 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfect Clustering for Sparse Directed Stochastic Block Models
Jan 23, 2026Exact recovery in stochastic block models (SBMs) is well understood in undirected settings, but remains considerably less developed for directed and sparse networks, particularly when the number of communities diverges. Spectral methods for directed SBMs often lack stability in asymmetric, low-degree regimes, and existing non-spectral approaches focus primarily on undirected or dense settings. We propose a fully non-spectral, two-stage procedure for community detection in sparse directed SBMs with potentially growing numbers of communities. The method first estimates the directed probability matrix using a neighborhood-smoothing scheme tailored to the asymmetric setting, and then applies $K$-means clustering to the estimated rows, thereby avoiding the limitations of eigen- or singular value decompositions in sparse, asymmetric networks. Our main theoretical contribution is a uniform row-wise concentration bound for the smoothed estimator, obtained through new arguments that control asymmetric neighborhoods and separate in- and out-degree effects. These results imply the exact recovery of all community labels with probability tending to one, under mild sparsity and separation conditions that allow both $γ_n \to 0$ and $K_n \to \infty$. Simulation studies, including highly directed, sparse, and non-symmetric block structures, demonstrate that the proposed procedure performs reliably in regimes where directed spectral and score-based methods deteriorate. To the best of our knowledge, this provides the first exact recovery guarantee for this class of non-spectral, neighborhood-smoothing methods in the sparse, directed setting.
Alpha Mining and Enhancing via Warm Start Genetic Programming for Quantitative Investment
Dec 01, 2024

Traditional genetic programming (GP) often struggles in stock alpha factor discovery due to its vast search space, overwhelming computational burden, and sporadic effective alphas. We find that GP performs better when focusing on promising regions rather than random searching. This paper proposes a new GP framework with carefully chosen initialization and structural constraints to enhance search performance and improve the interpretability of the alpha factors. This approach is motivated by and mimics the alpha searching practice and aims to boost the efficiency of such a process. Analysis of 2020-2024 Chinese stock market data shows that our method yields superior out-of-sample prediction results and higher portfolio returns than the benchmark.
Sparsified Simultaneous Confidence Intervals for High-Dimensional Linear Models
Jul 14, 2023Statistical inference of the high-dimensional regression coefficients is challenging because the uncertainty introduced by the model selection procedure is hard to account for. A critical question remains unsettled; that is, is it possible and how to embed the inference of the model into the simultaneous inference of the coefficients? To this end, we propose a notion of simultaneous confidence intervals called the sparsified simultaneous confidence intervals. Our intervals are sparse in the sense that some of the intervals' upper and lower bounds are shrunken to zero (i.e., $[0,0]$), indicating the unimportance of the corresponding covariates. These covariates should be excluded from the final model. The rest of the intervals, either containing zero (e.g., $[-1,1]$ or $[0,1]$) or not containing zero (e.g., $[2,3]$), indicate the plausible and significant covariates, respectively. The proposed method can be coupled with various selection procedures, making it ideal for comparing their uncertainty. For the proposed method, we establish desirable asymptotic properties, develop intuitive graphical tools for visualization, and justify its superior performance through simulation and real data analysis.
Statistical inference on random dot product graphs: a survey
Sep 16, 2017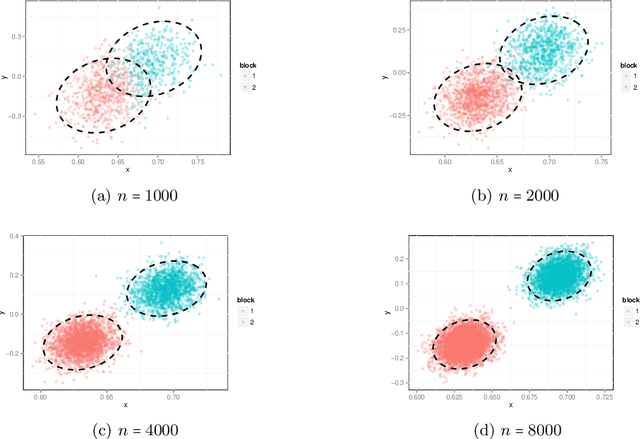
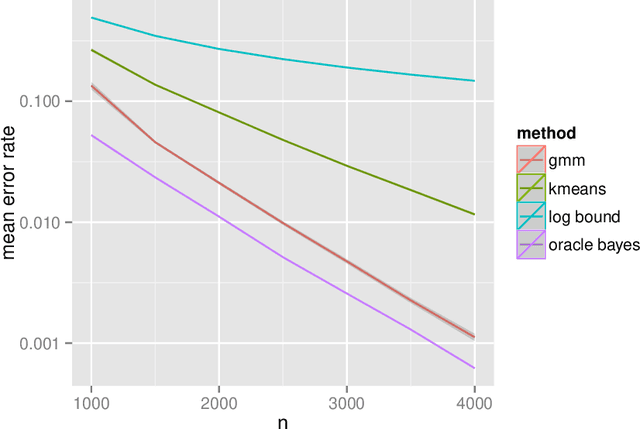

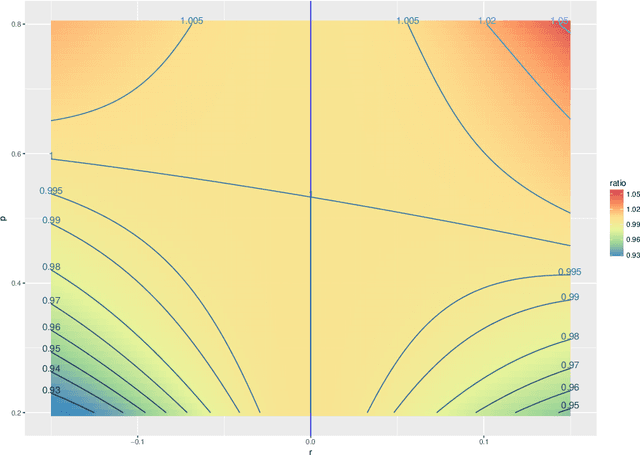
The random dot product graph (RDPG) is an independent-edge random graph that is analytically tractable and, simultaneously, either encompasses or can successfully approximate a wide range of random graphs, from relatively simple stochastic block models to complex latent position graphs. In this survey paper, we describe a comprehensive paradigm for statistical inference on random dot product graphs, a paradigm centered on spectral embeddings of adjacency and Laplacian matrices. We examine the analogues, in graph inference, of several canonical tenets of classical Euclidean inference: in particular, we summarize a body of existing results on the consistency and asymptotic normality of the adjacency and Laplacian spectral embeddings, and the role these spectral embeddings can play in the construction of single- and multi-sample hypothesis tests for graph data. We investigate several real-world applications, including community detection and classification in large social networks and the determination of functional and biologically relevant network properties from an exploratory data analysis of the Drosophila connectome. We outline requisite background and current open problems in spectral graph inference.
* An expository survey paper on a comprehensive paradigm for inference for random dot product graphs, centered on graph adjacency and Laplacian spectral embeddings. Paper outlines requisite background; summarizes theory, methodology, and applications from previous and ongoing work; and closes with a discussion of several open problems
Semiparametric spectral modeling of the Drosophila connectome
May 09, 2017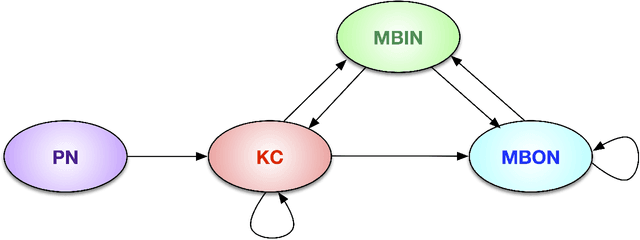
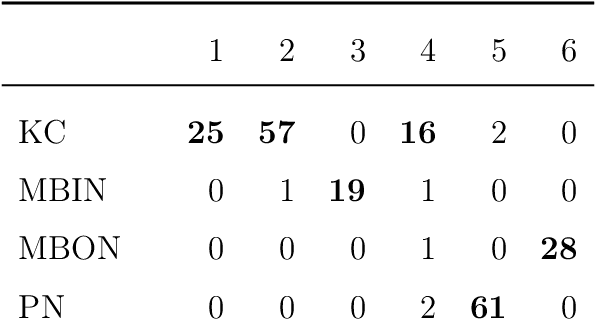
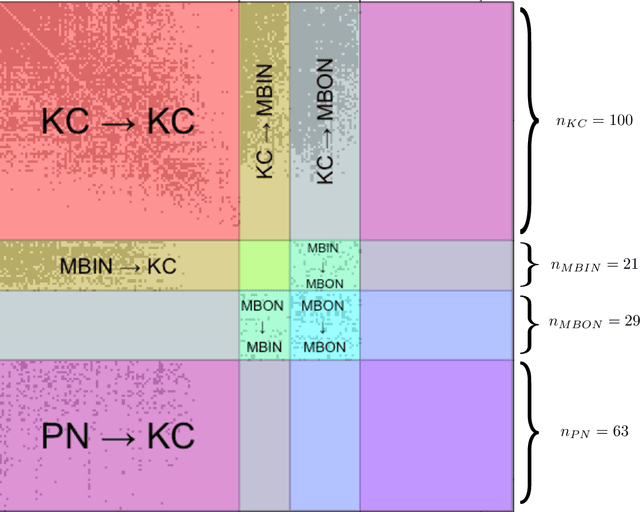

We present semiparametric spectral modeling of the complete larval Drosophila mushroom body connectome. Motivated by a thorough exploratory data analysis of the network via Gaussian mixture modeling (GMM) in the adjacency spectral embedding (ASE) representation space, we introduce the latent structure model (LSM) for network modeling and inference. LSM is a generalization of the stochastic block model (SBM) and a special case of the random dot product graph (RDPG) latent position model, and is amenable to semiparametric GMM in the ASE representation space. The resulting connectome code derived via semiparametric GMM composed with ASE captures latent connectome structure and elucidates biologically relevant neuronal properties.