 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRformer: Pyramidal Recurrent Transformer for Multivariate Time Series Forecasting
Aug 20, 2024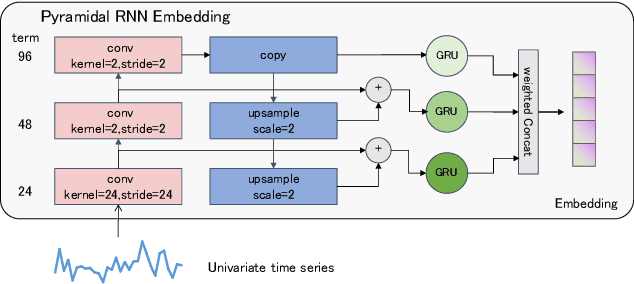
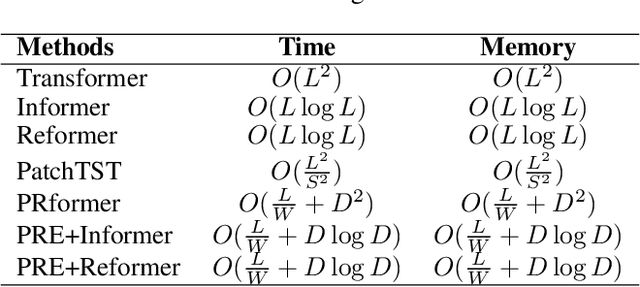
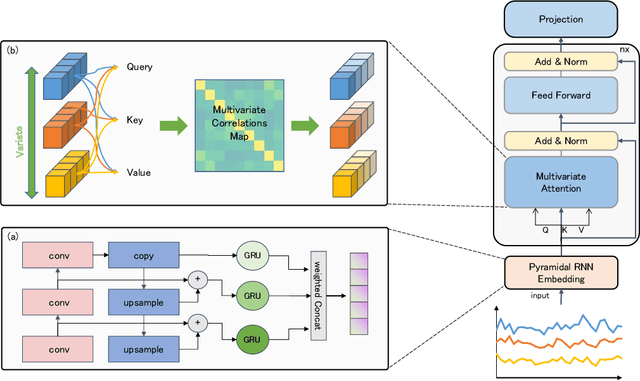

The self-attention mechanism in Transformer architecture, invariant to sequence order, necessitates positional embeddings to encode temporal order in time series prediction. We argue that this reliance on positional embeddings restricts the Transformer's ability to effectively represent temporal sequences, particularly when employing longer lookback windows. To address this, we introduce an innovative approach that combines Pyramid RNN embeddings(PRE) for univariate time series with the Transformer's capability to model multivariate dependencies. PRE, utilizing pyramidal one-dimensional convolutional layers, constructs multiscale convolutional features that preserve temporal order. Additionally, RNNs, layered atop these features, learn multiscale time series representations sensitive to sequence order. This integration into Transformer models with attention mechanisms results in significant performance enhancements. We present the PRformer, a model integrating PRE with a standard Transformer encoder, demonstrating state-of-the-art performance on various real-world datasets. This performance highlights the effectiveness of our approach in leveraging longer lookback windows and underscores the critical role of robust temporal representations in maximizing Transformer's potential for prediction tasks. Code is available at this repository: \url{https://github.com/usualheart/PRformer}.
Adaptive Fuzzy C-Means with Graph Embedding
May 22, 2024Fuzzy clustering algorithms can be roughly categorized into two main groups: Fuzzy C-Means (FCM) based methods and mixture model based methods. However, for almost all existing FCM based methods, how to automatically selecting proper membership degree hyper-parameter values remains a challenging and unsolved problem. Mixture model based methods, while circumventing the difficulty of manually adjusting membership degree hyper-parameters inherent in FCM based methods, often have a preference for specific distributions, such as the Gaussian distribution. In this paper, we propose a novel FCM based clustering model that is capable of automatically learning an appropriate membership degree hyper-parameter value and handling data with non-Gaussian clusters. Moreover, by removing the graph embedding regularization, the proposed FCM model can degenerate into the simplified generalized Gaussian mixture model. Therefore, the proposed FCM model can be also seen as the generalized Gaussian mixture model with graph embedding. Extensive experiments are conducted on both synthetic and real-world datasets to demonstrate the effectiveness of the proposed model.
Feature Learning Viewpoint of AdaBoost and a New Algorithm
Apr 08, 2019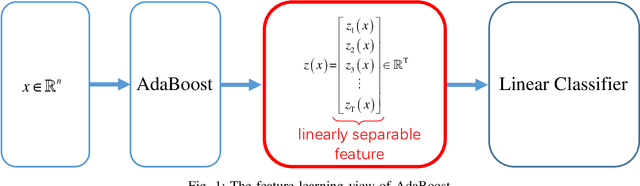
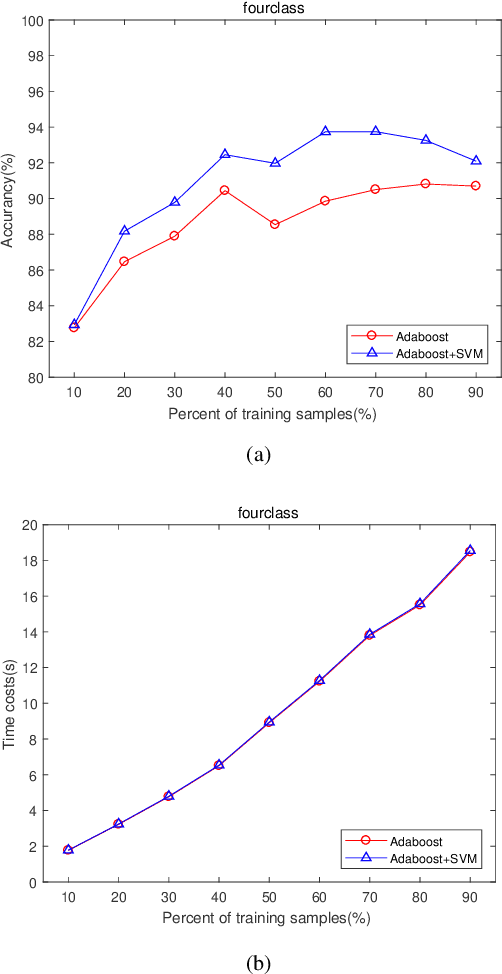
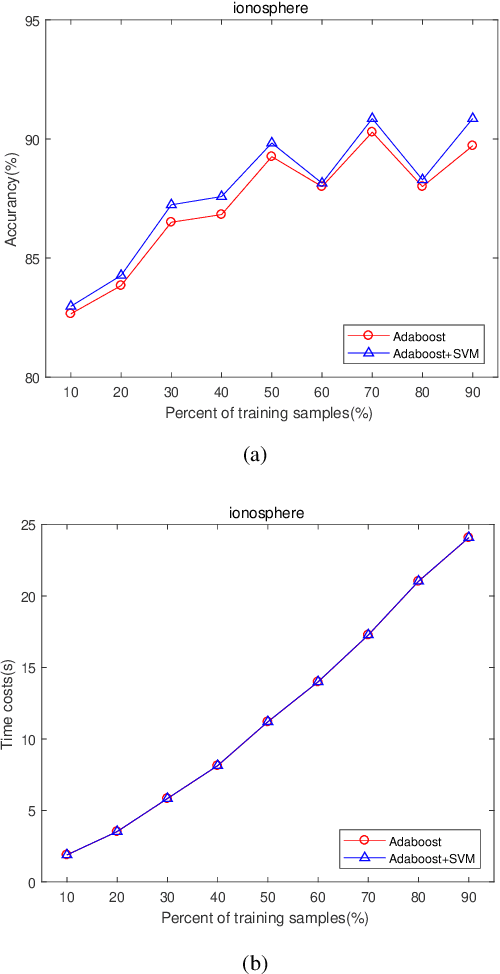
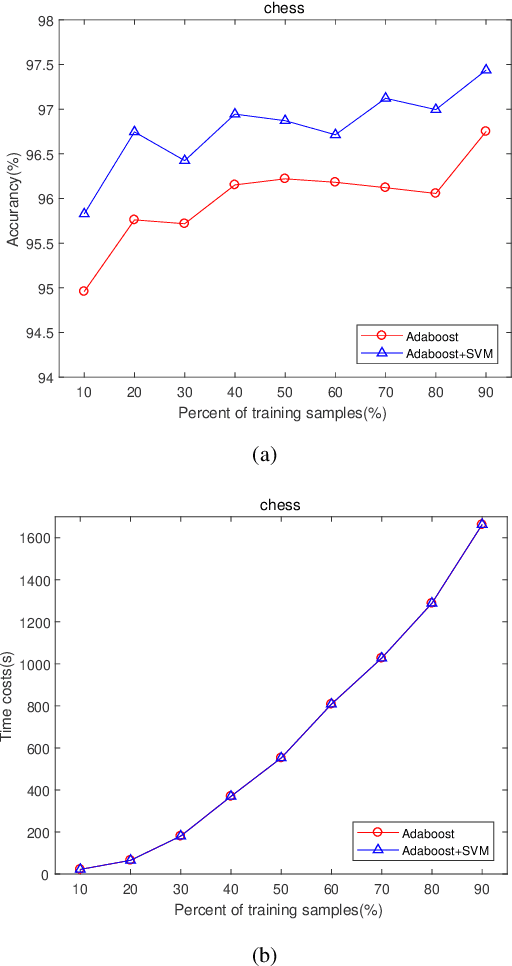
The AdaBoost algorithm has the superiority of resisting overfitting. Understanding the mysteries of this phenomena is a very fascinating fundamental theoretical problem. Many studies are devoted to explaining it from statistical view and margin theory. In this paper, we illustrate it from feature learning viewpoint, and propose the AdaBoost+SVM algorithm, which can explain the resistant to overfitting of AdaBoost directly and easily to understand. Firstly, we adopt the AdaBoost algorithm to learn the base classifiers. Then, instead of directly weighted combination the base classifiers, we regard them as features and input them to SVM classifier. With this, the new coefficient and bias can be obtained, which can be used to construct the final classifier. We explain the rationality of this and illustrate the theorem that when the dimension of these features increases, the performance of SVM would not be worse, which can explain the resistant to overfitting of AdaBoost.