 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretations are useful: penalizing explanations to align neural networks with prior knowledge
Oct 01, 2019

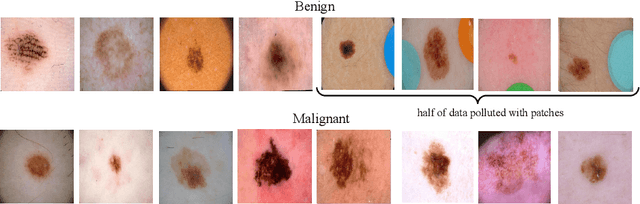
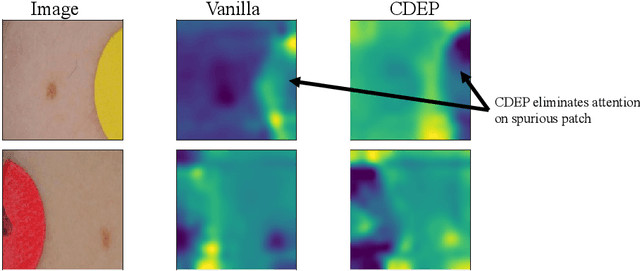
For an explanation of a deep learning model to be effective, it must provide both insight into a model and suggest a corresponding action in order to achieve some objective. Too often, the litany of proposed explainable deep learning methods stop at the first step, providing practitioners with insight into a model, but no way to act on it. In this paper, we propose contextual decomposition explanation penalization (CDEP), a method which enables practitioners to leverage existing explanation methods in order to increase the predictive accuracy of deep learning models. In particular, when shown that a model has incorrectly assigned importance to some features, CDEP enables practitioners to correct these errors by directly regularizing the provided explanations. Using explanations provided by contextual decomposition (CD) (Murdoch et al., 2018), we demonstrate the ability of our method to increase performance on an array of toy and real datasets.
Disentangled Attribution Curves for Interpreting Random Forests and Boosted Trees
May 18, 2019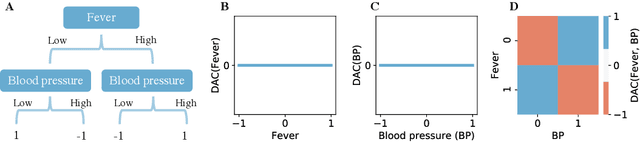
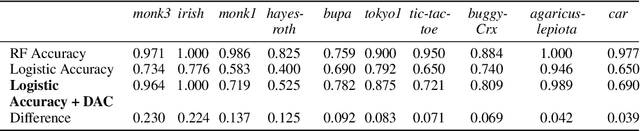

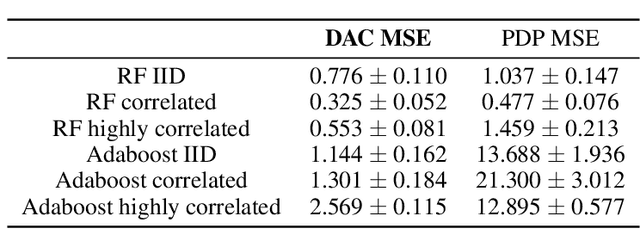
Tree ensembles, such as random forests and AdaBoost, are ubiquitous machine learning models known for achieving strong predictive performance across a wide variety of domains. However, this strong performance comes at the cost of interpretability (i.e. users are unable to understand the relationships a trained random forest has learned and why it is making its predictions). In particular, it is challenging to understand how the contribution of a particular feature, or group of features, varies as their value changes. To address this, we introduce Disentangled Attribution Curves (DAC), a method to provide interpretations of tree ensemble methods in the form of (multivariate) feature importance curves. For a given variable, or group of variables, DAC plots the importance of a variable(s) as their value changes. We validate DAC on real data by showing that the curves can be used to increase the accuracy of logistic regression while maintaining interpretability, by including DAC as an additional feature. In simulation studies, DAC is shown to out-perform competing methods in the recovery of conditional expectations. Finally, through a case-study on the bike-sharing dataset, we demonstrate the use of DAC to uncover novel insights into a dataset.
Interpretable machine learning: definitions, methods, and applications
Jan 14, 2019
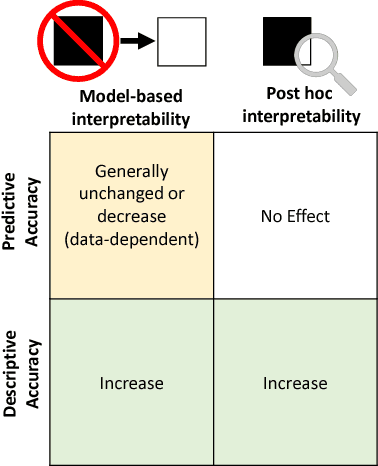
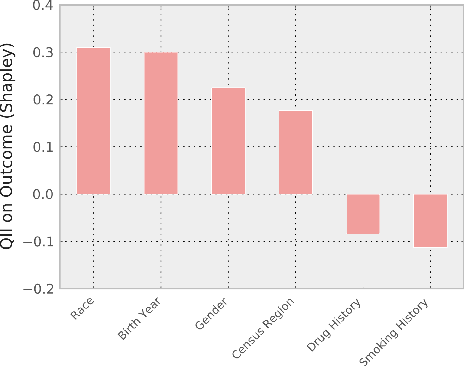
Machine-learning models have demonstrated great success in learning complex patterns that enable them to make predictions about unobserved data. In addition to using models for prediction, the ability to interpret what a model has learned is receiving an increasing amount of attention. However, this increased focus has led to considerable confusion about the notion of interpretability. In particular, it is unclear how the wide array of proposed interpretation methods are related, and what common concepts can be used to evaluate them. We aim to address these concerns by defining interpretability in the context of machine learning and introducing the Predictive, Descriptive, Relevant (PDR) framework for discussing interpretations. The PDR framework provides three overarching desiderata for evaluation: predictive accuracy, descriptive accuracy and relevancy, with relevancy judged relative to a human audience. Moreover, to help manage the deluge of interpretation methods, we introduce a categorization of existing techniques into model-based and post-hoc categories, with sub-groups including sparsity, modularity and simulatability. To demonstrate how practitioners can use the PDR framework to evaluate and understand interpretations, we provide numerous real-world examples. These examples highlight the often under-appreciated role played by human audiences in discussions of interpretability. Finally, based on our framework, we discuss limitations of existing methods and directions for future work. We hope that this work will provide a common vocabulary that will make it easier for both practitioners and researchers to discuss and choose from the full range of interpretation methods.
Hierarchical interpretations for neural network predictions
Jun 14, 2018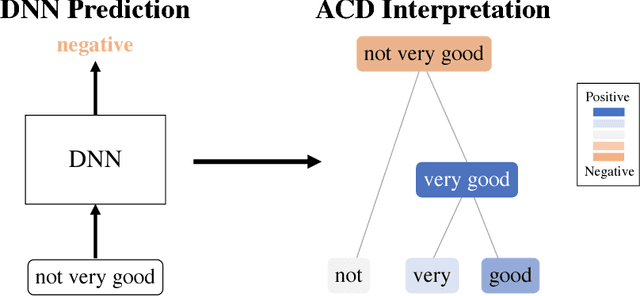

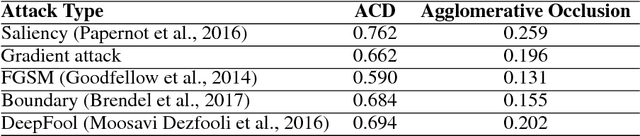
Deep neural networks (DNNs) have achieved impressive predictive performance due to their ability to learn complex, non-linear relationships between variables. However, the inability to effectively visualize these relationships has led to DNNs being characterized as black boxes and consequently limited their applications. To ameliorate this problem, we introduce the use of hierarchical interpretations to explain DNN predictions through our proposed method, agglomerative contextual decomposition (ACD). Given a prediction from a trained DNN, ACD produces a hierarchical clustering of the input features, along with the contribution of each cluster to the final prediction. This hierarchy is optimized to identify clusters of features that the DNN learned are predictive. Using examples from Stanford Sentiment Treebank and ImageNet, we show that ACD is effective at diagnosing incorrect predictions and identifying dataset bias. Through human experiments, we demonstrate that ACD enables users both to identify the more accurate of two DNNs and to better trust a DNN's outputs. We also find that ACD's hierarchy is largely robust to adversarial perturbations, implying that it captures fundamental aspects of the input and ignores spurious noise.
Beyond Word Importance: Contextual Decomposition to Extract Interactions from LSTMs
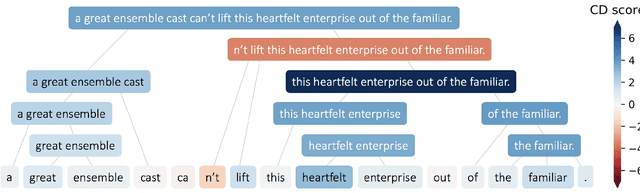
Apr 27, 2018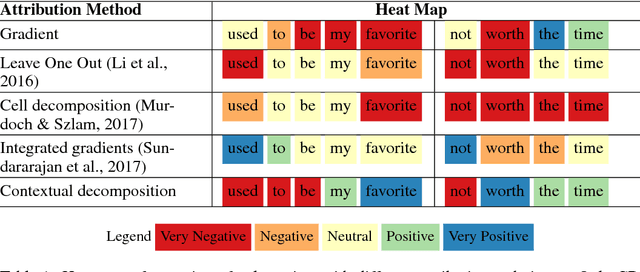
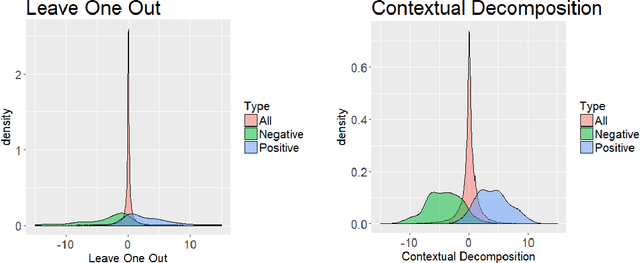
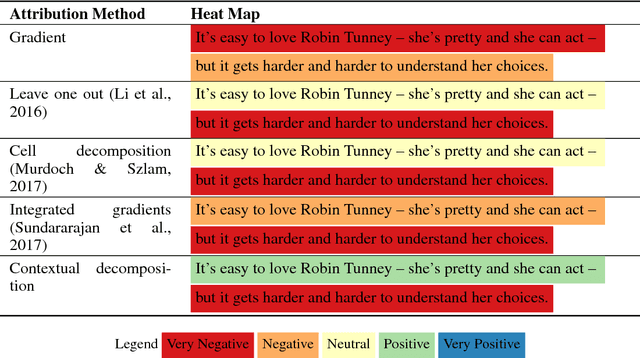
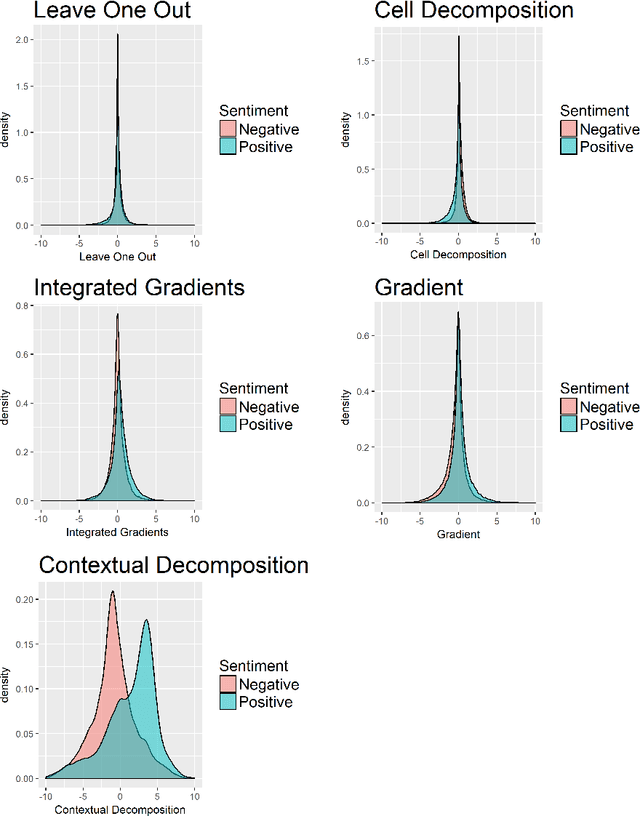
The driving force behind the recent success of LSTMs has been their ability to learn complex and non-linear relationships. Consequently, our inability to describe these relationships has led to LSTMs being characterized as black boxes. To this end, we introduce contextual decomposition (CD), an interpretation algorithm for analysing individual predictions made by standard LSTMs, without any changes to the underlying model. By decomposing the output of a LSTM, CD captures the contributions of combinations of words or variables to the final prediction of an LSTM. On the task of sentiment analysis with the Yelp and SST data sets, we show that CD is able to reliably identify words and phrases of contrasting sentiment, and how they are combined to yield the LSTM's final prediction. Using the phrase-level labels in SST, we also demonstrate that CD is able to successfully extract positive and negative negations from an LSTM, something which has not previously been done.
Automatic Rule Extraction from Long Short Term Memory Networks
Feb 24, 2017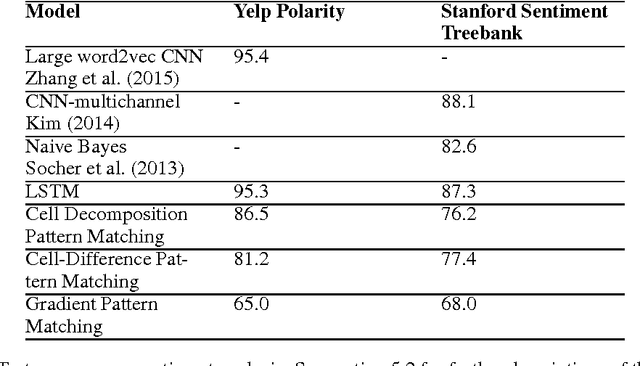



Although deep learning models have proven effective at solving problems in natural language processing, the mechanism by which they come to their conclusions is often unclear. As a result, these models are generally treated as black boxes, yielding no insight of the underlying learned patterns. In this paper we consider Long Short Term Memory networks (LSTMs) and demonstrate a new approach for tracking the importance of a given input to the LSTM for a given output. By identifying consistently important patterns of words, we are able to distill state of the art LSTMs on sentiment analysis and question answering into a set of representative phrases. This representation is then quantitatively validated by using the extracted phrases to construct a simple, rule-based classifier which approximates the output of the LSTM.
Expanded Alternating Optimization of Nonconvex Functions with Applications to Matrix Factorization and Penalized Regression
Dec 12, 2014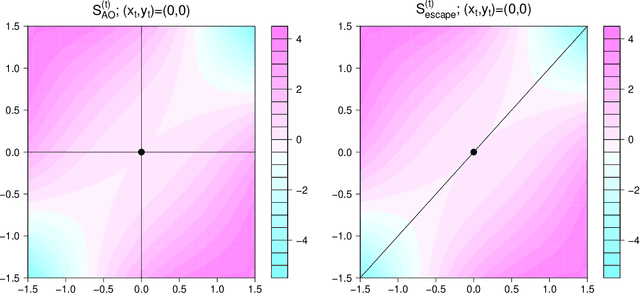

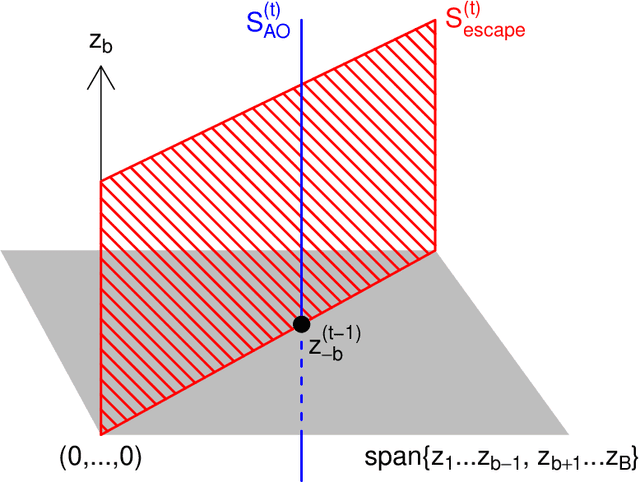
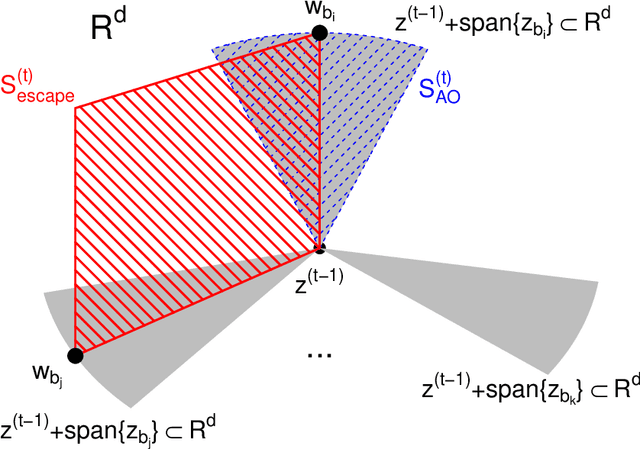
We propose a general technique for improving alternating optimization (AO) of nonconvex functions. Starting from the solution given by AO, we conduct another sequence of searches over subspaces that are both meaningful to the optimization problem at hand and different from those used by AO. To demonstrate the utility of our approach, we apply it to the matrix factorization (MF) algorithm for recommender systems and the coordinate descent algorithm for penalized regression (PR), and show meaningful improvements using both real-world (for MF) and simulated (for PR) data sets. Moreover, we demonstrate for MF that, by constructing search spaces customized to the given data set, we can significantly increase the convergence rate of our technique.