 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Kernel Quantile Learning with Random Features
Aug 24, 2024The random feature (RF) approach is a well-established and efficient tool for scalable kernel methods, but existing literature has primarily focused on kernel ridge regression with random features (KRR-RF), which has limitations in handling heterogeneous data with heavy-tailed noises. This paper presents a generalization study of kernel quantile regression with random features (KQR-RF), which accounts for the non-smoothness of the check loss in KQR-RF by introducing a refined error decomposition and establishing a novel connection between KQR-RF and KRR-RF. Our study establishes the capacity-dependent learning rates for KQR-RF under mild conditions on the number of RFs, which are minimax optimal up to some logarithmic factors. Importantly, our theoretical results, utilizing a data-dependent sampling strategy, can be extended to cover the agnostic setting where the target quantile function may not precisely align with the assumed kernel space. By slightly modifying our assumptions, the capacity-dependent error analysis can also be applied to cases with Lipschitz continuous losses, enabling broader applications in the machine learning community. To validate our theoretical findings, simulated experiments and a real data application are conducted.
Minimax Optimal Transfer Learning for Kernel-based Nonparametric Regression
Oct 21, 2023



In recent years, transfer learning has garnered significant attention in the machine learning community. Its ability to leverage knowledge from related studies to improve generalization performance in a target study has made it highly appealing. This paper focuses on investigating the transfer learning problem within the context of nonparametric regression over a reproducing kernel Hilbert space. The aim is to bridge the gap between practical effectiveness and theoretical guarantees. We specifically consider two scenarios: one where the transferable sources are known and another where they are unknown. For the known transferable source case, we propose a two-step kernel-based estimator by solely using kernel ridge regression. For the unknown case, we develop a novel method based on an efficient aggregation algorithm, which can automatically detect and alleviate the effects of negative sources. This paper provides the statistical properties of the desired estimators and establishes the minimax optimal rate. Through extensive numerical experiments on synthetic data and real examples, we validate our theoretical findings and demonstrate the effectiveness of our proposed method.
Towards a Unified Analysis of Kernel-based Methods Under Covariate Shift
Oct 19, 2023Covariate shift occurs prevalently in practice, where the input distributions of the source and target data are substantially different. Despite its practical importance in various learning problems, most of the existing methods only focus on some specific learning tasks and are not well validated theoretically and numerically. To tackle this problem, we propose a unified analysis of general nonparametric methods in a reproducing kernel Hilbert space (RKHS) under covariate shift. Our theoretical results are established for a general loss belonging to a rich loss function family, which includes many commonly used methods as special cases, such as mean regression, quantile regression, likelihood-based classification, and margin-based classification. Two types of covariate shift problems are the focus of this paper and the sharp convergence rates are established for a general loss function to provide a unified theoretical analysis, which concurs with the optimal results in literature where the squared loss is used. Extensive numerical studies on synthetic and real examples confirm our theoretical findings and further illustrate the effectiveness of our proposed method.
Relative Entropy Gradient Sampler for Unnormalized Distributions
Oct 06, 2021
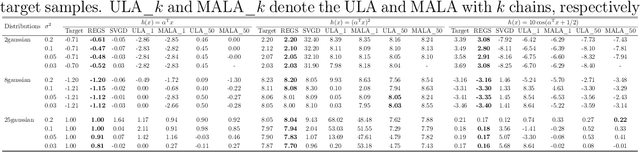
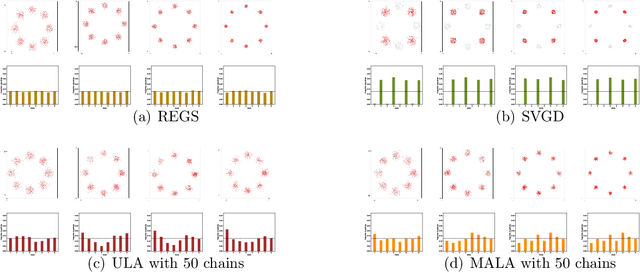
We propose a relative entropy gradient sampler (REGS) for sampling from unnormalized distributions. REGS is a particle method that seeks a sequence of simple nonlinear transforms iteratively pushing the initial samples from a reference distribution into the samples from an unnormalized target distribution. To determine the nonlinear transforms at each iteration, we consider the Wasserstein gradient flow of relative entropy. This gradient flow determines a path of probability distributions that interpolates the reference distribution and the target distribution. It is characterized by an ODE system with velocity fields depending on the density ratios of the density of evolving particles and the unnormalized target density. To sample with REGS, we need to estimate the density ratios and simulate the ODE system with particle evolution. We propose a novel nonparametric approach to estimating the logarithmic density ratio using neural networks. Extensive simulation studies on challenging multimodal 1D and 2D mixture distributions and Bayesian logistic regression on real datasets demonstrate that the REGS outperforms the state-of-the-art sampling methods included in the comparison.
Metric learning by Similarity Network for Deep Semi-Supervised Learning
Apr 29, 2020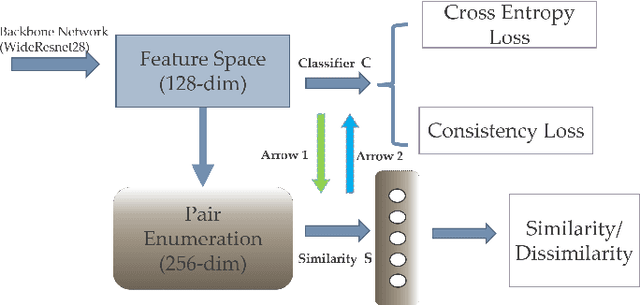
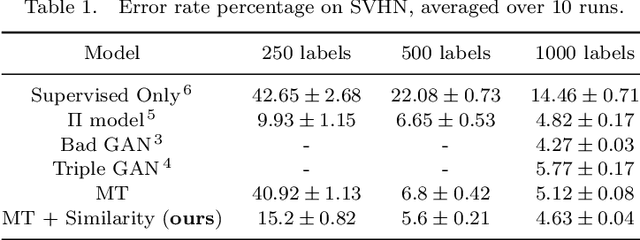

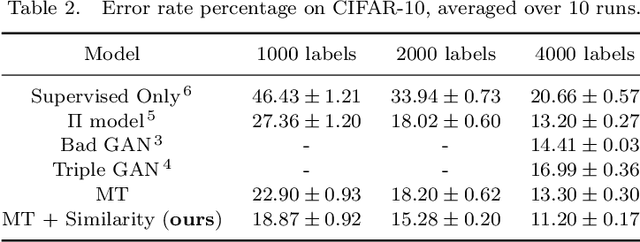
Deep semi-supervised learning has been widely implemented in the real-world due to the rapid development of deep learning. Recently, attention has shifted to the approaches such as Mean-Teacher to penalize the inconsistency between two perturbed input sets. Although these methods may achieve positive results, they ignore the relationship information between data instances. To solve this problem, we propose a novel method named Metric Learning by Similarity Network (MLSN), which aims to learn a distance metric adaptively on different domains. By co-training with the classification network, similarity network can learn more information about pairwise relationships and performs better on some empirical tasks than state-of-art methods.