 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskedSpeech: Context-aware Speech Synthesis with Masking Strategy
Nov 11, 2022Humans often speak in a continuous manner which leads to coherent and consistent prosody properties across neighboring utterances. However, most state-of-the-art speech synthesis systems only consider the information within each sentence and ignore the contextual semantic and acoustic features. This makes it inadequate to generate high-quality paragraph-level speech which requires high expressiveness and naturalness. To synthesize natural and expressive speech for a paragraph, a context-aware speech synthesis system named MaskedSpeech is proposed in this paper, which considers both contextual semantic and acoustic features. Inspired by the masking strategy in the speech editing research, the acoustic features of the current sentence are masked out and concatenated with those of contextual speech, and further used as additional model input. The phoneme encoder takes the concatenated phoneme sequence from neighboring sentences as input and learns fine-grained semantic information from contextual text. Furthermore, cross-utterance coarse-grained semantic features are employed to improve the prosody generation. The model is trained to reconstruct the masked acoustic features with the augmentation of both the contextual semantic and acoustic features. Experimental results demonstrate that the proposed MaskedSpeech outperformed the baseline system significantly in terms of naturalness and expressiveness.
Learning latent representations for style control and transfer in end-to-end speech synthesis
Dec 11, 2018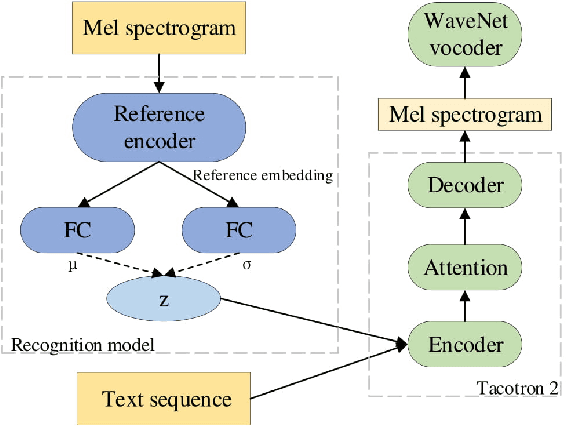


In this paper, we introduce the Variational Autoencoder (VAE) to an end-to-end speech synthesis model, to learn the latent representation of speaking styles in an unsupervised manner. The style representation learned through VAE shows good properties such as disentangling, scaling, and combination, which makes it easy for style control. Style transfer can be achieved in this framework by first inferring style representation through the recognition network of VAE, then feeding it into TTS network to guide the style in synthesizing speech. To avoid Kullback-Leibler (KL) divergence collapse in training, several techniques are adopted. Finally, the proposed model shows good performance of style control and outperforms Global Style Token (GST) model in ABX preference tests on style transfer.