 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynHD: Hallucination Detection for Diffusion Large Language Models via Denoising Dynamics Deviation Learning
Mar 17, 2026Diffusion large language models (D-LLMs) have emerged as a promising alternative to auto-regressive models due to their iterative refinement capabilities. However, hallucinations remain a critical issue that hinders their reliability. To detect hallucination responses from model outputs, token-level uncertainty (e.g., entropy) has been widely used as an effective signal to indicate potential factual errors. Nevertheless, the fixed-length generation paradigm of D-LLMs implies that tokens contribute unevenly to hallucination detection, with only a small subset providing meaningful signals. Moreover, the evolution trend of uncertainty throughout the diffusion process can also provide important signals, highlighting the necessity of modeling its denoising dynamics for hallucination detection. In this paper, we propose DynHD that bridge these gaps from both spatial (token sequence) and temporal (denoising dynamics) perspectives. To address the information density imbalance across tokens, we propose a semantic-aware evidence construction module that extracts hallucination-indicative signals by filtering out non-informative tokens and emphasizing semantically meaningful ones. To model denoising dynamics for hallucination detection, we introduce a reference evidence generator that learns the expected evolution trajectory of uncertainty evidence, along with a deviation-based hallucination detector that makes predictions by measuring the discrepancy between the observed and reference trajectories. Extensive experiments demonstrate that DynHD consistently outperforms state-of-the-art baselines while achieving higher efficiency across multiple benchmarks and backbone models.
Local and Global Feature Attention Fusion Network for Face Recognition
Nov 25, 2024Recognition of low-quality face images remains a challenge due to invisible or deformation in partial facial regions. For low-quality images dominated by missing partial facial regions, local region similarity contributes more to face recognition (FR). Conversely, in cases dominated by local face deformation, excessive attention to local regions may lead to misjudgments, while global features exhibit better robustness. However, most of the existing FR methods neglect the bias in feature quality of low-quality images introduced by different factors. To address this issue, we propose a Local and Global Feature Attention Fusion (LGAF) network based on feature quality. The network adaptively allocates attention between local and global features according to feature quality and obtains more discriminative and high-quality face features through local and global information complementarity. In addition, to effectively obtain fine-grained information at various scales and increase the separability of facial features in high-dimensional space, we introduce a Multi-Head Multi-Scale Local Feature Extraction (MHMS) module. Experimental results demonstrate that the LGAF achieves the best average performance on $4$ validation sets (CFP-FP, CPLFW, AgeDB, and CALFW), and the performance on TinyFace and SCFace outperforms the state-of-the-art methods (SoTA).
Pushing the Limits of 3D Shape Generation at Scale
Jun 20, 2023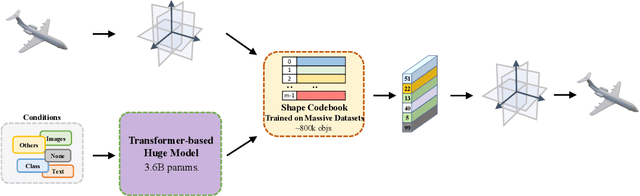
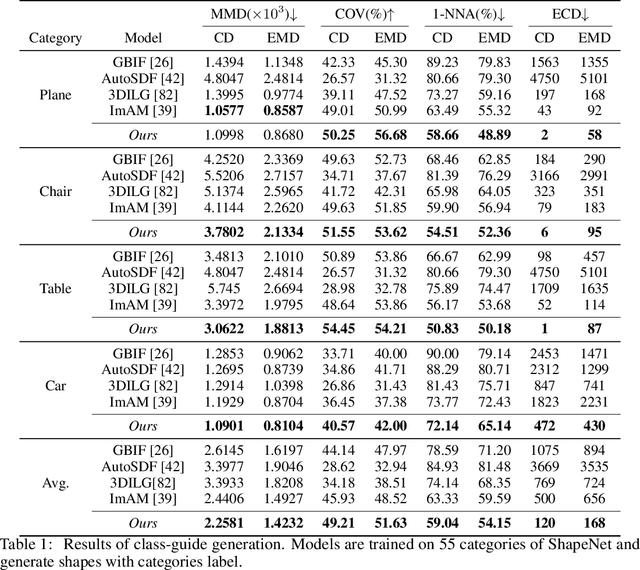


We present a significant breakthrough in 3D shape generation by scaling it to unprecedented dimensions. Through the adaptation of the Auto-Regressive model and the utilization of large language models, we have developed a remarkable model with an astounding 3.6 billion trainable parameters, establishing it as the largest 3D shape generation model to date, named Argus-3D. Our approach addresses the limitations of existing methods by enhancing the quality and diversity of generated 3D shapes. To tackle the challenges of high-resolution 3D shape generation, our model incorporates tri-plane features as latent representations, effectively reducing computational complexity. Additionally, we introduce a discrete codebook for efficient quantization of these representations. Leveraging the power of transformers, we enable multi-modal conditional generation, facilitating the production of diverse and visually impressive 3D shapes. To train our expansive model, we leverage an ensemble of publicly-available 3D datasets, consisting of a comprehensive collection of approximately 900,000 objects from renowned repositories such as ModelNet40, ShapeNet, Pix3D, 3D-Future, and Objaverse. This diverse dataset empowers our model to learn from a wide range of object variations, bolstering its ability to generate high-quality and diverse 3D shapes. Extensive experimentation demonstrate the remarkable efficacy of our approach in significantly improving the visual quality of generated 3D shapes. By pushing the boundaries of 3D generation, introducing novel methods for latent representation learning, and harnessing the power of transformers for multi-modal conditional generation, our contributions pave the way for substantial advancements in the field. Our work unlocks new possibilities for applications in gaming, virtual reality, product design, and other domains that demand high-quality and diverse 3D objects.
ELM-based Frame Synchronization in Nonlinear Distortion Scenario Using Superimposed Training
Mar 27, 2021


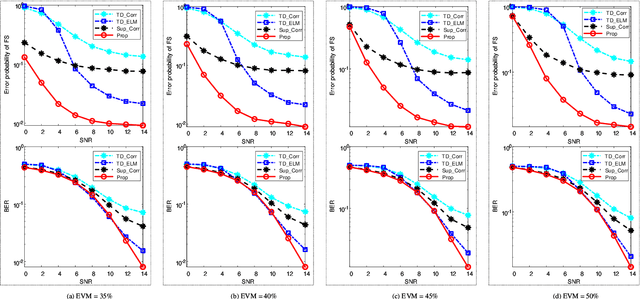
The requirement of high spectrum efficiency puts forward higher requirements on frame synchronization (FS) in wireless communication systems. Meanwhile, a large number of nonlinear devices or blocks will inevitably cause nonlinear distortion. To avoid the occupation of bandwidth resources and overcome the difficulty of nonlinear distortion, an extreme learning machine (ELM)-based network is introduced into the superimposed training-based FS with nonlinear distortion. Firstly, a preprocessing procedure is utilized to reap the features of synchronization metric (SM). Then, based on the rough features of SM, an ELM network is constructed to estimate the offset of frame boundary. The analysis and experiment results show that, compared with existing methods, the proposed method can improve the error probability of FS and bit error rate (BER) of symbol detection (SD). In addition, this improvement has its robustness against the impacts of parameter variations.
ELM-based Frame Synchronization in Burst-Mode Communication Systems with Nonlinear Distortion
Feb 14, 2020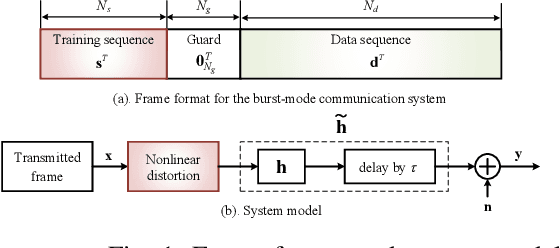
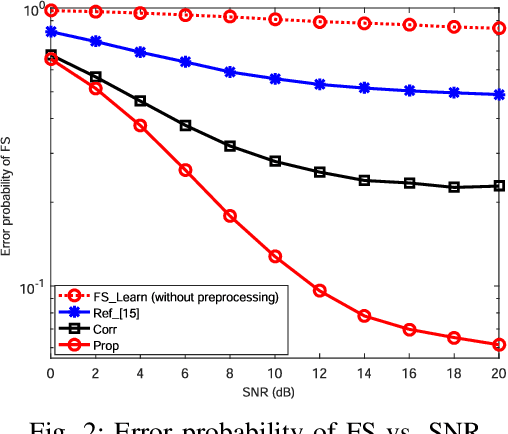
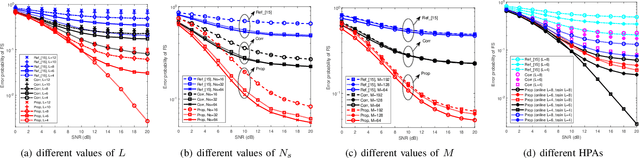
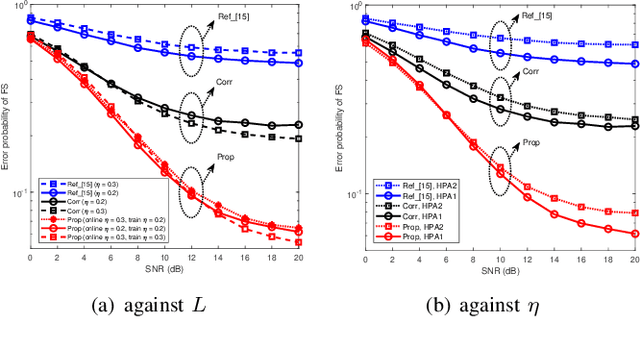
In burst-mode communication systems, the quality of frame synchronization (FS) at receivers significantly impacts the overall system performance. To guarantee FS, an extreme learning machine (ELM)-based synchronization method is proposed to overcome the nonlinear distortion caused by nonlinear devices or blocks. In the proposed method, a preprocessing is first performed to capture the coarse features of synchronization metric (SM) by using empirical knowledge. Then, an ELM-based FS network is employed to reduce system's nonlinear distortion and improve SMs. Experimental results indicate that, compared with existing methods, our approach could significantly reduce the error probability of FS while improve the performance in terms of robustness and generalization.