify the model selection process, offering a comprehensive, adaptable solution across various domains. Our code and weights are available at \url{https://github.com/DLYuanGod/MLP-KAN}.
Improve Text Classification Accuracy with Intent Information
Dec 15, 2022Text classification, a core component of task-oriented dialogue systems, attracts continuous research from both the research and industry community, and has resulted in tremendous progress. However, existing method does not consider the use of label information, which may weaken the performance of text classification systems in some token-aware scenarios. To address the problem, in this paper, we introduce the use of label information as label embedding for the task of text classification and achieve remarkable performance on benchmark dataset.
Feature-augmented Machine Reading Comprehension with Auxiliary Tasks
Nov 17, 2022


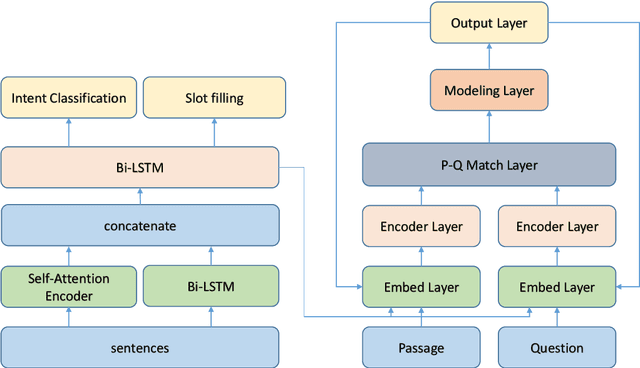
While most successful approaches for machine reading comprehension rely on single training objective, it is assumed that the encoder layer can learn great representation through the loss function we define in the predict layer, which is cross entropy in most of time, in the case that we first use neural networks to encode the question and paragraph, then directly fuse the encoding result of them. However, due to the distantly loss backpropagating in reading comprehension, the encoder layer cannot learn effectively and be directly supervised. Thus, the encoder layer can not learn the representation well at any time. Base on this, we propose to inject multi granularity information to the encoding layer. Experiments demonstrate the effect of adding multi granularity information to the encoding layer can boost the performance of machine reading comprehension system. Finally, empirical study shows that our approach can be applied to many existing MRC models.