 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOCA: Classifier-Oriented Calibration for Source-Free Universal Domain Adaptation via Textual Prototype
Paper and Code
Aug 21, 2023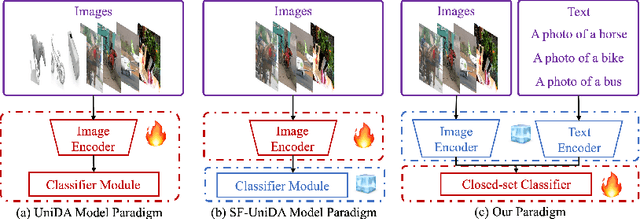
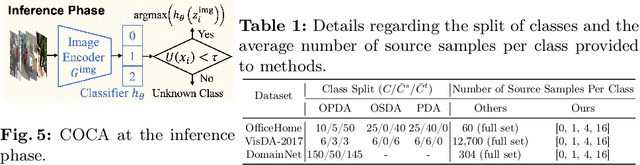
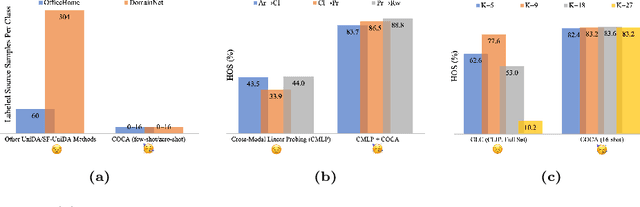
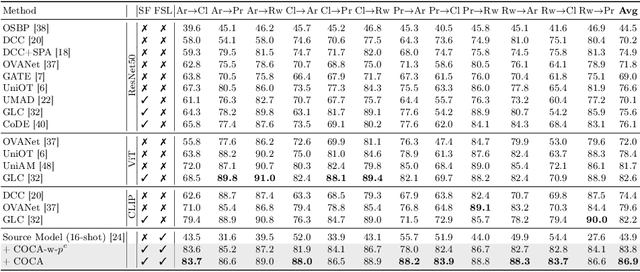
Universal Domain Adaptation (UniDA) aims to distinguish common and private classes between the source and target domains where domain shift exists. Recently, due to more stringent data restrictions, researchers have introduced Source-Free UniDA (SF-UniDA) in more realistic scenarios. SF-UniDA methods eliminate the need for direct access to source samples when performing adaptation to the target domain. However, existing SF-UniDA methods still require an extensive quantity of labeled source samples to train a source model, resulting in significant labeling costs. To tackle this issue, we present a novel Classifier-Oriented Calibration (COCA) method. This method, which leverages textual prototypes, is formulated for the source model based on few-shot learning. Specifically, we propose studying few-shot learning, usually explored for closed-set scenarios, to identify common and domain-private classes despite a significant domain shift between source and target domains. Essentially, we present a novel paradigm based on the vision-language model to learn SF-UniDA and hugely reduce the labeling costs on the source domain. Experimental results demonstrate that our approach outperforms state-of-the-art UniDA and SF-UniDA models.