 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNewSum: A Large-scale Chinese News Summarization Dataset with Human-annotated Adequacy and Deducibility Level
Oct 21, 2021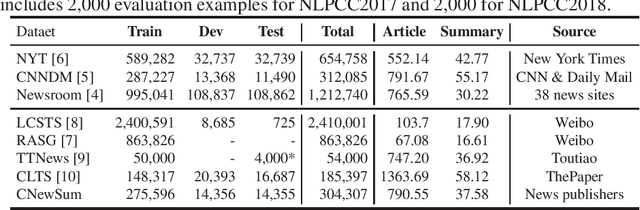
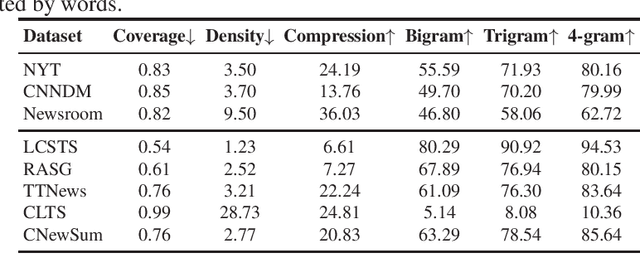
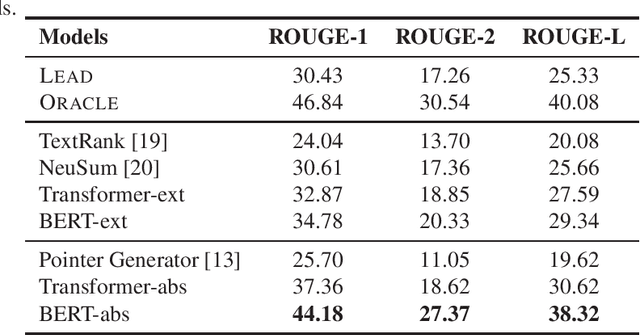
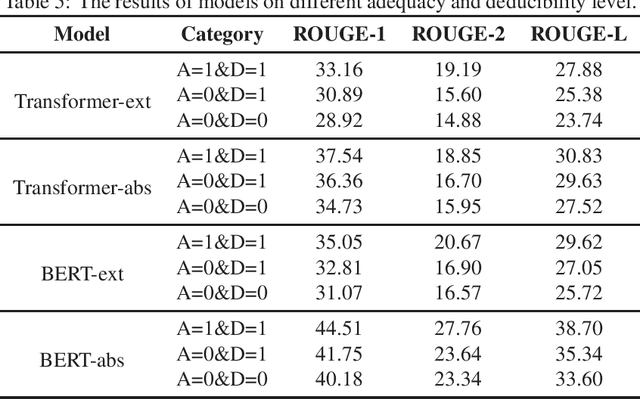
Automatic text summarization aims to produce a brief but crucial summary for the input documents. Both extractive and abstractive methods have witnessed great success in English datasets in recent years. However, there has been a minimal exploration of text summarization in Chinese, limited by the lack of large-scale datasets. In this paper, we present a large-scale Chinese news summarization dataset CNewSum, which consists of 304,307 documents and human-written summaries for the news feed. It has long documents with high-abstractive summaries, which can encourage document-level understanding and generation for current summarization models. An additional distinguishing feature of CNewSum is that its test set contains adequacy and deducibility annotations for the summaries. The adequacy level measures the degree of summary information covered by the document, and the deducibility indicates the reasoning ability the model needs to generate the summary. These annotations can help researchers analyze and target their model performance bottleneck. We examine recent methods on CNewSum and release our dataset to provide a solid testbed for automatic Chinese summarization research.
MTG: A Benchmarking Suite for Multilingual Text Generation
Aug 13, 2021

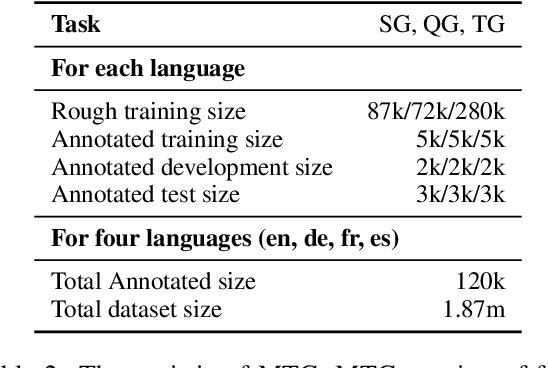
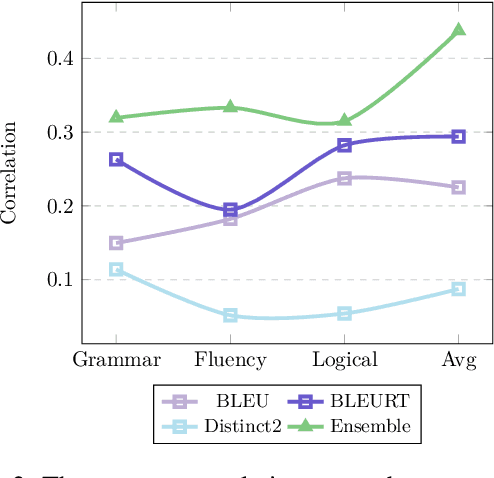
We introduce MTG, a new benchmark suite for training and evaluating multilingual text generation. It is the first and largest text generation benchmark with 120k human-annotated multi-way parallel data for three tasks (story generation, question generation, and title generation) across four languages (English, German, French, and Spanish). Based on it, we set various evaluation scenarios and make a deep analysis of several popular multilingual generation models from different aspects. Our benchmark suite will encourage the multilingualism for text generation community with more human-annotated parallel data and more diverse generation scenarios.