 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic annotation for computational pathology: Multidisciplinary experience and best practice recommendations
Jun 25, 2021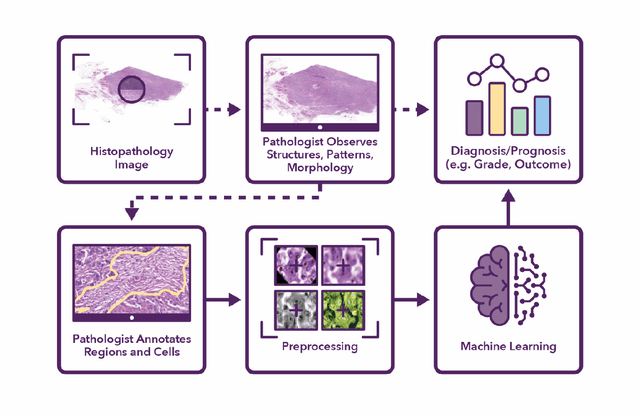

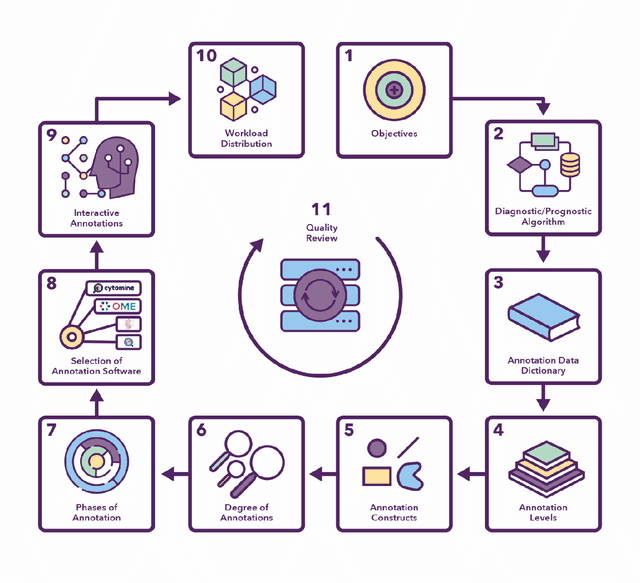
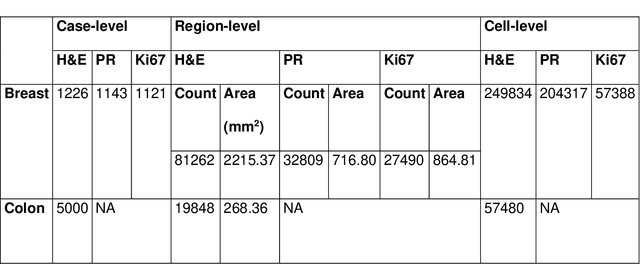
Recent advances in whole slide imaging (WSI) technology have led to the development of a myriad of computer vision and artificial intelligence (AI) based diagnostic, prognostic, and predictive algorithms. Computational Pathology (CPath) offers an integrated solution to utilize information embedded in pathology WSIs beyond what we obtain through visual assessment. For automated analysis of WSIs and validation of machine learning (ML) models, annotations at the slide, tissue and cellular levels are required. The annotation of important visual constructs in pathology images is an important component of CPath projects. Improper annotations can result in algorithms which are hard to interpret and can potentially produce inaccurate and inconsistent results. Despite the crucial role of annotations in CPath projects, there are no well-defined guidelines or best practices on how annotations should be carried out. In this paper, we address this shortcoming by presenting the experience and best practices acquired during the execution of a large-scale annotation exercise involving a multidisciplinary team of pathologists, ML experts and researchers as part of the Pathology image data Lake for Analytics, Knowledge and Education (PathLAKE) consortium. We present a real-world case study along with examples of different types of annotations, diagnostic algorithm, annotation data dictionary and annotation constructs. The analyses reported in this work highlight best practice recommendations that can be used as annotation guidelines over the lifecycle of a CPath project.
Meta-SVDD: Probabilistic Meta-Learning for One-Class Classification in Cancer Histology Images
Mar 06, 2020
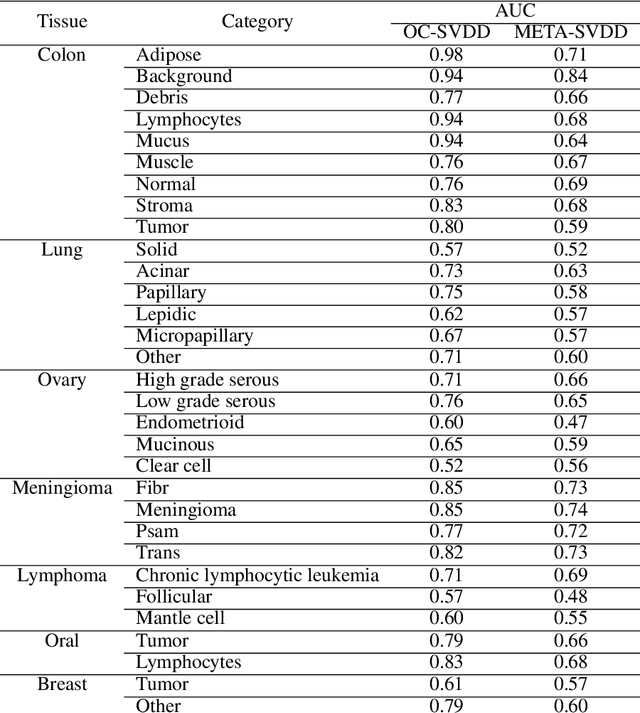
To train a robust deep learning model, one usually needs a balanced set of categories in the training data. The data acquired in a medical domain, however, frequently contains an abundance of healthy patients, versus a small variety of positive, abnormal cases. Moreover, the annotation of a positive sample requires time consuming input from medical domain experts. This scenario would suggest a promise for one-class classification type approaches. In this work we propose a general one-class classification model for histology, that is meta-trained on multiple histology datasets simultaneously, and can be applied to new tasks without expensive re-training. This model could be easily used by pathology domain experts, and potentially be used for screening purposes.
Novel digital tissue phenotypic signatures of distant metastasis in colorectal cancer
Jan 23, 2018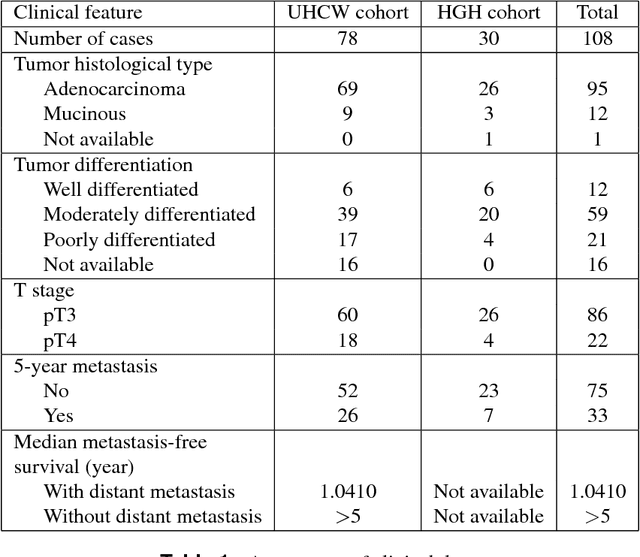
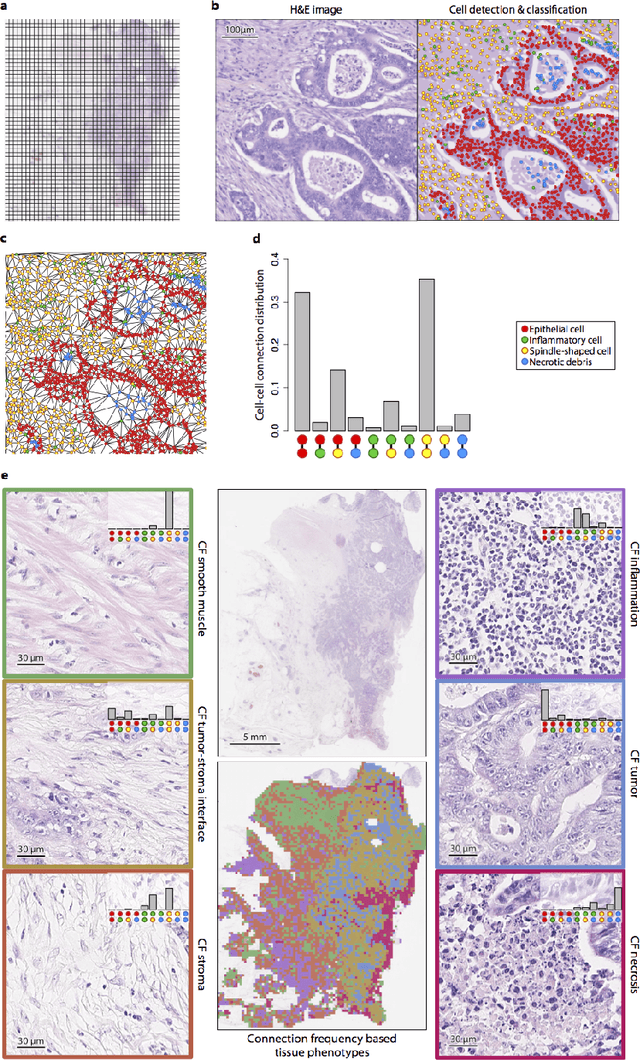
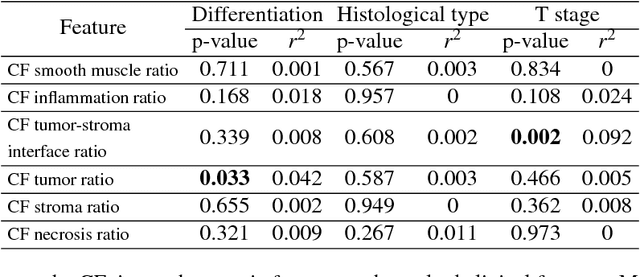
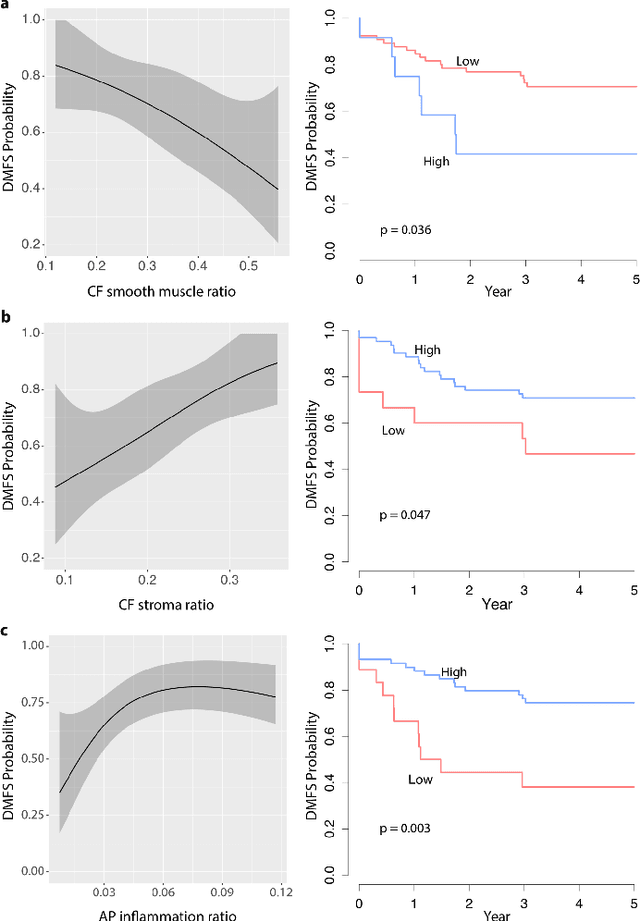
Distant metastasis is the major cause of death in colorectal cancer (CRC). Patients at high risk of developing distant metastasis could benefit from appropriate adjuvant and follow-up treatments if stratified accurately at an early stage of the disease. Studies have increasingly recognized the role of diverse cellular components within the tumor microenvironment in the development and progression of CRC tumors. In this paper, we show that a new method of automated analysis of digitized images from colorectal cancer tissue slides can provide important estimates of distant metastasis-free survival (DMFS, the time before metastasis is first observed) on the basis of details of the microenvironment. Specifically, we determine what cell types are found in the vicinity of other cell types, and in what numbers, rather than concentrating exclusively on the cancerous cells. We then extract novel tissue phenotypic signatures using statistical measurements about tissue composition. Such signatures can underpin clinical decisions about the advisability of various types of adjuvant therapy.