 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Exposure Bias in Score-Based Generation of Molecular Conformations
Sep 21, 2024Molecular conformation generation poses a significant challenge in the field of computational chemistry. Recently, Diffusion Probabilistic Models (DPMs) and Score-Based Generative Models (SGMs) are effectively used due to their capacity for generating accurate conformations far beyond conventional physics-based approaches. However, the discrepancy between training and inference rises a critical problem known as the exposure bias. While this issue has been extensively investigated in DPMs, the existence of exposure bias in SGMs and its effective measurement remain unsolved, which hinders the use of compensation methods for SGMs, including ConfGF and Torsional Diffusion as the representatives. In this work, we first propose a method for measuring exposure bias in SGMs used for molecular conformation generation, which confirms the significant existence of exposure bias in these models and measures its value. We design a new compensation algorithm Input Perturbation (IP), which is adapted from a method originally designed for DPMs only. Experimental results show that by introducing IP, SGM-based molecular conformation models can significantly improve both the accuracy and diversity of the generated conformations. Especially by using the IP-enhanced Torsional Diffusion model, we achieve new state-of-the-art performance on the GEOM-Drugs dataset and are on par on GEOM-QM9. We provide the code publicly at https://github.com/jia-975/torsionalDiff-ip.
Multiplex Graph Contrastive Learning with Soft Negatives
Sep 12, 2024Graph Contrastive Learning (GCL) seeks to learn nodal or graph representations that contain maximal consistent information from graph-structured data. While node-level contrasting modes are dominating, some efforts commence to explore consistency across different scales. Yet, they tend to lose consistent information and be contaminated by disturbing features. Here, we introduce MUX-GCL, a novel cross-scale contrastive learning paradigm that utilizes multiplex representations as effective patches. While this learning mode minimizes contaminating noises, a commensurate contrasting strategy using positional affinities further avoids information loss by correcting false negative pairs across scales. Extensive downstream experiments demonstrate that MUX-GCL yields multiple state-of-the-art results on public datasets. Our theoretical analysis further guarantees the new objective function as a stricter lower bound of mutual information of raw input features and output embeddings, which rationalizes this paradigm. Code is available at https://github.com/MUX-GCL/Code.
Boosting MLPs with a Coarsening Strategy for Long-Term Time Series Forecasting
May 06, 2024



Deep learning methods have been exerting their strengths in long-term time series forecasting. However, they often struggle to strike a balance between expressive power and computational efficiency. Here, we propose the Coarsened Perceptron Network (CP-Net), a novel architecture that efficiently enhances the predictive capability of MLPs while maintains a linear computational complexity. It utilizes a coarsening strategy as the backbone that leverages two-stage convolution-based sampling blocks. Based purely on convolution, they provide the functionality of extracting short-term semantic and contextual patterns, which is relatively deficient in the global point-wise projection of the MLP layer. With the architectural simplicity and low runtime, our experiments on seven time series forecasting benchmarks demonstrate that CP-Net achieves an improvement of 4.1% compared to the SOTA method. The model further shows effective utilization of the exposed information with a consistent improvement as the look-back window expands.
Optimal coordination in Minority Game: A solution from reinforcement learning
Dec 20, 2023Efficient allocation is important in nature and human society where individuals often compete for finite resources. The Minority Game is perhaps the simplest model that provides deep insights into how human coordinate to maximize the resource utilization. However, this model assumes the static strategies that are provided a priori, failing to capture their adaptive nature. Here, we turn to the paradigm of reinforcement learning, where individuals' strategies are evolving by evaluating both the past experience and rewards in the future. Specifically, we adopt the Q-learning algorithm, each player is endowed with a Q-table that guides their decision-making. We reveal that the population is able to reach the optimal allocation when individuals appreciate both the past experience and rewards in the future, and they are able to balance the exploitation of their Q-tables and the exploration by randomly acting. The optimal allocation is ruined when individuals tend to use either exploitation-only or exploration-only, where only partial coordination and even anti-coordination are observed. Mechanism analysis reveals that a moderate level of exploration can escape local minimums of metastable periodic states, and reaches the optimal coordination as the global minimum. Interestingly, the optimal coordination is underlined by a symmetry-breaking of action preferences, where nearly half of the population choose one side while the other half prefer the other side. The emergence of optimal coordination is robust to the population size and other game parameters. Our work therefore provides a natural solution to the Minority Game and sheds insights into the resource allocation problem in general. Besides, our work demonstrates the potential of the proposed reinforcement learning paradigm in deciphering many puzzles in the socio-economic context.
Hybrid Focal and Full-Range Attention Based Graph Transformers
Nov 08, 2023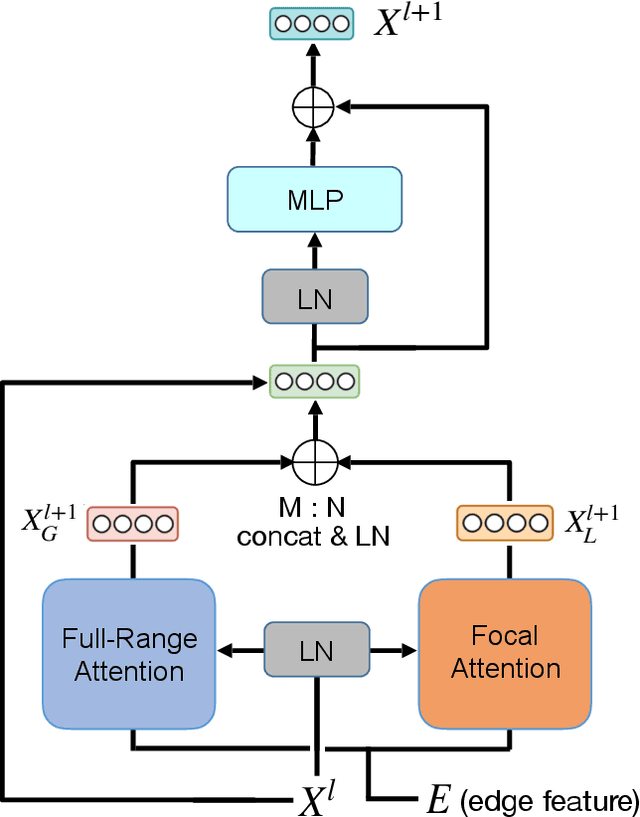
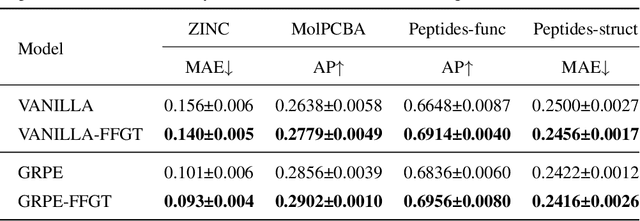
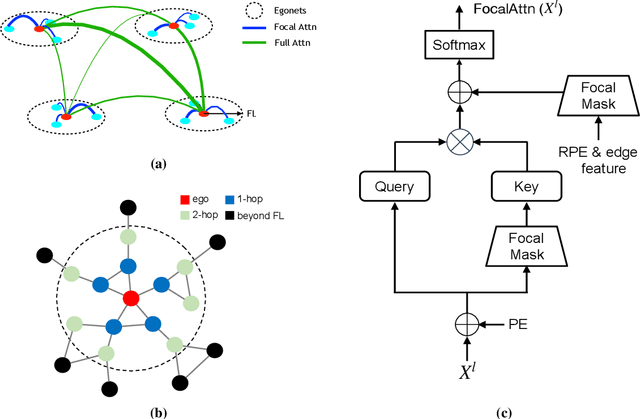
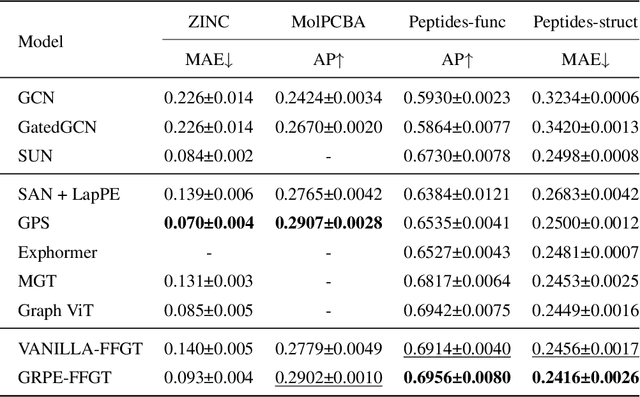
The paradigm of Transformers using the self-attention mechanism has manifested its advantage in learning graph-structured data. Yet, Graph Transformers are capable of modeling full range dependencies but are often deficient in extracting information from locality. A common practice is to utilize Message Passing Neural Networks (MPNNs) as an auxiliary to capture local information, which however are still inadequate for comprehending substructures. In this paper, we present a purely attention-based architecture, namely Focal and Full-Range Graph Transformer (FFGT), which can mitigate the loss of local information in learning global correlations. The core component of FFGT is a new mechanism of compound attention, which combines the conventional full-range attention with K-hop focal attention on ego-nets to aggregate both global and local information. Beyond the scope of canonical Transformers, the FFGT has the merit of being more substructure-aware. Our approach enhances the performance of existing Graph Transformers on various open datasets, while achieves compatible SOTA performance on several Long-Range Graph Benchmark (LRGB) datasets even with a vanilla transformer. We further examine influential factors on the optimal focal length of attention via introducing a novel synthetic dataset based on SBM-PATTERN.
Decoding trust: A reinforcement learning perspective
Sep 26, 2023Behavioral experiments on the trust game have shown that trust and trustworthiness are universal among human beings, contradicting the prediction by assuming \emph{Homo economicus} in orthodox Economics. This means some mechanism must be at work that favors their emergence. Most previous explanations however need to resort to some factors based upon imitative learning, a simple version of social learning. Here, we turn to the paradigm of reinforcement learning, where individuals update their strategies by evaluating the long-term return through accumulated experience. Specifically, we investigate the trust game with the Q-learning algorithm, where each participant is associated with two evolving Q-tables that guide one's decision making as trustor and trustee respectively. In the pairwise scenario, we reveal that high levels of trust and trustworthiness emerge when individuals appreciate both their historical experience and returns in the future. Mechanistically, the evolution of the Q-tables shows a crossover that resembles human's psychological changes. We also provide the phase diagram for the game parameters, where the boundary analysis is conducted. These findings are robust when the scenario is extended to a latticed population. Our results thus provide a natural explanation for the emergence of trust and trustworthiness without external factors involved. More importantly, the proposed paradigm shows the potential in deciphering many puzzles in human behaviors.
Quantifying the Global Support Network for Non-State Armed Groups (NAGs)
Jan 31, 2021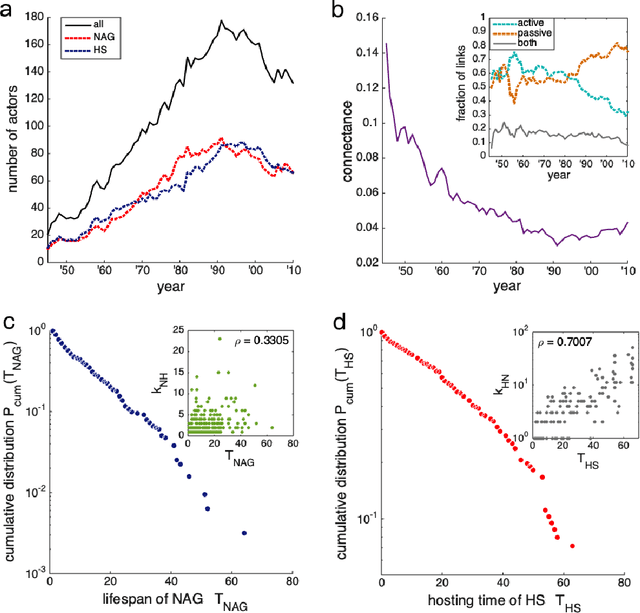
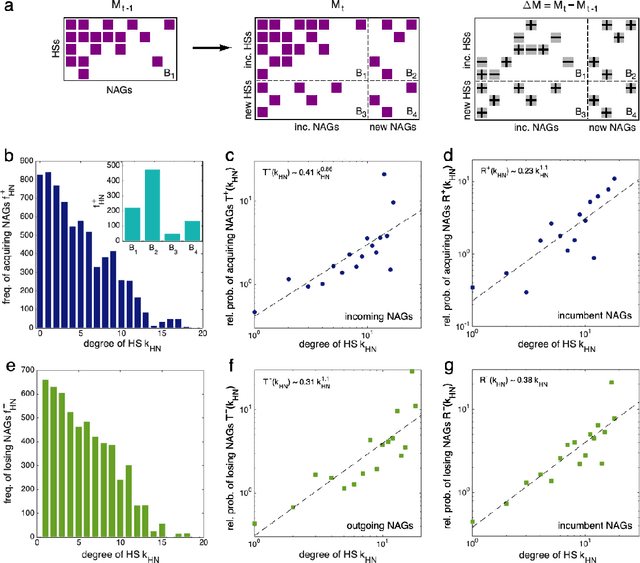
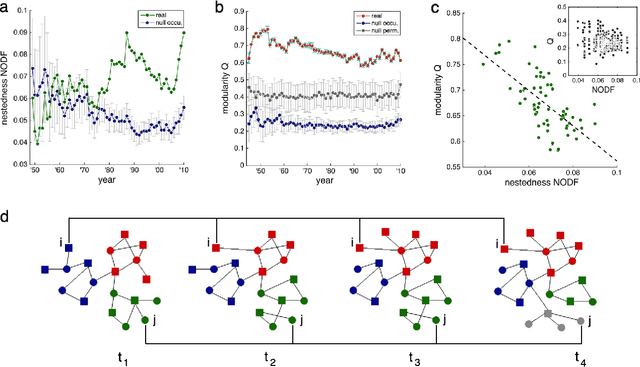
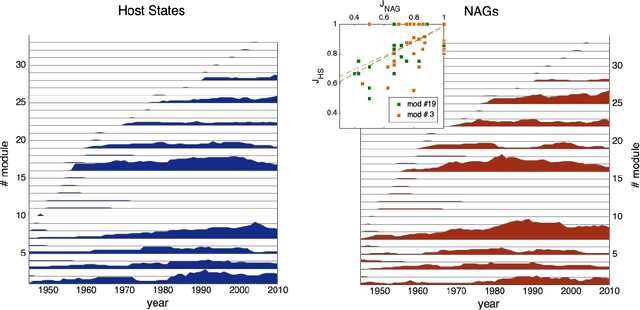
Human history has been shaped by armed conflicts. Rather than large-scale interstate wars, low-intensity attacks have been more prevalent in the post-World War era. These attacks are often carried out by non-state armed groups (NAGs), which are supported by host states (HSs). We analyze the global bipartite network of NAG-HS support and its evolution over the period of 1945-2010. We find striking parallels to ecological networks such as mutualistic and parasitic forms of support, and a nested and modular network architecture. The nestedness emerges from preferential behaviors: highly connected players are more likely to both gain and lose connections. Long-persisting major modules are identified, reflecting both regional and trans-regional interests, which show significant turnover in their membership, contrary to the transitory ones. Revealing this architecture further enables the identification of actor's roles and provide insights for effective intervention strategies.