 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Learning Viewpoint of AdaBoost and a New Algorithm
Paper and Code
Apr 08, 2019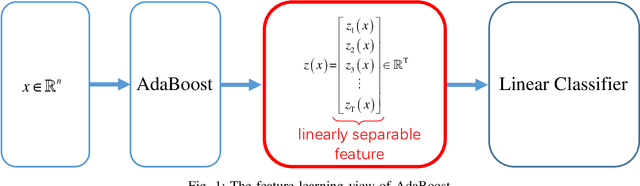
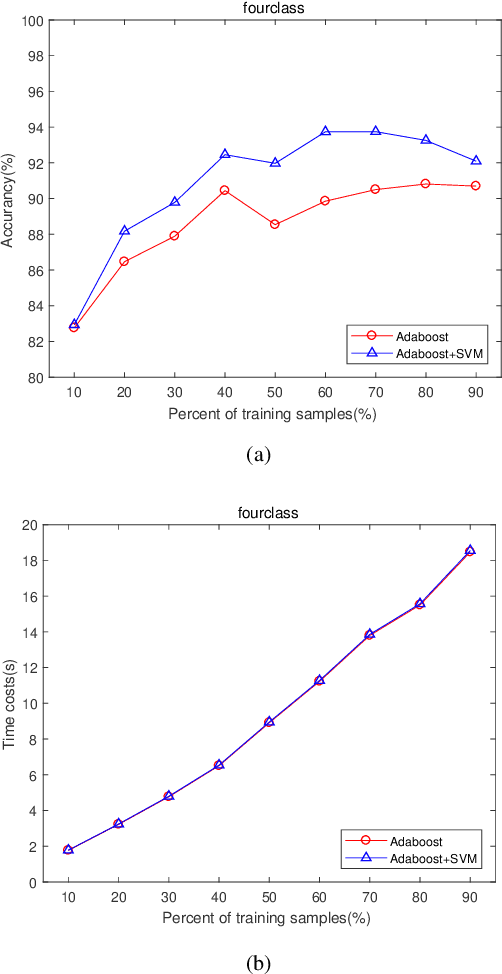
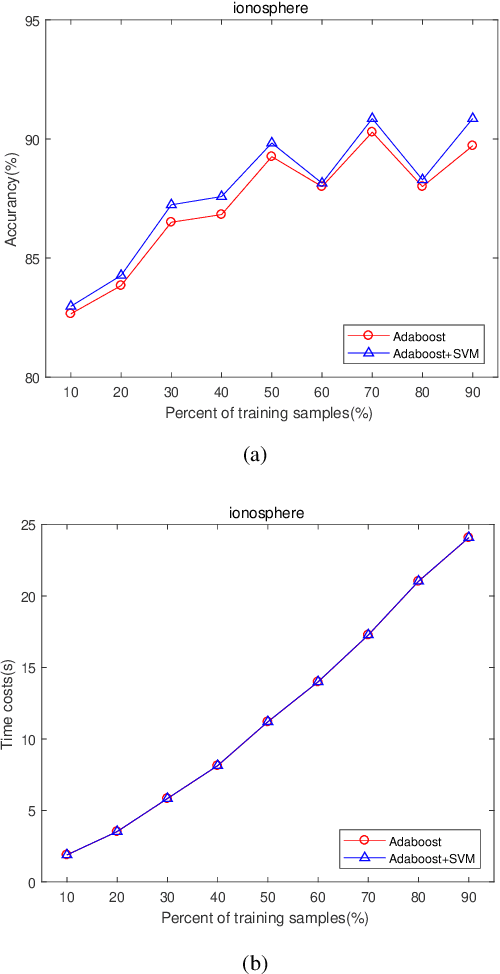
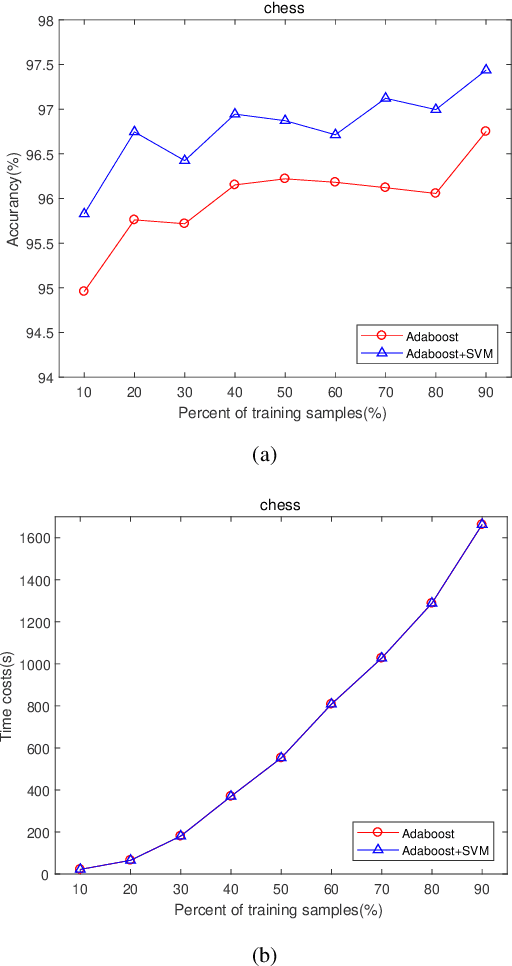
The AdaBoost algorithm has the superiority of resisting overfitting. Understanding the mysteries of this phenomena is a very fascinating fundamental theoretical problem. Many studies are devoted to explaining it from statistical view and margin theory. In this paper, we illustrate it from feature learning viewpoint, and propose the AdaBoost+SVM algorithm, which can explain the resistant to overfitting of AdaBoost directly and easily to understand. Firstly, we adopt the AdaBoost algorithm to learn the base classifiers. Then, instead of directly weighted combination the base classifiers, we regard them as features and input them to SVM classifier. With this, the new coefficient and bias can be obtained, which can be used to construct the final classifier. We explain the rationality of this and illustrate the theorem that when the dimension of these features increases, the performance of SVM would not be worse, which can explain the resistant to overfitting of AdaBoost.