 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovariance Regularization for Probabilistic Linear Discriminant Analysis
Dec 06, 2022Probabilistic linear discriminant analysis (PLDA) is commonly used in speaker verification systems to score the similarity of speaker embeddings. Recent studies improved the performance of PLDA in domain-matched conditions by diagonalizing its covariance. We suspect such brutal pruning approach could eliminate its capacity in modeling dimension correlation of speaker embeddings, leading to inadequate performance with domain adaptation. This paper explores two alternative covariance regularization approaches, namely, interpolated PLDA and sparse PLDA, to tackle the problem. The interpolated PLDA incorporates the prior knowledge from cosine scoring to interpolate the covariance of PLDA. The sparse PLDA introduces a sparsity penalty to update the covariance. Experimental results demonstrate that both approaches outperform diagonal regularization noticeably with domain adaptation. In addition, in-domain data can be significantly reduced when training sparse PLDA for domain adaptation.
Label-free Knowledge Distillation with Contrastive Loss for Light-weight Speaker Recognition
Dec 06, 2022Very deep models for speaker recognition (SR) have demonstrated remarkable performance improvement in recent research. However, it is impractical to deploy these models for on-device applications with constrained computational resources. On the other hand, light-weight models are highly desired in practice despite their sub-optimal performance. This research aims to improve light-weight SR models through large-scale label-free knowledge distillation (KD). Existing KD approaches for SR typically require speaker labels to learn task-specific knowledge, due to the inefficiency of conventional loss for distillation. To address the inefficiency problem and achieve label-free KD, we propose to employ the contrastive loss from self-supervised learning for distillation. Extensive experiments are conducted on a collection of public speech datasets from diverse sources. Results on light-weight SR models show that the proposed approach of label-free KD with contrastive loss consistently outperforms both conventional distillation methods and self-supervised learning methods by a significant margin.
Unifying Cosine and PLDA Back-ends for Speaker Verification
Apr 22, 2022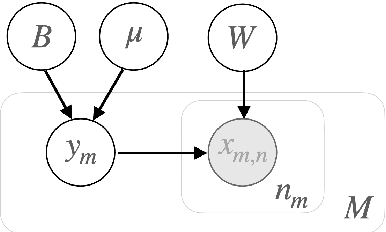
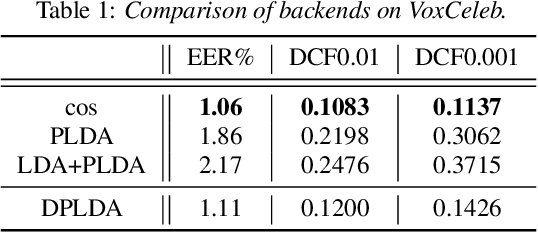
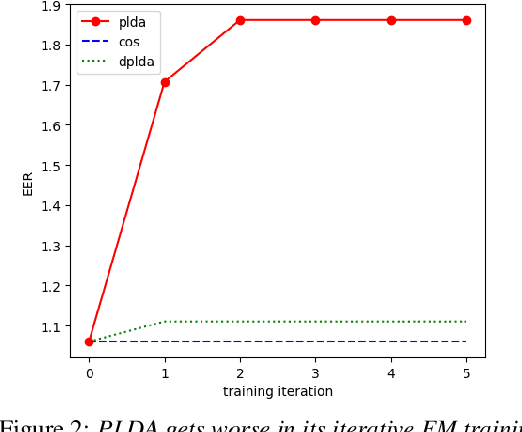

State-of-art speaker verification (SV) systems use a back-end model to score the similarity of speaker embeddings extracted from a neural network model. The commonly used back-end models are the cosine scoring and the probabilistic linear discriminant analysis (PLDA) scoring. With the recently developed neural embeddings, the theoretically more appealing PLDA approach is found to have no advantage against or even be inferior the simple cosine scoring in terms of SV system performance. This paper presents an investigation on the relation between the two scoring approaches, aiming to explain the above counter-intuitive observation. It is shown that the cosine scoring is essentially a special case of PLDA scoring. In other words, by properly setting the parameters of PLDA, the two back-ends become equivalent. As a consequence, the cosine scoring not only inherits the basic assumptions for the PLDA but also introduces additional assumptions on the properties of input embeddings. Experiments show that the dimensional independence assumption required by the cosine scoring contributes most to the performance gap between the two methods under the domain-matched condition. When there is severe domain mismatch and the dimensional independence assumption does not hold, the PLDA would perform better than the cosine for domain adaptation.
Learning Speaker Embedding with Momentum Contrast
Jan 07, 2020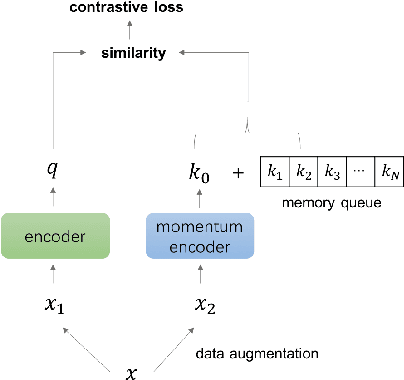
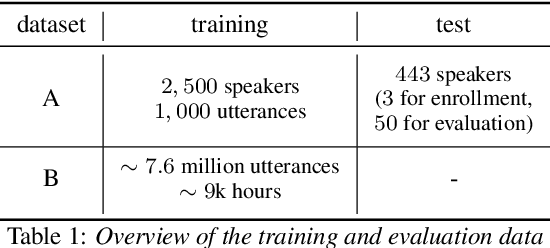
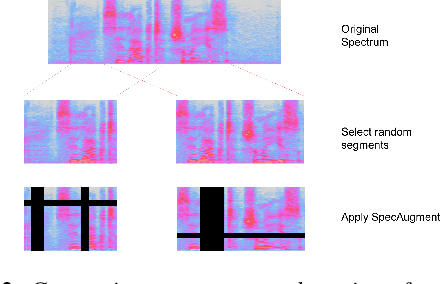

Speaker verification can be formulated as a representation learning task, where speaker-discriminative embeddings are extracted from utterances of variable lengths. Momentum Contrast (MoCo) is a recently proposed unsupervised representation learning framework, and has shown its effectiveness for learning good feature representation for downstream vision tasks. In this work, we apply MoCo to learn speaker embedding from speech segments. We explore MoCo for both unsupervised learning and pretraining settings. In the unsupervised scenario, embedding is learned by MoCo from audio data without using any speaker specific information. On a large scale dataset with $2,500$ speakers, MoCo can achieve EER $4.275\%$ trained unsupervisedly, and the EER can decrease further to $3.58\%$ if extra unlabelled data are used. In the pretraining scenario, encoder trained by MoCo is used to initialize the downstream supervised training. With finetuning on the MoCo trained model, the equal error rate (EER) reduces $13.7\%$ relative ($1.44\%$ to $1.242\%$) compared to a carefully tuned baseline training from scratch. Comparative study confirms the effectiveness of MoCo learning good speaker embedding.