 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOO: A Methodology for Online Optimization through Mining the Offline Optimum
Paper and Code
Mar 22, 2000

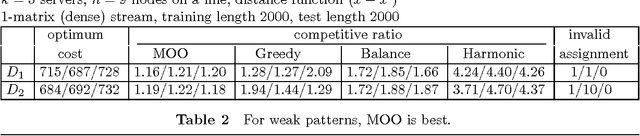
Ports, warehouses and courier services have to decide online how an arriving task is to be served in order that cost is minimized (or profit maximized). These operators have a wealth of historical data on task assignments; can these data be mined for knowledge or rules that can help the decision-making? MOO is a novel application of data mining to online optimization. The idea is to mine (logged) expert decisions or the offline optimum for rules that can be used for online decisions. It requires little knowledge about the task distribution and cost structure, and is applicable to a wide range of problems. This paper presents a feasibility study of the methodology for the well-known k-server problem. Experiments with synthetic data show that optimization can be recast as classification of the optimum decisions; the resulting heuristic can achieve the optimum for strong request patterns, consistently outperforms other heuristics for weak patterns, and is robust despite changes in cost model.