 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRG: Generating Synthetic Relational Databases using GANs
Dec 23, 2023There is an overgrowing demand for data sharing in academia and industry. However, such sharing has issues with personal privacy and data confidentiality. One option is to share only synthetically-generated versions of the real data. Generative Adversarial Network (GAN) is a recently-popular technique that can be used for this purpose. Relational databases usually have multiple tables that are related to each other. So far, the use of GANs has essentially focused on generating single tables. This paper presents Incremental Relational Generator (IRG), which uses GANs to synthetically generate interrelated tables. Given an empirical relational database, IRG can generate a synthetic version that can be safely shared. IRG generates the tables in some sequential order. The key idea is to construct a context, based on the tables generated so far, when using a GAN to generate the next table. Experiments with public datasets and private student data show that IRG outperforms state-of-the-art in terms of statistical properties and query results.
The Role of Federated Learning in a Wireless World with Foundation Models
Oct 06, 2023



Foundation models (FMs) are general-purpose artificial intelligence (AI) models that have recently enabled multiple brand-new generative AI applications. The rapid advances in FMs serve as an important contextual backdrop for the vision of next-generation wireless networks, where federated learning (FL) is a key enabler of distributed network intelligence. Currently, the exploration of the interplay between FMs and FL is still in its nascent stage. Naturally, FMs are capable of boosting the performance of FL, and FL could also leverage decentralized data and computing resources to assist in the training of FMs. However, the exceptionally high requirements that FMs have for computing resources, storage, and communication overhead would pose critical challenges to FL-enabled wireless networks. In this article, we explore the extent to which FMs are suitable for FL over wireless networks, including a broad overview of research challenges and opportunities. In particular, we discuss multiple new paradigms for realizing future intelligent networks that integrate FMs and FL. We also consolidate several broad research directions associated with these paradigms.
MOO: A Methodology for Online Optimization through Mining the Offline Optimum
Mar 22, 2000

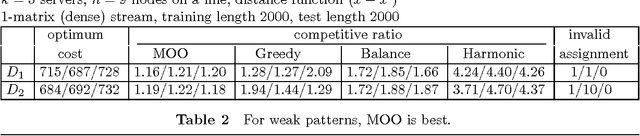
Ports, warehouses and courier services have to decide online how an arriving task is to be served in order that cost is minimized (or profit maximized). These operators have a wealth of historical data on task assignments; can these data be mined for knowledge or rules that can help the decision-making? MOO is a novel application of data mining to online optimization. The idea is to mine (logged) expert decisions or the offline optimum for rules that can be used for online decisions. It requires little knowledge about the task distribution and cost structure, and is applicable to a wide range of problems. This paper presents a feasibility study of the methodology for the well-known k-server problem. Experiments with synthetic data show that optimization can be recast as classification of the optimum decisions; the resulting heuristic can achieve the optimum for strong request patterns, consistently outperforms other heuristics for weak patterns, and is robust despite changes in cost model.