 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Foundation Models for Process Model Forecasting
Dec 08, 2025



Process Model Forecasting (PMF) aims to predict how the control-flow structure of a process evolves over time by modeling the temporal dynamics of directly-follows (DF) relations, complementing predictive process monitoring that focuses on single-case prefixes. Prior benchmarks show that machine learning and deep learning models provide only modest gains over statistical baselines, mainly due to the sparsity and heterogeneity of the DF time series. We investigate Time Series Foundation Models (TSFMs), large pre-trained models for generic time series, as an alternative for PMF. Using DF time series derived from real-life event logs, we compare zero-shot use of TSFMs, without additional training, with fine-tuned variants adapted on PMF-specific data. TSFMs generally achieve lower forecasting errors (MAE and RMSE) than traditional and specialized models trained from scratch on the same logs, indicating effective transfer of temporal structure from non-process domains. While fine-tuning can further improve accuracy, the gains are often small and may disappear on smaller or more complex datasets, so zero-shot use remains a strong default. Our study highlights the generalization capability and data efficiency of TSFMs for process-related time series and, to the best of our knowledge, provides the first systematic evaluation of temporal foundation models for PMF.
PRformer: Pyramidal Recurrent Transformer for Multivariate Time Series Forecasting
Aug 20, 2024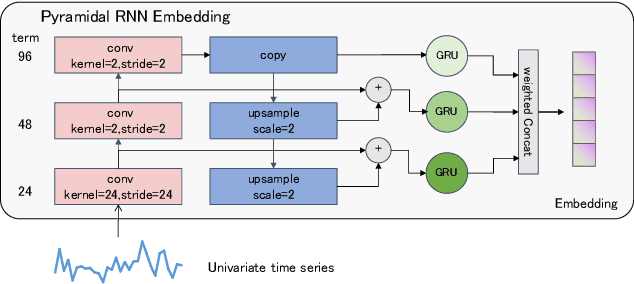
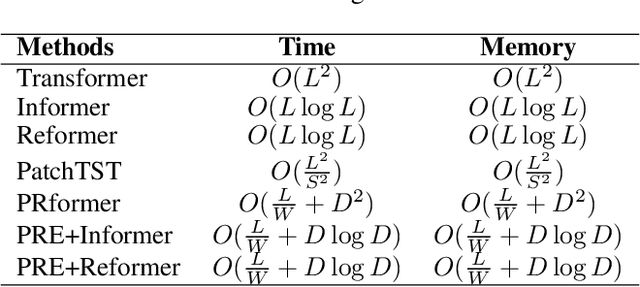
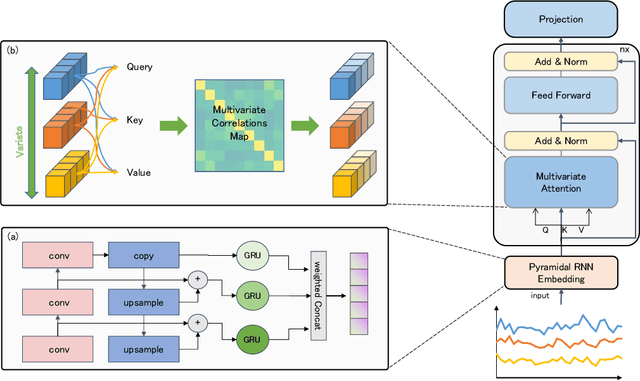

The self-attention mechanism in Transformer architecture, invariant to sequence order, necessitates positional embeddings to encode temporal order in time series prediction. We argue that this reliance on positional embeddings restricts the Transformer's ability to effectively represent temporal sequences, particularly when employing longer lookback windows. To address this, we introduce an innovative approach that combines Pyramid RNN embeddings(PRE) for univariate time series with the Transformer's capability to model multivariate dependencies. PRE, utilizing pyramidal one-dimensional convolutional layers, constructs multiscale convolutional features that preserve temporal order. Additionally, RNNs, layered atop these features, learn multiscale time series representations sensitive to sequence order. This integration into Transformer models with attention mechanisms results in significant performance enhancements. We present the PRformer, a model integrating PRE with a standard Transformer encoder, demonstrating state-of-the-art performance on various real-world datasets. This performance highlights the effectiveness of our approach in leveraging longer lookback windows and underscores the critical role of robust temporal representations in maximizing Transformer's potential for prediction tasks. Code is available at this repository: \url{https://github.com/usualheart/PRformer}.
Network Embedding via Deep Prediction Model
Apr 27, 2021
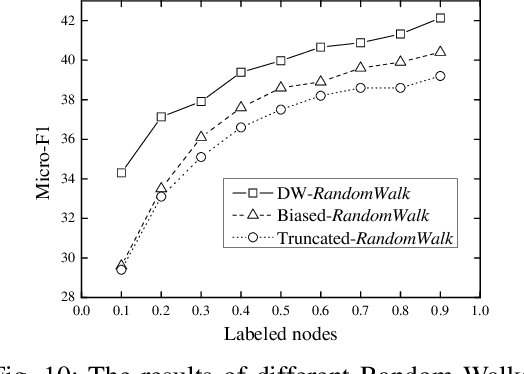

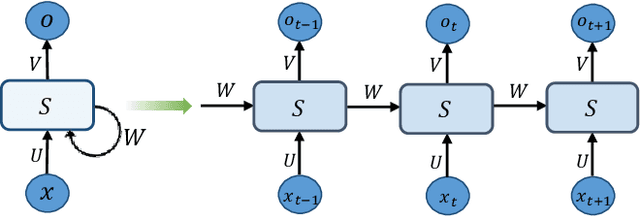
Network-structured data becomes ubiquitous in daily life and is growing at a rapid pace. It presents great challenges to feature engineering due to the high non-linearity and sparsity of the data. The local and global structure of the real-world networks can be reflected by dynamical transfer behaviors among nodes. This paper proposes a network embedding framework to capture the transfer behaviors on structured networks via deep prediction models. We first design a degree-weight biased random walk model to capture the transfer behaviors on the network. Then a deep network embedding method is introduced to preserve the transfer possibilities among the nodes. A network structure embedding layer is added into conventional deep prediction models, including Long Short-Term Memory Network and Recurrent Neural Network, to utilize the sequence prediction ability. To keep the local network neighborhood, we further perform a Laplacian supervised space optimization on the embedding feature representations. Experimental studies are conducted on various datasets including social networks, citation networks, biomedical network, collaboration network and language network. The results show that the learned representations can be effectively used as features in a variety of tasks, such as clustering, visualization, classification, reconstruction and link prediction, and achieve promising performance compared with state-of-the-arts.