 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCL4Rec: Contrast over Contrastive Learning for Micro-video Recommendation
Aug 17, 2022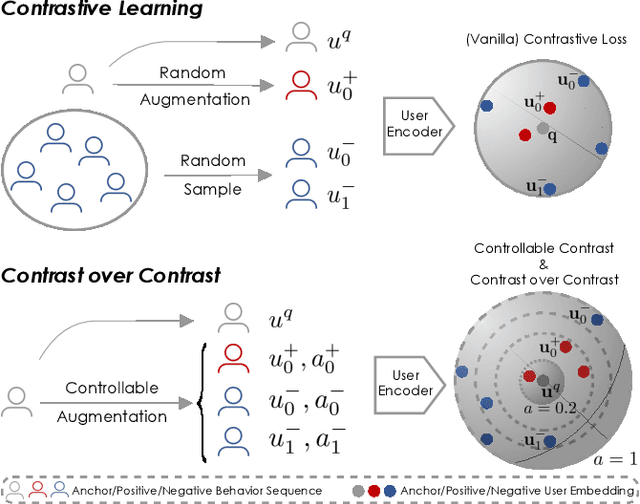

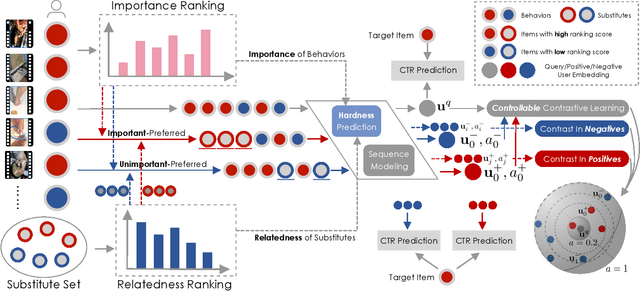
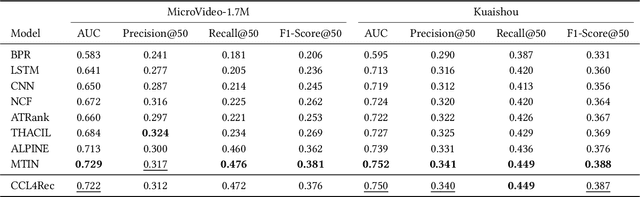
Micro-video recommender systems suffer from the ubiquitous noises in users' behaviors, which might render the learned user representation indiscriminating, and lead to trivial recommendations (e.g., popular items) or even weird ones that are far beyond users' interests. Contrastive learning is an emergent technique for learning discriminating representations with random data augmentations. However, due to neglecting the noises in user behaviors and treating all augmented samples equally, the existing contrastive learning framework is insufficient for learning discriminating user representations in recommendation. To bridge this research gap, we propose the Contrast over Contrastive Learning framework for training recommender models, named CCL4Rec, which models the nuances of different augmented views by further contrasting augmented positives/negatives with adaptive pulling/pushing strengths, i.e., the contrast over (vanilla) contrastive learning. To accommodate these contrasts, we devise the hardness-aware augmentations that track the importance of behaviors being replaced in the query user and the relatedness of substitutes, and thus determining the quality of augmented positives/negatives. The hardness-aware augmentation also permits controllable contrastive learning, leading to performance gains and robust training. In this way, CCL4Rec captures the nuances of historical behaviors for a given user, which explicitly shields off the learned user representation from the effects of noisy behaviors. We conduct extensive experiments on two micro-video recommendation benchmarks, which demonstrate that CCL4Rec with far less model parameters could achieve comparable performance to existing state-of-the-art method, and improve the training/inference speed by several orders of magnitude.
Modeling High-order Interactions across Multi-interests for Micro-video Reommendation
Apr 01, 2021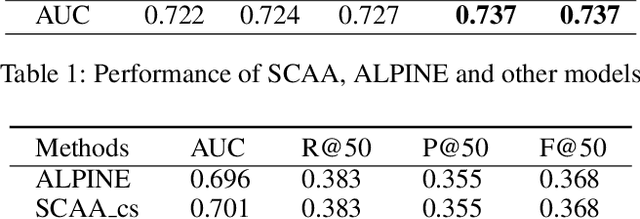
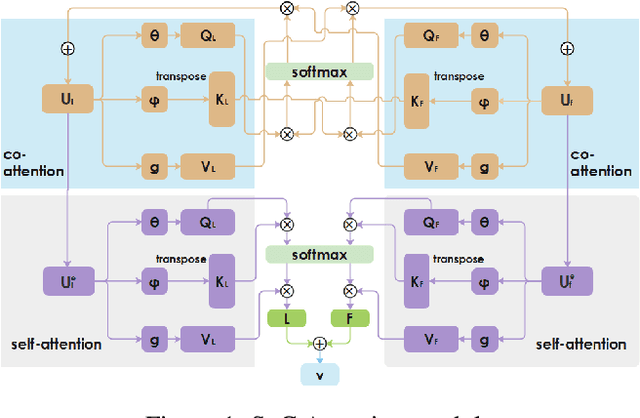
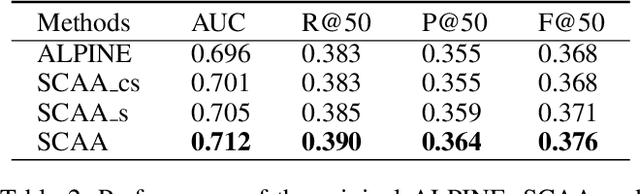
Personalized recommendation system has become pervasive in various video platform. Many effective methods have been proposed, but most of them didn't capture the user's multi-level interest trait and dependencies between their viewed micro-videos well. To solve these problems, we propose a Self-over-Co Attention module to enhance user's interest representation. In particular, we first use co-attention to model correlation patterns across different levels and then use self-attention to model correlation patterns within a specific level. Experimental results on filtered public datasets verify that our presented module is useful.