 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of central serous chorioretinopathy (CSC) depicted on color fundus photographs using deep Learning
Jan 14, 2019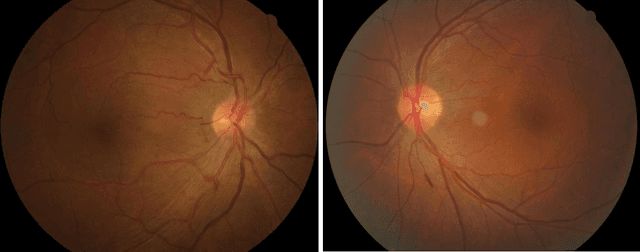
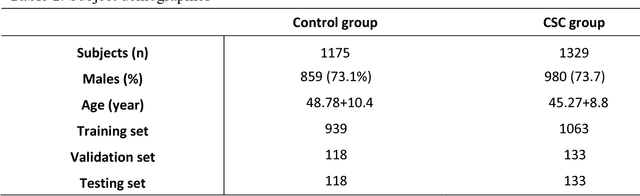

To investigate whether and to what extent central serous chorioretinopathy (CSC) depicted on color fundus photographs can be assessed using deep learning technology. We collected a total of 2,504 fundus images acquired on different subjects. We verified the CSC status of these images using their corresponding optical coherence tomography (OCT) images. A total of 1,329 images depicted CSC. These images were preprocessed and normalized. This resulting dataset was randomly split into three parts in the ratio of 8:1:1 respectively for training, validation, and testing purposes. We used the deep learning architecture termed InceptionV3 to train the classifier. We performed nonparametric receiver operating characteristic (ROC) analyses to assess the capability of the developed algorithm to identify CSC. The Kappa coefficient between the two raters was 0.48 (p < 0.001), while the Kappa coefficients between the computer and the two raters were 0.59 (p < 0.001) and 0.33 (p < 0.05).Our experiments showed that the computer algorithm based on deep learning can assess CSC depicted on color fundus photographs in a relatively reliable and consistent way.
Performance assessment of the deep learning technologies in grading glaucoma severity
Oct 31, 2018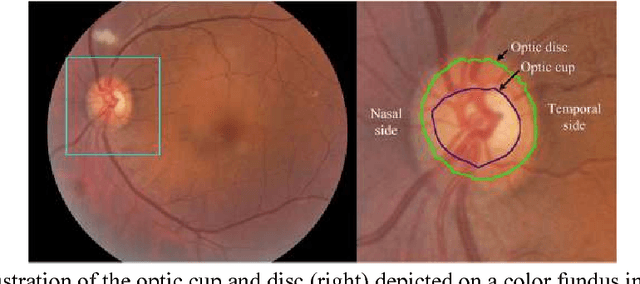
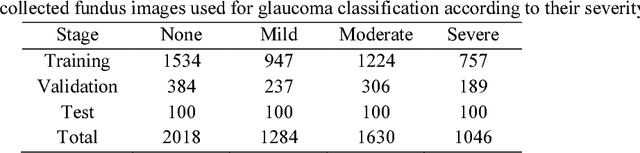
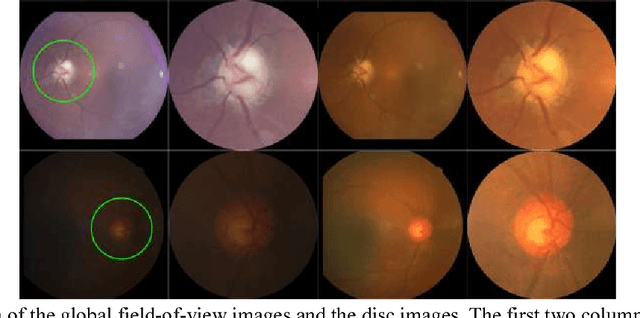
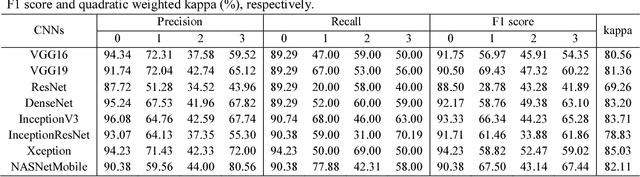
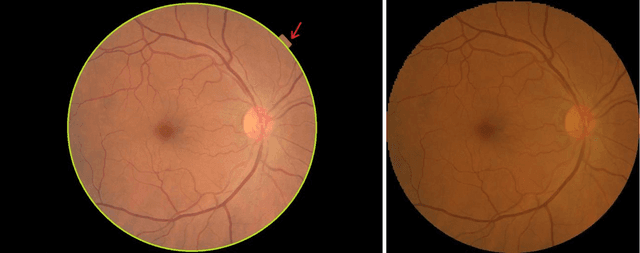
Objective: To validate and compare the performance of eight available deep learning architectures in grading the severity of glaucoma based on color fundus images. Materials and Methods: We retrospectively collected a dataset of 5978 fundus images and their glaucoma severities were annotated by the consensus of two experienced ophthalmologists. We preprocessed the images to generate global and local regions of interest (ROIs), namely the global field-of-view images and the local disc region images. We then divided the generated images into three independent sub-groups for training, validation, and testing purposes. With the datasets, eight convolutional neural networks (CNNs) (i.e., VGG16, VGG19, ResNet, DenseNet, InceptionV3, InceptionResNet, Xception, and NASNetMobile) were trained separately to grade glaucoma severity, and validated quantitatively using the area under the receiver operating characteristic (ROC) curve and the quadratic kappa score. Results: The CNNs, except VGG16 and VGG19, achieved average kappa scores of 80.36% and 78.22% when trained from scratch on global and local ROIs, and 85.29% and 82.72% when fine-tuned using the pre-trained weights, respectively. VGG16 and VGG19 achieved reasonable accuracy when trained from scratch, but they failed when using pre-trained weights for global and local ROIs. Among these CNNs, the DenseNet had the highest classification accuracy (i.e., 75.50%) based on pre-trained weights when using global ROIs, as compared to 65.50% when using local ROIs. Conclusion: The experiments demonstrated the feasibility of the deep learning technology in grading glaucoma severity. In particular, global field-of-view images contain relatively richer information that may be critical for glaucoma assessment, suggesting that we should use the entire field-of-view of a fundus image for training a deep learning network.