 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Exposure Bias in Score-Based Generation of Molecular Conformations
Sep 21, 2024Molecular conformation generation poses a significant challenge in the field of computational chemistry. Recently, Diffusion Probabilistic Models (DPMs) and Score-Based Generative Models (SGMs) are effectively used due to their capacity for generating accurate conformations far beyond conventional physics-based approaches. However, the discrepancy between training and inference rises a critical problem known as the exposure bias. While this issue has been extensively investigated in DPMs, the existence of exposure bias in SGMs and its effective measurement remain unsolved, which hinders the use of compensation methods for SGMs, including ConfGF and Torsional Diffusion as the representatives. In this work, we first propose a method for measuring exposure bias in SGMs used for molecular conformation generation, which confirms the significant existence of exposure bias in these models and measures its value. We design a new compensation algorithm Input Perturbation (IP), which is adapted from a method originally designed for DPMs only. Experimental results show that by introducing IP, SGM-based molecular conformation models can significantly improve both the accuracy and diversity of the generated conformations. Especially by using the IP-enhanced Torsional Diffusion model, we achieve new state-of-the-art performance on the GEOM-Drugs dataset and are on par on GEOM-QM9. We provide the code publicly at https://github.com/jia-975/torsionalDiff-ip.
Multiplex Graph Contrastive Learning with Soft Negatives
Sep 12, 2024Graph Contrastive Learning (GCL) seeks to learn nodal or graph representations that contain maximal consistent information from graph-structured data. While node-level contrasting modes are dominating, some efforts commence to explore consistency across different scales. Yet, they tend to lose consistent information and be contaminated by disturbing features. Here, we introduce MUX-GCL, a novel cross-scale contrastive learning paradigm that utilizes multiplex representations as effective patches. While this learning mode minimizes contaminating noises, a commensurate contrasting strategy using positional affinities further avoids information loss by correcting false negative pairs across scales. Extensive downstream experiments demonstrate that MUX-GCL yields multiple state-of-the-art results on public datasets. Our theoretical analysis further guarantees the new objective function as a stricter lower bound of mutual information of raw input features and output embeddings, which rationalizes this paradigm. Code is available at https://github.com/MUX-GCL/Code.
Hybrid Focal and Full-Range Attention Based Graph Transformers
Nov 08, 2023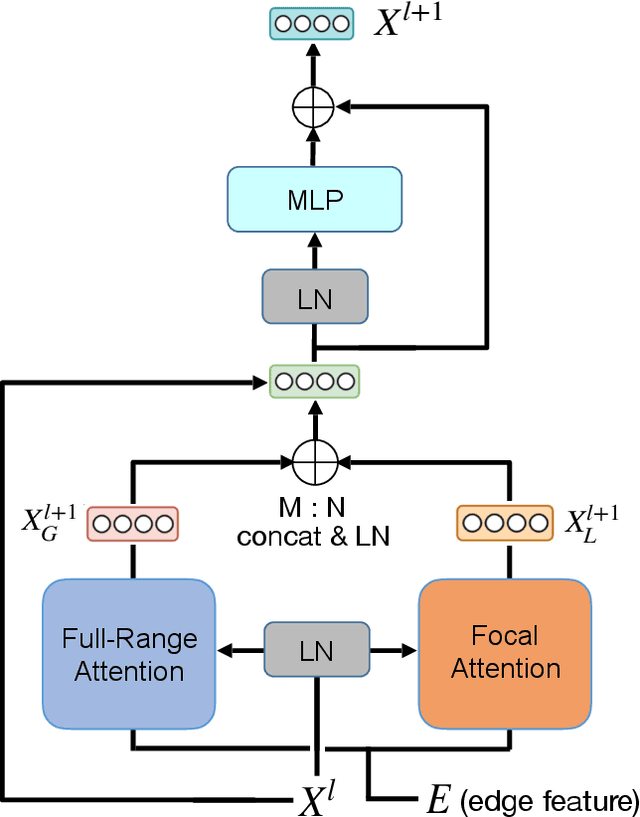
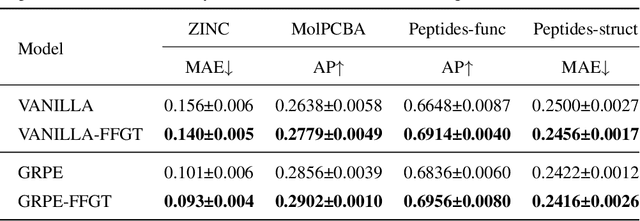
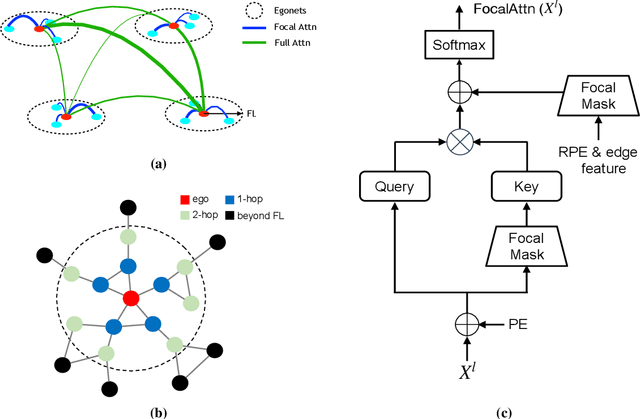
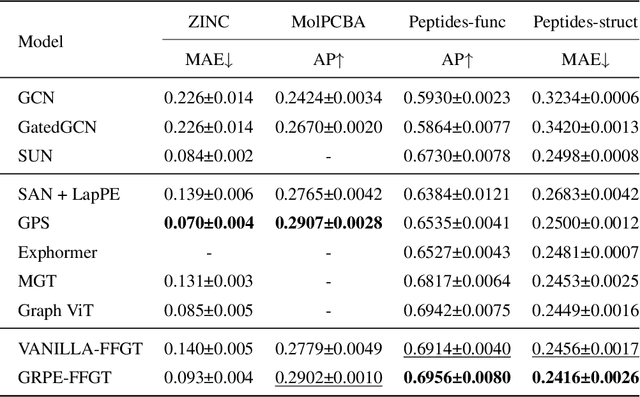
The paradigm of Transformers using the self-attention mechanism has manifested its advantage in learning graph-structured data. Yet, Graph Transformers are capable of modeling full range dependencies but are often deficient in extracting information from locality. A common practice is to utilize Message Passing Neural Networks (MPNNs) as an auxiliary to capture local information, which however are still inadequate for comprehending substructures. In this paper, we present a purely attention-based architecture, namely Focal and Full-Range Graph Transformer (FFGT), which can mitigate the loss of local information in learning global correlations. The core component of FFGT is a new mechanism of compound attention, which combines the conventional full-range attention with K-hop focal attention on ego-nets to aggregate both global and local information. Beyond the scope of canonical Transformers, the FFGT has the merit of being more substructure-aware. Our approach enhances the performance of existing Graph Transformers on various open datasets, while achieves compatible SOTA performance on several Long-Range Graph Benchmark (LRGB) datasets even with a vanilla transformer. We further examine influential factors on the optimal focal length of attention via introducing a novel synthetic dataset based on SBM-PATTERN.