 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Focal and Full-Range Attention Based Graph Transformers
Paper and Code
Nov 08, 2023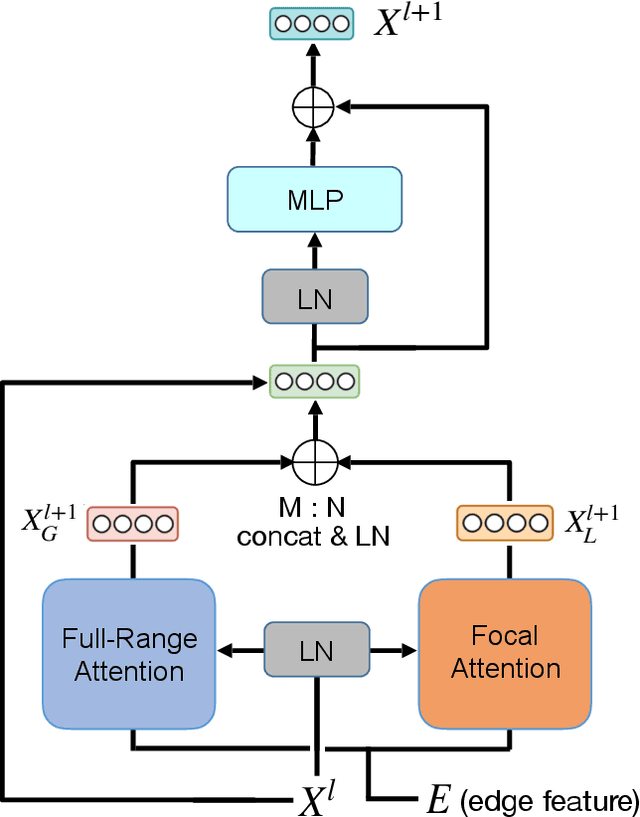
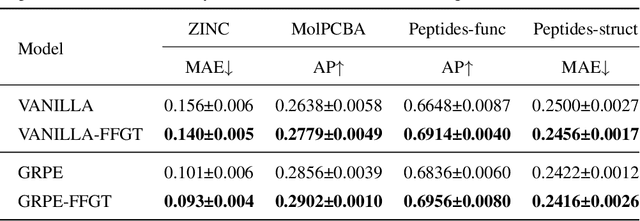
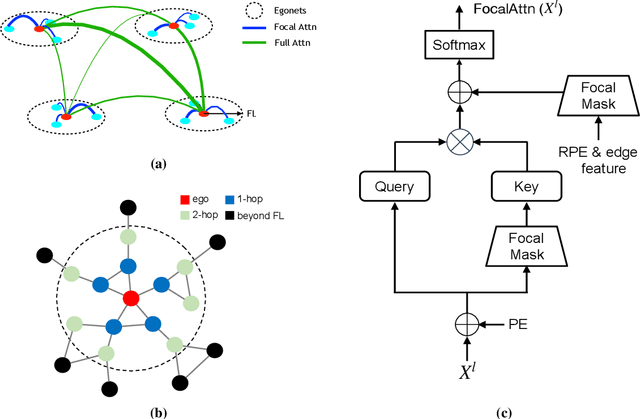
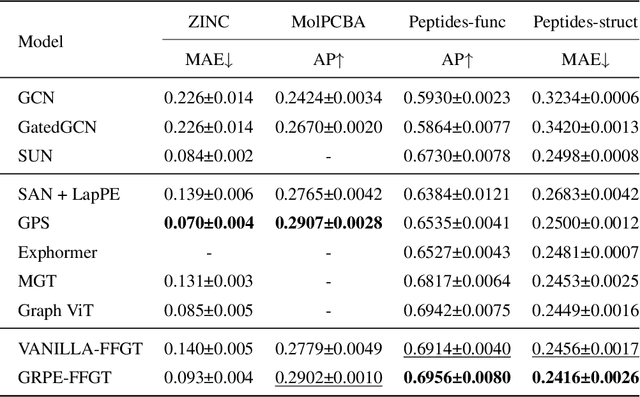
The paradigm of Transformers using the self-attention mechanism has manifested its advantage in learning graph-structured data. Yet, Graph Transformers are capable of modeling full range dependencies but are often deficient in extracting information from locality. A common practice is to utilize Message Passing Neural Networks (MPNNs) as an auxiliary to capture local information, which however are still inadequate for comprehending substructures. In this paper, we present a purely attention-based architecture, namely Focal and Full-Range Graph Transformer (FFGT), which can mitigate the loss of local information in learning global correlations. The core component of FFGT is a new mechanism of compound attention, which combines the conventional full-range attention with K-hop focal attention on ego-nets to aggregate both global and local information. Beyond the scope of canonical Transformers, the FFGT has the merit of being more substructure-aware. Our approach enhances the performance of existing Graph Transformers on various open datasets, while achieves compatible SOTA performance on several Long-Range Graph Benchmark (LRGB) datasets even with a vanilla transformer. We further examine influential factors on the optimal focal length of attention via introducing a novel synthetic dataset based on SBM-PATTERN.