 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Cosine and PLDA Back-ends for Speaker Verification
Paper and Code
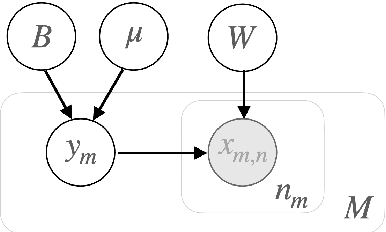
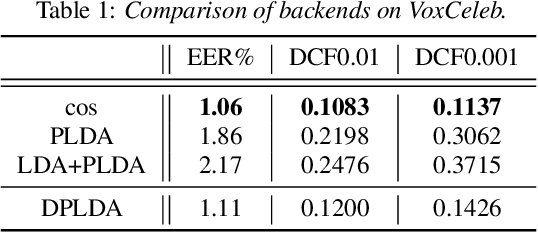
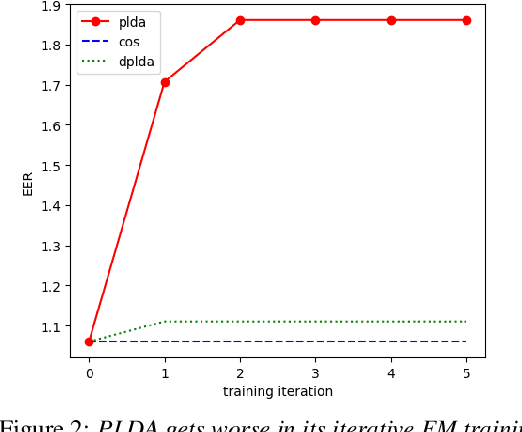

State-of-art speaker verification (SV) systems use a back-end model to score the similarity of speaker embeddings extracted from a neural network model. The commonly used back-end models are the cosine scoring and the probabilistic linear discriminant analysis (PLDA) scoring. With the recently developed neural embeddings, the theoretically more appealing PLDA approach is found to have no advantage against or even be inferior the simple cosine scoring in terms of SV system performance. This paper presents an investigation on the relation between the two scoring approaches, aiming to explain the above counter-intuitive observation. It is shown that the cosine scoring is essentially a special case of PLDA scoring. In other words, by properly setting the parameters of PLDA, the two back-ends become equivalent. As a consequence, the cosine scoring not only inherits the basic assumptions for the PLDA but also introduces additional assumptions on the properties of input embeddings. Experiments show that the dimensional independence assumption required by the cosine scoring contributes most to the performance gap between the two methods under the domain-matched condition. When there is severe domain mismatch and the dimensional independence assumption does not hold, the PLDA would perform better than the cosine for domain adaptation.