 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Immediate Activation: Temporally Decoupled Backdoor Attacks on Time Series Forecasting
Jan 06, 2026Existing backdoor attacks on multivariate time series (MTS) forecasting enforce strict temporal and dimensional coupling between triggers and target patterns, requiring synchronous activation at fixed positions across variables. However, realistic scenarios often demand delayed and variable-specific activation. We identify this critical unmet need and propose TDBA, a temporally decoupled backdoor attack framework for MTS forecasting. By injecting triggers that encode the expected location of the target pattern, TDBA enables the activation of the target pattern at any positions within the forecasted data, with the activation position flexibly varying across different variable dimensions. TDBA introduces two core modules: (1) a position-guided trigger generation mechanism that leverages smoothed Gaussian priors to generate triggers that are position-related to the predefined target pattern; and (2) a position-aware optimization module that assigns soft weights based on trigger completeness, pattern coverage, and temporal offset, facilitating targeted and stealthy attack optimization. Extensive experiments on real-world datasets show that TDBA consistently outperforms existing baselines in effectiveness while maintaining good stealthiness. Ablation studies confirm the controllability and robustness of its design.
A Machine Learning Approach for Task and Resource Allocation in Mobile Edge Computing Based Networks
Jul 20, 2020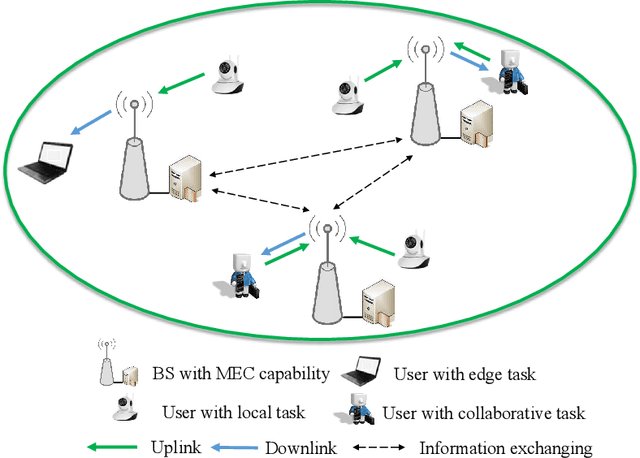



In this paper, a joint task, spectrum, and transmit power allocation problem is investigated for a wireless network in which the base stations (BSs) are equipped with mobile edge computing (MEC) servers to jointly provide computational and communication services to users. Each user can request one computational task from three types of computational tasks. Since the data size of each computational task is different, as the requested computational task varies, the BSs must adjust their resource (subcarrier and transmit power) and task allocation schemes to effectively serve the users. This problem is formulated as an optimization problem whose goal is to minimize the maximal computational and transmission delay among all users. A multi-stack reinforcement learning (RL) algorithm is developed to solve this problem. Using the proposed algorithm, each BS can record the historical resource allocation schemes and users' information in its multiple stacks to avoid learning the same resource allocation scheme and users' states, thus improving the convergence speed and learning efficiency. Simulation results illustrate that the proposed algorithm can reduce the number of iterations needed for convergence and the maximal delay among all users by up to 18% and 11.1% compared to the standard Q-learning algorithm.