 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA simple defense against adversarial attacks on heatmap explanations
Jul 13, 2020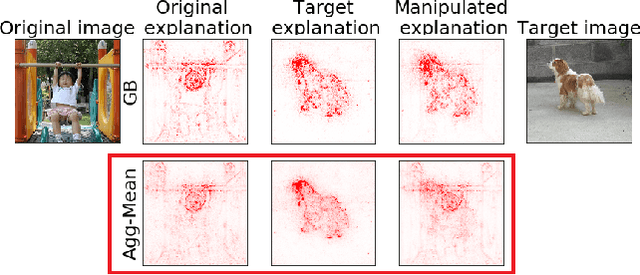

With machine learning models being used for more sensitive applications, we rely on interpretability methods to prove that no discriminating attributes were used for classification. A potential concern is the so-called "fair-washing" - manipulating a model such that the features used in reality are hidden and more innocuous features are shown to be important instead. In our work we present an effective defence against such adversarial attacks on neural networks. By a simple aggregation of multiple explanation methods, the network becomes robust against manipulation. This holds even when the attacker has exact knowledge of the model weights and the explanation methods used.
Client Adaptation improves Federated Learning with Simulated Non-IID Clients
Jul 09, 2020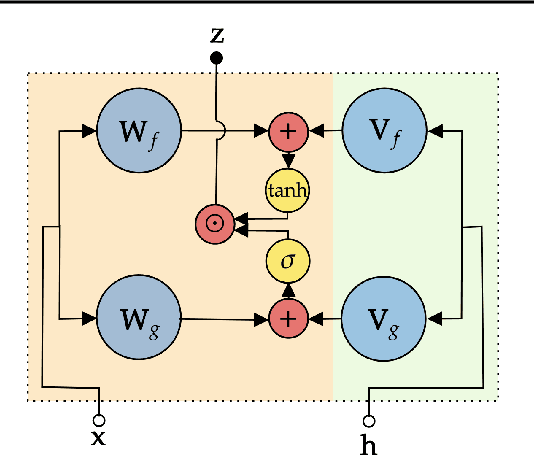
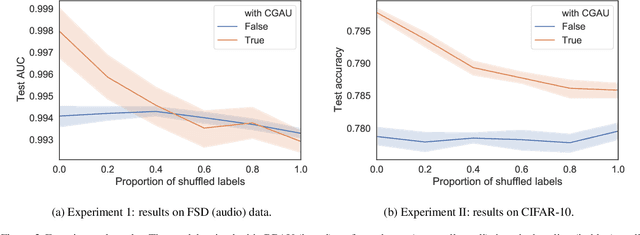
We present a federated learning approach for learning a client adaptable, robust model when data is non-identically and non-independently distributed (non-IID) across clients. By simulating heterogeneous clients, we show that adding learned client-specific conditioning improves model performance, and the approach is shown to work on balanced and imbalanced data set from both audio and image domains. The client adaptation is implemented by a conditional gated activation unit and is particularly beneficial when there are large differences between the data distribution for each client, a common scenario in federated learning.
IROF: a low resource evaluation metric for explanation methods
Mar 09, 2020



The adoption of machine learning in health care hinges on the transparency of the used algorithms, necessitating the need for explanation methods. However, despite a growing literature on explaining neural networks, no consensus has been reached on how to evaluate those explanation methods. We propose IROF, a new approach to evaluating explanation methods that circumvents the need for manual evaluation. Compared to other recent work, our approach requires several orders of magnitude less computational resources and no human input, making it accessible to lower resource groups and robust to human bias.
Interpretations are useful: penalizing explanations to align neural networks with prior knowledge
Oct 01, 2019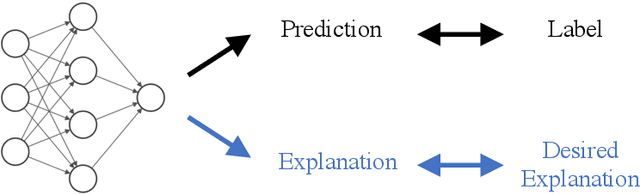

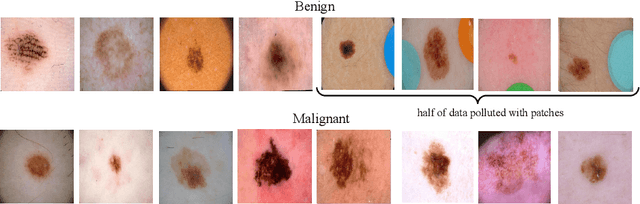
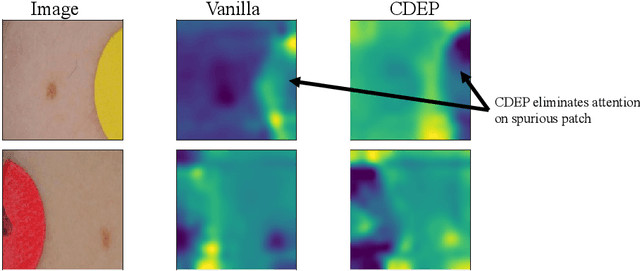
For an explanation of a deep learning model to be effective, it must provide both insight into a model and suggest a corresponding action in order to achieve some objective. Too often, the litany of proposed explainable deep learning methods stop at the first step, providing practitioners with insight into a model, but no way to act on it. In this paper, we propose contextual decomposition explanation penalization (CDEP), a method which enables practitioners to leverage existing explanation methods in order to increase the predictive accuracy of deep learning models. In particular, when shown that a model has incorrectly assigned importance to some features, CDEP enables practitioners to correct these errors by directly regularizing the provided explanations. Using explanations provided by contextual decomposition (CD) (Murdoch et al., 2018), we demonstrate the ability of our method to increase performance on an array of toy and real datasets.
Aggregating explainability methods for neural networks stabilizes explanations
Mar 01, 2019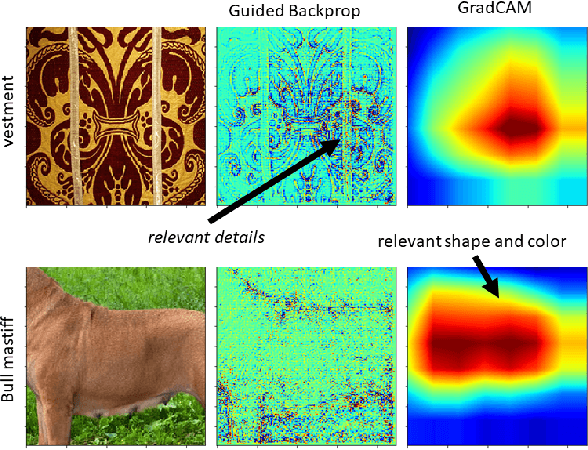



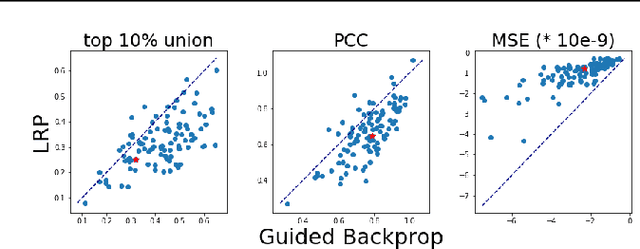
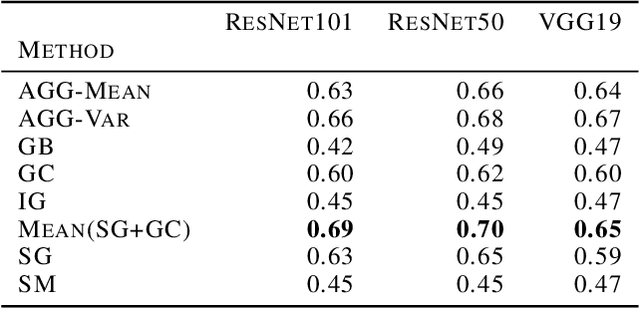
Despite a growing literature on explaining neural networks, no consensus has been reached on how to explain a neural network decision or how to evaluate an explanation. In fact, most works rely on manually assessing the explanation to evaluate the quality of a method. This injects uncertainty in the explanation process along several dimensions: Which explanation method to apply? Who should we ask to evaluate it and which criteria should be used for the evaluation? Our contributions in this paper are twofold. First, we investigate schemes to combine explanation methods and reduce model uncertainty to obtain a single aggregated explanation. Our findings show that the aggregation is more robust, well-aligned with human explanations and can attribute relevance to a broader set of features (completeness). Second, we propose a novel way of evaluating explanation methods that circumvents the need for manual evaluation and is not reliant on the alignment of neural networks and humans decision processes.