 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Assisted Sub-Prototype Mining for Universal Domain Adaptation
Oct 09, 2023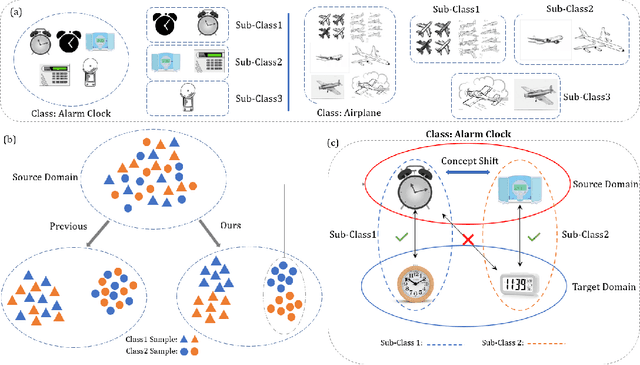
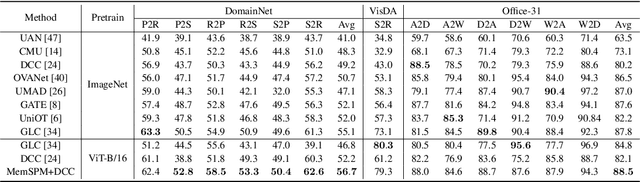
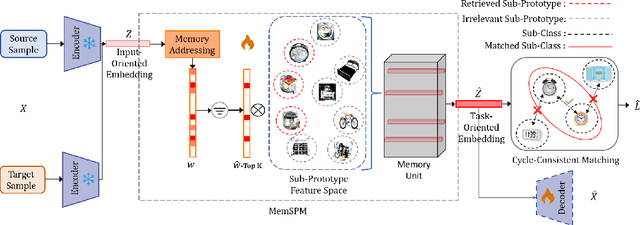
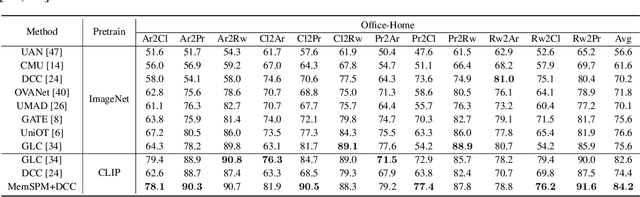
Universal domain adaptation aims to align the classes and reduce the feature gap between the same category of the source and target domains. The target private category is set as the unknown class during the adaptation process, as it is not included in the source domain. However, most existing methods overlook the intra-class structure within a category, especially in cases where there exists significant concept shift between the samples belonging to the same category. When samples with large concept shift are forced to be pushed together, it may negatively affect the adaptation performance. Moreover, from the interpretability aspect, it is unreasonable to align visual features with significant differences, such as fighter jets and civil aircraft, into the same category. Unfortunately, due to such semantic ambiguity and annotation cost, categories are not always classified in detail, making it difficult for the model to perform precise adaptation. To address these issues, we propose a novel Memory-Assisted Sub-Prototype Mining (MemSPM) method that can learn the differences between samples belonging to the same category and mine sub-classes when there exists significant concept shift between them. By doing so, our model learns a more reasonable feature space that enhances the transferability and reflects the inherent differences among samples annotated as the same category. We evaluate the effectiveness of our MemSPM method over multiple scenarios, including UniDA, OSDA, and PDA. Our method achieves state-of-the-art performance on four benchmarks in most cases.
COCA: Classifier-Oriented Calibration for Source-Free Universal Domain Adaptation via Textual Prototype
Aug 21, 2023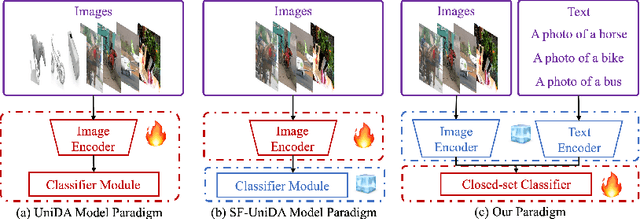
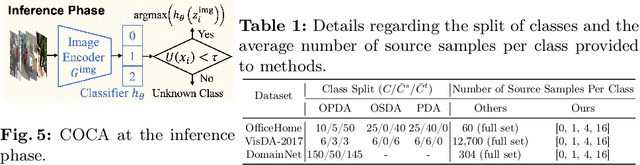
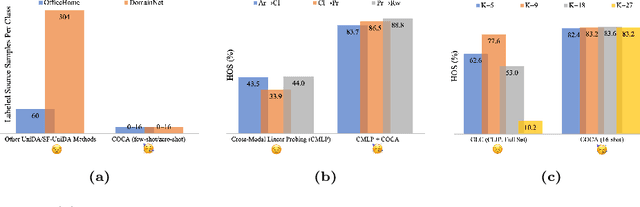
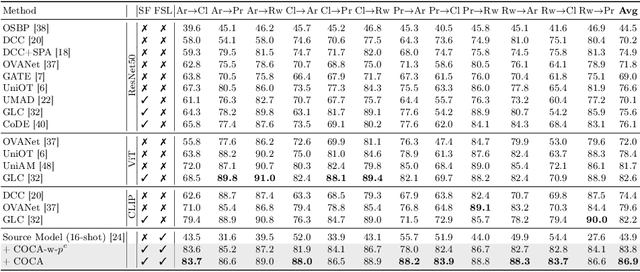
Universal Domain Adaptation (UniDA) aims to distinguish common and private classes between the source and target domains where domain shift exists. Recently, due to more stringent data restrictions, researchers have introduced Source-Free UniDA (SF-UniDA) in more realistic scenarios. SF-UniDA methods eliminate the need for direct access to source samples when performing adaptation to the target domain. However, existing SF-UniDA methods still require an extensive quantity of labeled source samples to train a source model, resulting in significant labeling costs. To tackle this issue, we present a novel Classifier-Oriented Calibration (COCA) method. This method, which leverages textual prototypes, is formulated for the source model based on few-shot learning. Specifically, we propose studying few-shot learning, usually explored for closed-set scenarios, to identify common and domain-private classes despite a significant domain shift between source and target domains. Essentially, we present a novel paradigm based on the vision-language model to learn SF-UniDA and hugely reduce the labeling costs on the source domain. Experimental results demonstrate that our approach outperforms state-of-the-art UniDA and SF-UniDA models.
Self-Paced Learning for Open-Set Domain Adaptation
Mar 21, 2023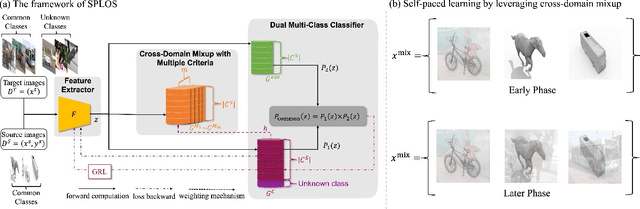
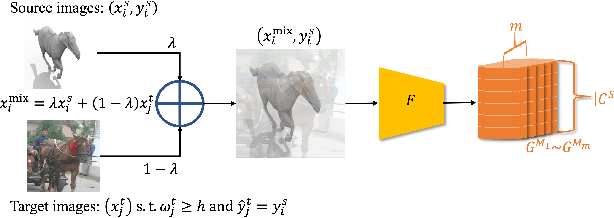
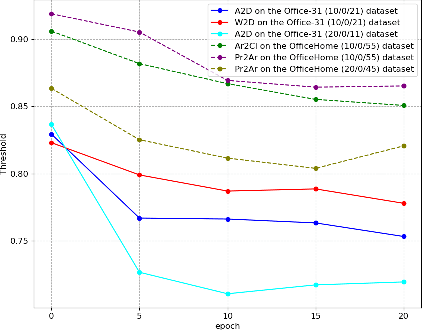
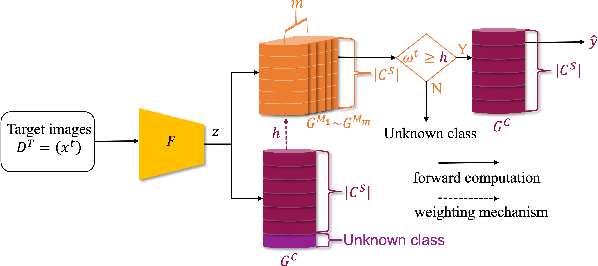
Domain adaptation tackles the challenge of generalizing knowledge acquired from a source domain to a target domain with different data distributions. Traditional domain adaptation methods presume that the classes in the source and target domains are identical, which is not always the case in real-world scenarios. Open-set domain adaptation (OSDA) addresses this limitation by allowing previously unseen classes in the target domain. Open-set domain adaptation aims to not only recognize target samples belonging to common classes shared by source and target domains but also perceive unknown class samples. We propose a novel framework based on self-paced learning to distinguish common and unknown class samples precisely, referred to as SPLOS (self-paced learning for open-set). To utilize unlabeled target samples for self-paced learning, we generate pseudo labels and design a cross-domain mixup method tailored for OSDA scenarios. This strategy minimizes the noise from pseudo labels and ensures our model progressively learns common class features of the target domain, beginning with simpler examples and advancing to more complex ones. Furthermore, unlike existing OSDA methods that require manual hyperparameter $threshold$ tuning to separate common and unknown classes, our approach self-tunes a suitable threshold, eliminating the need for empirical tuning during testing. Comprehensive experiments illustrate that our method consistently achieves superior performance on different benchmarks compared with various state-of-the-art methods.