 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedical Relation Extraction via Adaptive Document-Relation Cross-Mapping and Concept Unique Identifier
Jan 09, 2025



Document-Level Biomedical Relation Extraction (Bio-RE) aims to identify relations between biomedical entities within extensive texts, serving as a crucial subfield of biomedical text mining. Existing Bio-RE methods struggle with cross-sentence inference, which is essential for capturing relations spanning multiple sentences. Moreover, previous methods often overlook the incompleteness of documents and lack the integration of external knowledge, limiting contextual richness. Besides, the scarcity of annotated data further hampers model training. Recent advancements in large language models (LLMs) have inspired us to explore all the above issues for document-level Bio-RE. Specifically, we propose a document-level Bio-RE framework via LLM Adaptive Document-Relation Cross-Mapping (ADRCM) Fine-Tuning and Concept Unique Identifier (CUI) Retrieval-Augmented Generation (RAG). First, we introduce the Iteration-of-REsummary (IoRs) prompt for solving the data scarcity issue. In this way, Bio-RE task-specific synthetic data can be generated by guiding ChatGPT to focus on entity relations and iteratively refining synthetic data. Next, we propose ADRCM fine-tuning, a novel fine-tuning recipe that establishes mappings across different documents and relations, enhancing the model's contextual understanding and cross-sentence inference capabilities. Finally, during the inference, a biomedical-specific RAG approach, named CUI RAG, is designed to leverage CUIs as indexes for entities, narrowing the retrieval scope and enriching the relevant document contexts. Experiments conducted on three Bio-RE datasets (GDA, CDR, and BioRED) demonstrate the state-of-the-art performance of our proposed method by comparing it with other related works.
Controllable Relation Disentanglement for Few-Shot Class-Incremental Learning
Mar 17, 2024



In this paper, we propose to tackle Few-Shot Class-Incremental Learning (FSCIL) from a new perspective, i.e., relation disentanglement, which means enhancing FSCIL via disentangling spurious relation between categories. The challenge of disentangling spurious correlations lies in the poor controllability of FSCIL. On one hand, an FSCIL model is required to be trained in an incremental manner and thus it is very hard to directly control relationships between categories of different sessions. On the other hand, training samples per novel category are only in the few-shot setting, which increases the difficulty of alleviating spurious relation issues as well. To overcome this challenge, in this paper, we propose a new simple-yet-effective method, called ConTrollable Relation-disentangLed Few-Shot Class-Incremental Learning (CTRL-FSCIL). Specifically, during the base session, we propose to anchor base category embeddings in feature space and construct disentanglement proxies to bridge gaps between the learning for category representations in different sessions, thereby making category relation controllable. During incremental learning, the parameters of the backbone network are frozen in order to relieve the negative impact of data scarcity. Moreover, a disentanglement loss is designed to effectively guide a relation disentanglement controller to disentangle spurious correlations between the embeddings encoded by the backbone. In this way, the spurious correlation issue in FSCIL can be suppressed. Extensive experiments on CIFAR-100, mini-ImageNet, and CUB-200 datasets demonstrate the effectiveness of our CTRL-FSCIL method.
Advancing Incremental Few-shot Semantic Segmentation via Semantic-guided Relation Alignment and Adaptation
May 18, 2023Incremental few-shot semantic segmentation (IFSS) aims to incrementally extend a semantic segmentation model to novel classes according to only a few pixel-level annotated data, while preserving its segmentation capability on previously learned base categories. This task faces a severe semantic-aliasing issue between base and novel classes due to data imbalance, which makes segmentation results unsatisfactory. To alleviate this issue, we propose the Semantic-guided Relation Alignment and Adaptation (SRAA) method that fully considers the guidance of prior semantic information. Specifically, we first conduct Semantic Relation Alignment (SRA) in the base step, so as to semantically align base class representations to their semantics. As a result, the embeddings of base classes are constrained to have relatively low semantic correlations to categories that are different from them. Afterwards, based on the semantically aligned base categories, Semantic-Guided Adaptation (SGA) is employed during the incremental learning stage. It aims to ensure affinities between visual and semantic embeddings of encountered novel categories, thereby making the feature representations be consistent with their semantic information. In this way, the semantic-aliasing issue can be suppressed. We evaluate our model on the PASCAL VOC 2012 and the COCO dataset. The experimental results on both these two datasets exhibit its competitive performance, which demonstrates the superiority of our method.
Automatic Depression Detection via Learning and Fusing Features from Visual Cues
Mar 01, 2022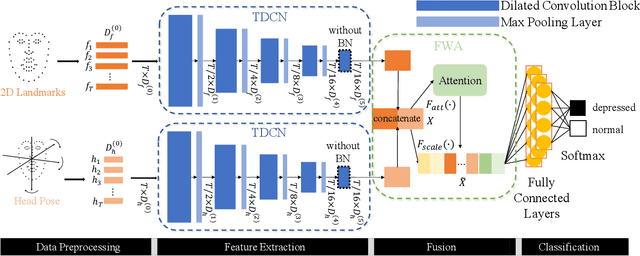
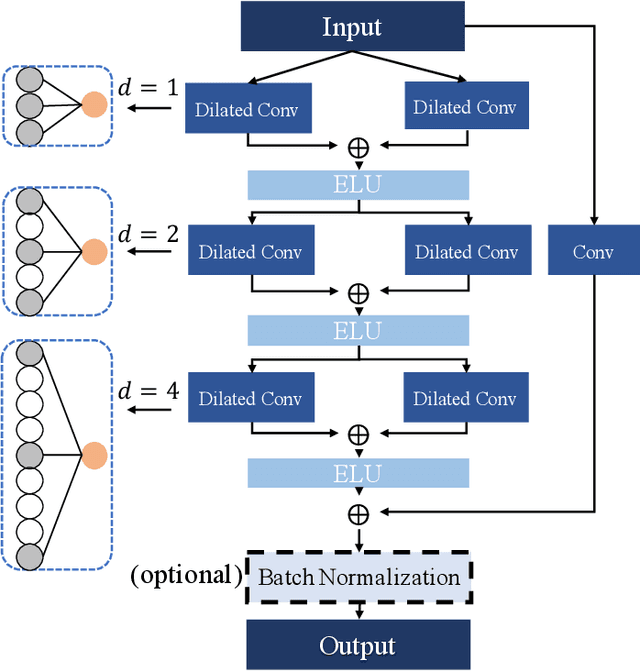
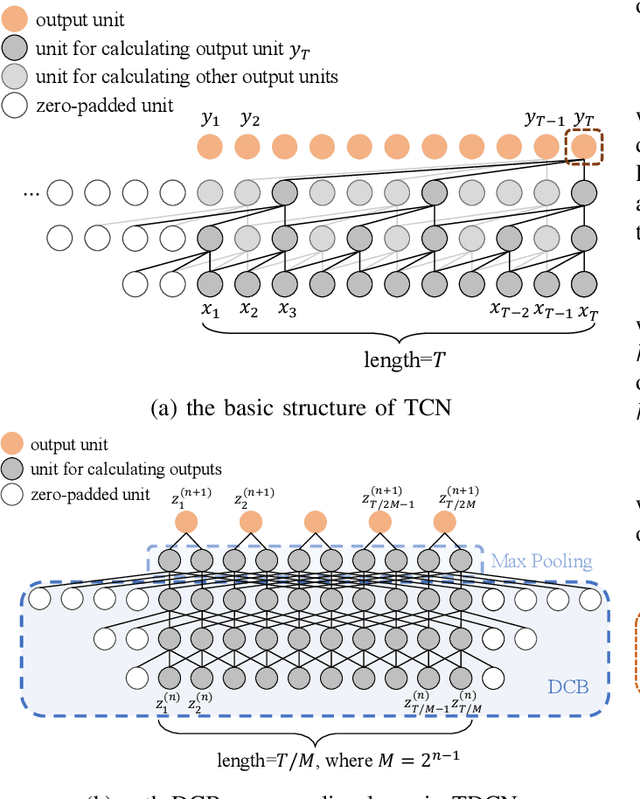
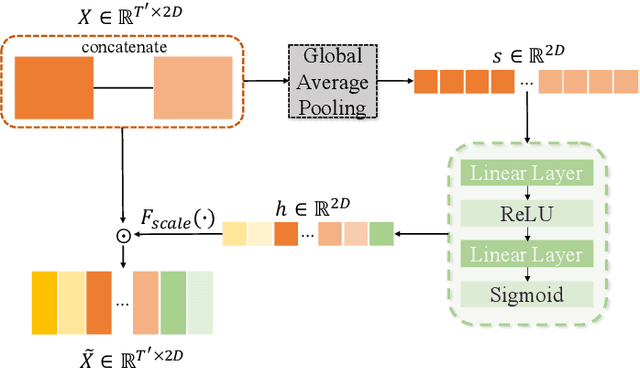
Depression is one of the most prevalent mental disorders, which seriously affects one's life. Traditional depression diagnostics commonly depends on rating with scales, which can be labor-intensive and subjective. In this context, Automatic Depression Detection (ADD) has been attracting more attention for its low cost and objectivity. ADD systems are able to detect depression automatically from some medical records, like video sequences. However, it remains challenging to effectively extract depression-specific information from long sequences, thereby hindering a satisfying accuracy. In this paper, we propose a novel ADD method via learning and fusing features from visual cues. Specifically, we firstly construct Temporal Dilated Convolutional Network (TDCN), in which multiple Dilated Convolution Blocks (DCB) are designed and stacked, to learn the long-range temporal information from sequences. Then, the Feature-Wise Attention (FWA) module is adopted to fuse different features extracted from TDCNs. The module learns to assign weights for the feature channels, aiming to better incorporate different kinds of visual features and further enhance the detection accuracy. Our method achieves the state-of-the-art performance on the DAIC_WOZ dataset compared to other visual-feature-based methods, showing its effectiveness.
Decoupled Low-light Image Enhancement
Nov 29, 2021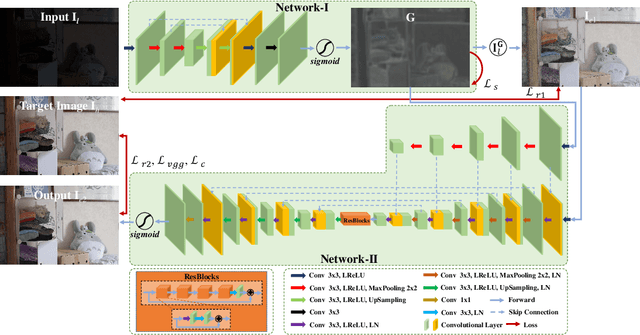
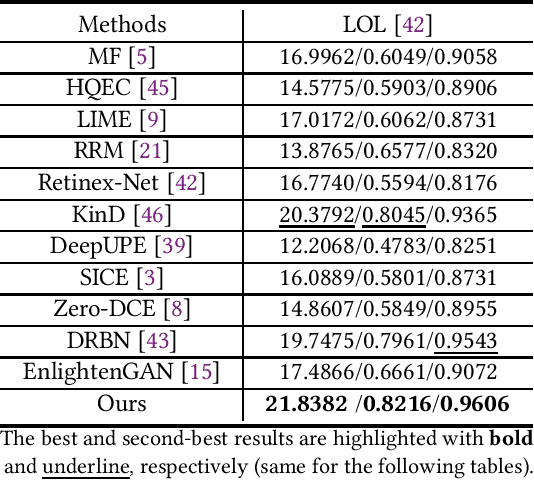

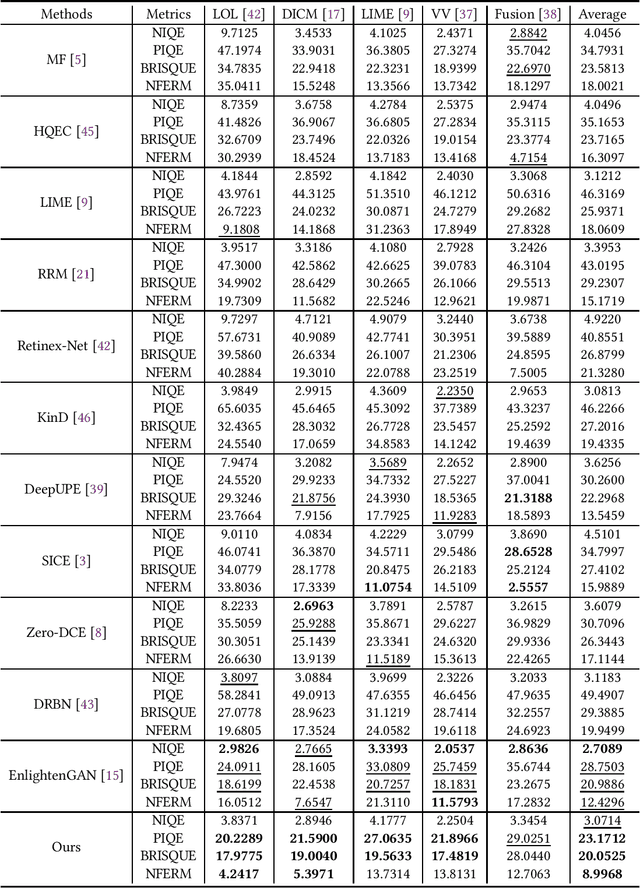
The visual quality of photographs taken under imperfect lightness conditions can be degenerated by multiple factors, e.g., low lightness, imaging noise, color distortion and so on. Current low-light image enhancement models focus on the improvement of low lightness only, or simply deal with all the degeneration factors as a whole, therefore leading to a sub-optimal performance. In this paper, we propose to decouple the enhancement model into two sequential stages. The first stage focuses on improving the scene visibility based on a pixel-wise non-linear mapping. The second stage focuses on improving the appearance fidelity by suppressing the rest degeneration factors. The decoupled model facilitates the enhancement in two aspects. On the one hand, the whole low-light enhancement can be divided into two easier subtasks. The first one only aims to enhance the visibility. It also helps to bridge the large intensity gap between the low-light and normal-light images. In this way, the second subtask can be shaped as the local appearance adjustment. On the other hand, since the parameter matrix learned from the first stage is aware of the lightness distribution and the scene structure, it can be incorporated into the second stage as the complementary information. In the experiments, our model demonstrates the state-of-the-art performance in both qualitative and quantitative comparisons, compared with other low-light image enhancement models. In addition, the ablation studies also validate the effectiveness of our model in multiple aspects, such as model structure and loss function. The trained model is available at https://github.com/hanxuhfut/Decoupled-Low-light-Image-Enhancement.
Few-shot Learning with Global Relatedness Decoupled-Distillation
Jul 12, 2021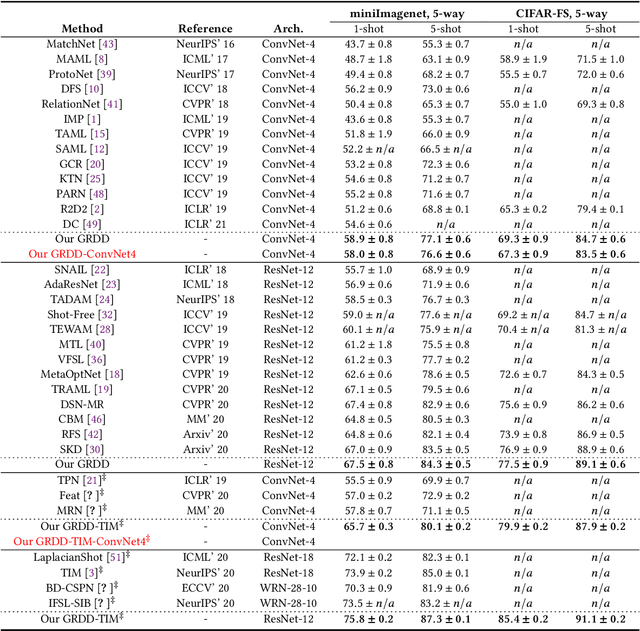
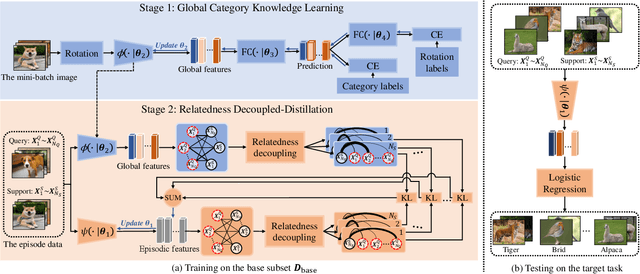
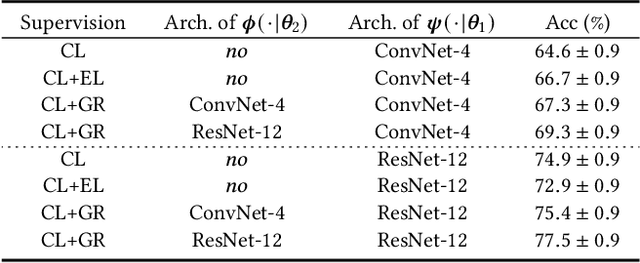
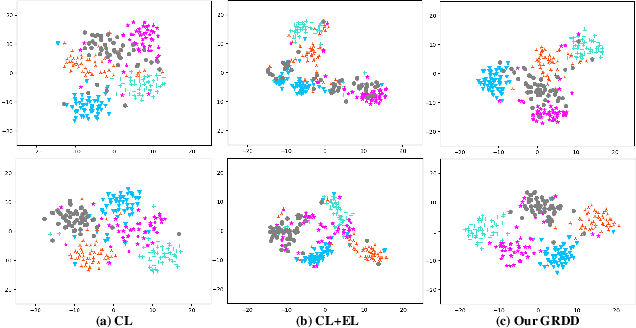
Despite the success that metric learning based approaches have achieved in few-shot learning, recent works reveal the ineffectiveness of their episodic training mode. In this paper, we point out two potential reasons for this problem: 1) the random episodic labels can only provide limited supervision information, while the relatedness information between the query and support samples is not fully exploited; 2) the meta-learner is usually constrained by the limited contextual information of the local episode. To overcome these problems, we propose a new Global Relatedness Decoupled-Distillation (GRDD) method using the global category knowledge and the Relatedness Decoupled-Distillation (RDD) strategy. Our GRDD learns new visual concepts quickly by imitating the habit of humans, i.e. learning from the deep knowledge distilled from the teacher. More specifically, we first train a global learner on the entire base subset using category labels as supervision to leverage the global context information of the categories. Then, the well-trained global learner is used to simulate the query-support relatedness in global dependencies. Finally, the distilled global query-support relatedness is explicitly used to train the meta-learner using the RDD strategy, with the goal of making the meta-learner more discriminative. The RDD strategy aims to decouple the dense query-support relatedness into the groups of sparse decoupled relatedness. Moreover, only the relatedness of a single support sample with other query samples is considered in each group. By distilling the sparse decoupled relatedness group by group, sharper relatedness can be effectively distilled to the meta-learner, thereby facilitating the learning of a discriminative meta-learner. We conduct extensive experiments on the miniImagenet and CIFAR-FS datasets, which show the state-of-the-art performance of our GRDD method.
MCGNet: Partial Multi-view Few-shot Learning via Meta-alignment and Context Gated-aggregation
May 05, 2021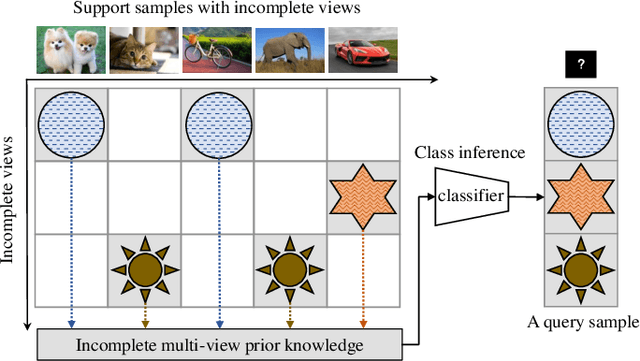

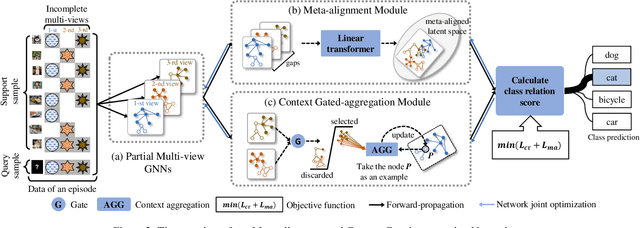
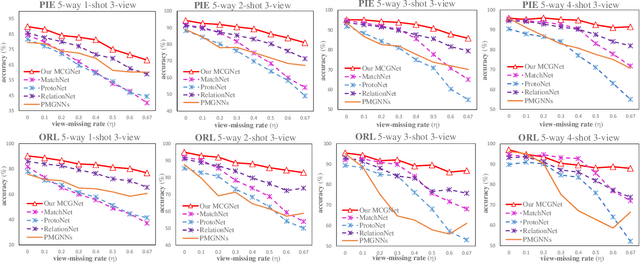
In this paper, we propose a new challenging task named as \textbf{partial multi-view few-shot learning}, which unifies two tasks, i.e. few-shot learning and partial multi-view learning, together. Different from the traditional few-shot learning, this task aims to solve the few-shot learning problem given the incomplete multi-view prior knowledge, which conforms more with the real-world applications. However, this brings about two difficulties within this task. First, the gaps among different views can be large and hard to reduce, especially with sample scarcity. Second, due to the incomplete view information, few-shot learning becomes more challenging than the traditional one. To deal with the above issues, we propose a new \textbf{Meta-alignment and Context Gated-aggregation Network} by equipping meta-alignment and context gated-aggregation with partial multi-view GNNs. Specifically, the meta-alignment effectively maps the features from different views into a more compact latent space, thereby reducing the view gaps. Moreover, the context gated-aggregation alleviates the view-missing influence by leveraging the cross-view context. Extensive experiments are conducted on the PIE and ORL dataset for evaluating our proposed method. By comparing with other few-shot learning methods, our method obtains the state-of-the-art performance especially with heavily-missing views.
Bi-direction Context Propagation Network for Real-time Semantic Segmentation
Jun 02, 2020



Spatial details and context correlations are two types of important information for semantic segmentation. Generally, shallow layers tend to contain more spatial details, while deep layers are rich in context correlations. Aiming to keep both advantages, most of current methods choose to forward-propagate the spatial details from shallow layers to deep layers, which is computationally expensive and substantially lowers the model's execution speed. To address this problem, we propose the Bi-direction Context Propagation Network (BCPNet) by leveraging both spatial and context information. Different from the previous methods, our BCPNet builds bi-directional paths in its network architecture, allowing the backward context propagation and the forward spatial detail propagation simultaneously. Moreover, all the components in the network are kept lightweight. Extensive experiments show that our BCPNet has achieved a good balance between accuracy and speed. For accuracy, our BCPNet has achieved 68.4 \% mIoU on the Cityscapes test set and 67.8 \% mIoU on the CamVid test set. For speed, our BCPNet can achieve 585.9 FPS (or 1.7 ms runtime per image) at $360 \times 640$ size based on a GeForce GTX TITAN X GPU card.