 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning to Predict Developmental Neurotoxicity with High-throughput Data from 2D Bio-engineered Tissues
May 06, 2019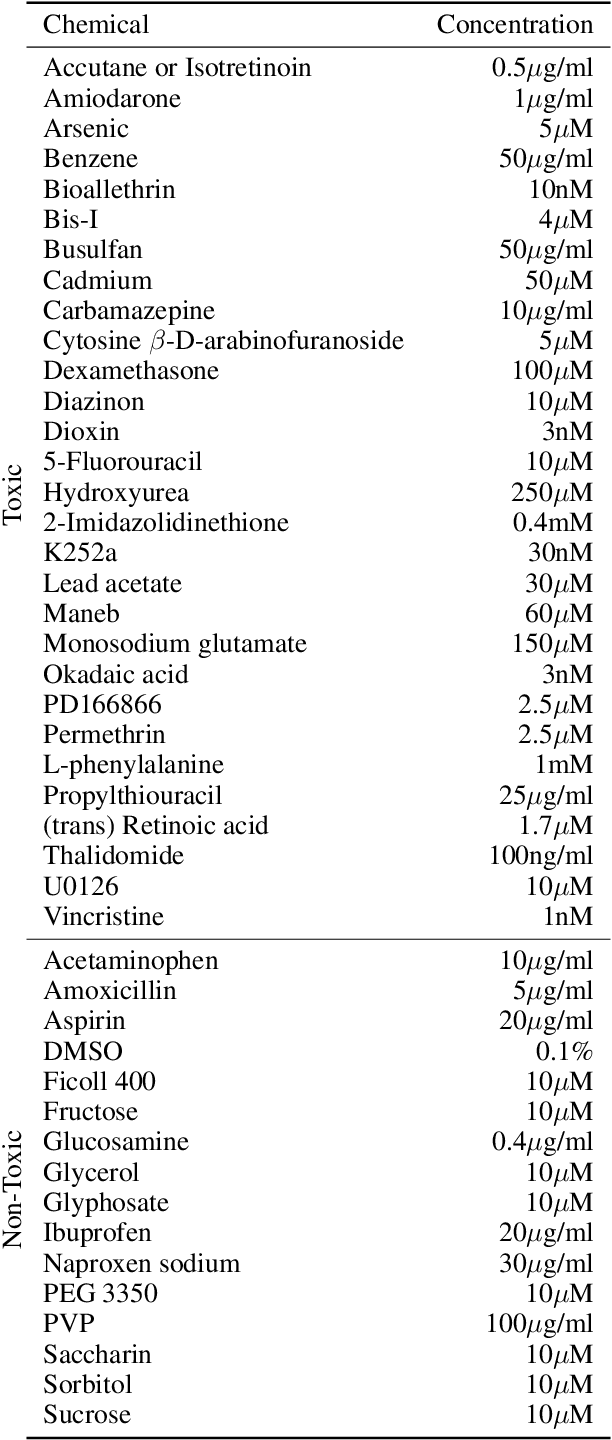
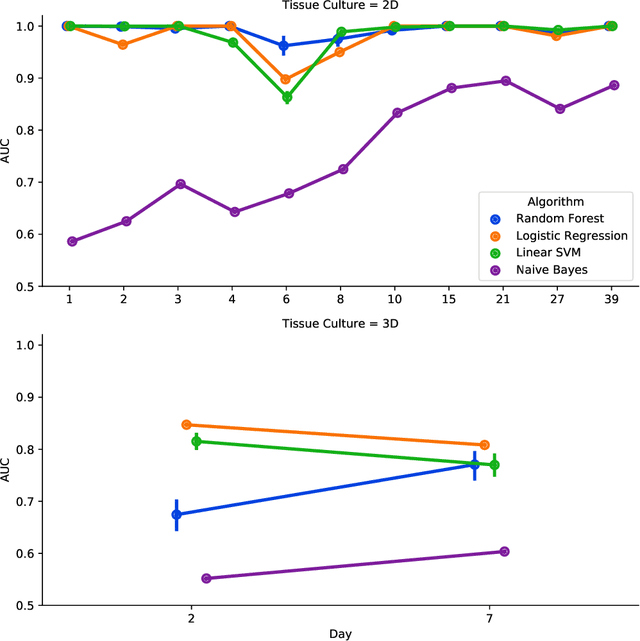
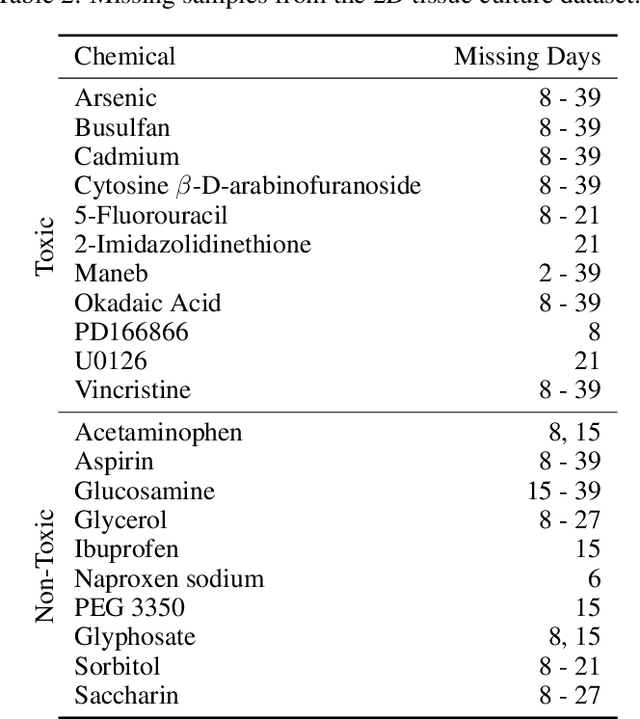
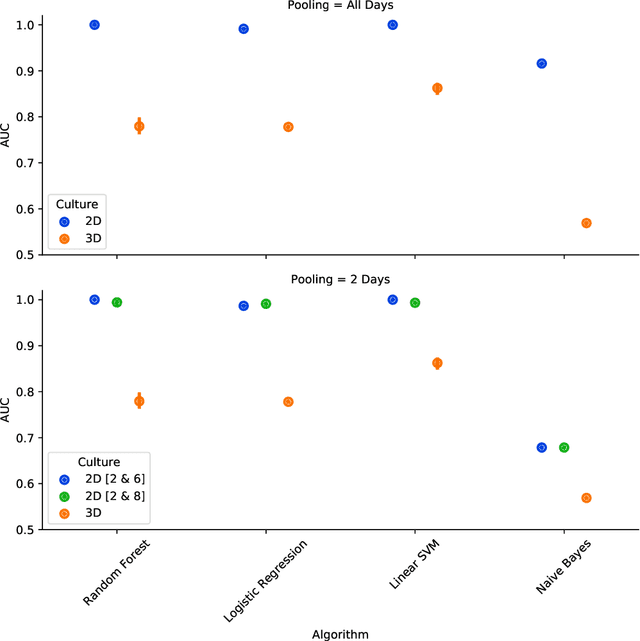
There is a growing need for fast and accurate methods for testing developmental neurotoxicity across several chemical exposure sources. Current approaches, such as in vivo animal studies, and assays of animal and human primary cell cultures, suffer from challenges related to time, cost, and applicability to human physiology. We previously demonstrated success employing machine learning to predict developmental neurotoxicity using gene expression data collected from human 3D tissue models exposed to various compounds. The 3D model is biologically similar to developing neural structures, but its complexity necessitates extensive expertise and effort to employ. By instead focusing solely on constructing an assay of developmental neurotoxicity, we propose that a simpler 2D tissue model may prove sufficient. We thus compare the accuracy of predictive models trained on data from a 2D tissue model with those trained on data from a 3D tissue model, and find the 2D model to be substantially more accurate. Furthermore, we find the 2D model to be more robust under stringent gene set selection, whereas the 3D model suffers substantial accuracy degradation. While both approaches have advantages and disadvantages, we propose that our described 2D approach could be a valuable tool for decision makers when prioritizing neurotoxicity screening.
Lifted Variable Elimination for Probabilistic Logic Programming
Oct 10, 2014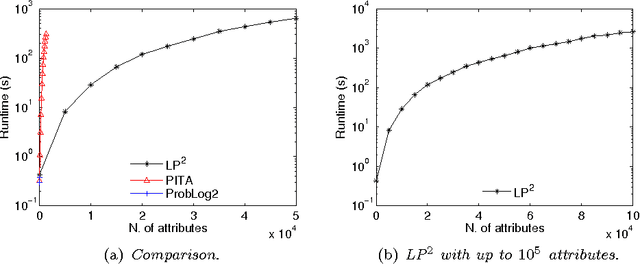
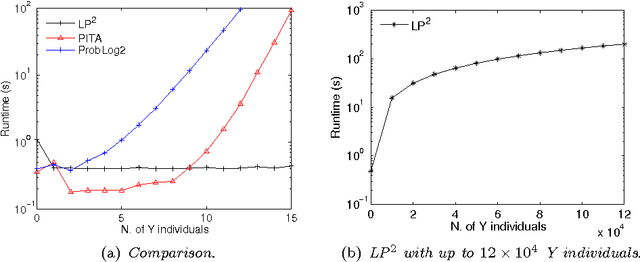
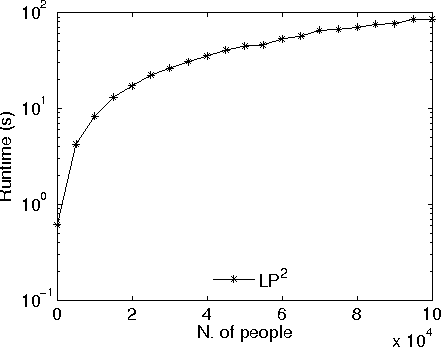
Lifted inference has been proposed for various probabilistic logical frameworks in order to compute the probability of queries in a time that depends on the size of the domains of the random variables rather than the number of instances. Even if various authors have underlined its importance for probabilistic logic programming (PLP), lifted inference has been applied up to now only to relational languages outside of logic programming. In this paper we adapt Generalized Counting First Order Variable Elimination (GC-FOVE) to the problem of computing the probability of queries to probabilistic logic programs under the distribution semantics. In particular, we extend the Prolog Factor Language (PFL) to include two new types of factors that are needed for representing ProbLog programs. These factors take into account the existing causal independence relationships among random variables and are managed by the extension to variable elimination proposed by Zhang and Poole for dealing with convergent variables and heterogeneous factors. Two new operators are added to GC-FOVE for treating heterogeneous factors. The resulting algorithm, called LP$^2$ for Lifted Probabilistic Logic Programming, has been implemented by modifying the PFL implementation of GC-FOVE and tested on three benchmarks for lifted inference. A comparison with PITA and ProbLog2 shows the potential of the approach.
CLP(BN): Constraint Logic Programming for Probabilistic Knowledge
Oct 19, 2012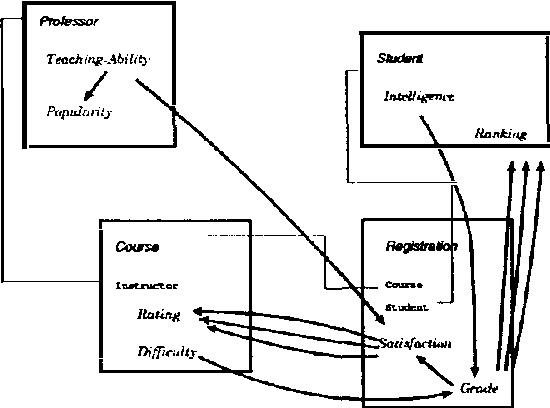
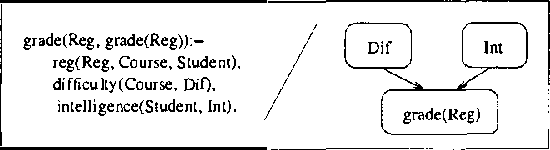
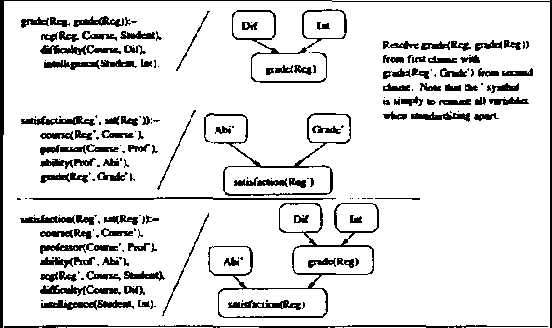
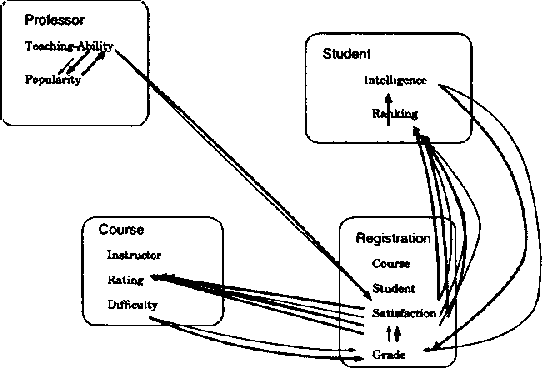
We present CLP(BN), a novel approach that aims at expressing Bayesian networks through the constraint logic programming framework. Arguably, an important limitation of traditional Bayesian networks is that they are propositional, and thus cannot represent relations between multiple similar objects in multiple contexts. Several researchers have thus proposed first-order languages to describe such networks. Namely, one very successful example of this approach are the Probabilistic Relational Models (PRMs), that combine Bayesian networks with relational database technology. The key difficulty that we had to address when designing CLP(cal{BN}) is that logic based representations use ground terms to denote objects. With probabilitic data, we need to be able to uniquely represent an object whose value we are not sure about. We use {sl Skolem functions} as unique new symbols that uniquely represent objects with unknown value. The semantics of CLP(cal{BN}) programs then naturally follow from the general framework of constraint logic programming, as applied to a specific domain where we have probabilistic data. This paper introduces and defines CLP(cal{BN}), and it describes an implementation and initial experiments. The paper also shows how CLP(cal{BN}) relates to Probabilistic Relational Models (PRMs), Ngo and Haddawys Probabilistic Logic Programs, AND Kersting AND De Raedts Bayesian Logic Programs.
Unachievable Region in Precision-Recall Space and Its Effect on Empirical Evaluation
Jul 18, 2012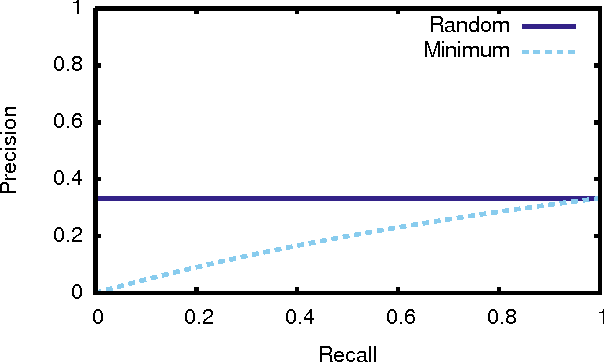
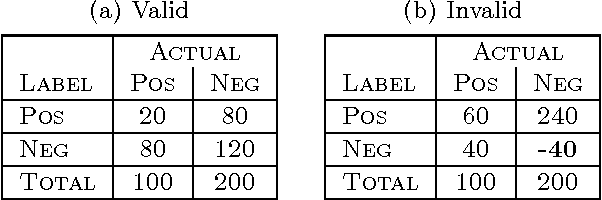
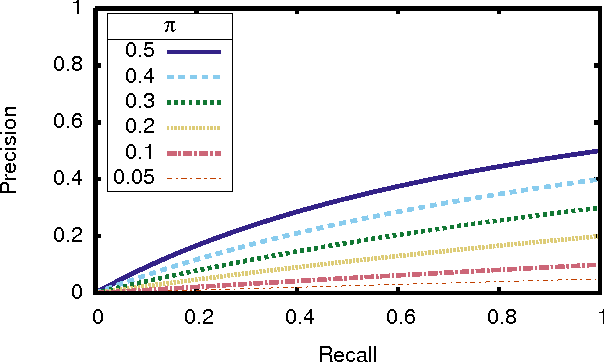
Precision-recall (PR) curves and the areas under them are widely used to summarize machine learning results, especially for data sets exhibiting class skew. They are often used analogously to ROC curves and the area under ROC curves. It is known that PR curves vary as class skew changes. What was not recognized before this paper is that there is a region of PR space that is completely unachievable, and the size of this region depends only on the skew. This paper precisely characterizes the size of that region and discusses its implications for empirical evaluation methodology in machine learning.
Demand-Driven Clustering in Relational Domains for Predicting Adverse Drug Events
Jun 27, 2012
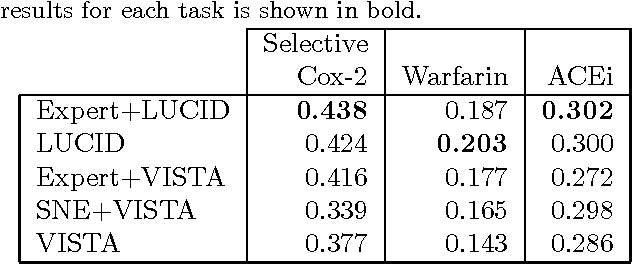
Learning from electronic medical records (EMR) is challenging due to their relational nature and the uncertain dependence between a patient's past and future health status. Statistical relational learning is a natural fit for analyzing EMRs but is less adept at handling their inherent latent structure, such as connections between related medications or diseases. One way to capture the latent structure is via a relational clustering of objects. We propose a novel approach that, instead of pre-clustering the objects, performs a demand-driven clustering during learning. We evaluate our algorithm on three real-world tasks where the goal is to use EMRs to predict whether a patient will have an adverse reaction to a medication. We find that our approach is more accurate than performing no clustering, pre-clustering, and using expert-constructed medical heterarchies.
A study of structural properties on profiles HMMs
Dec 11, 2008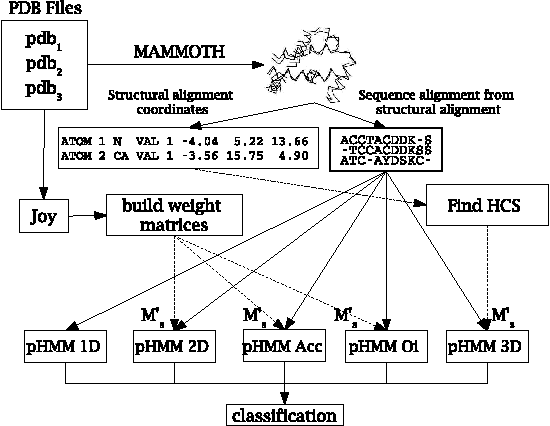
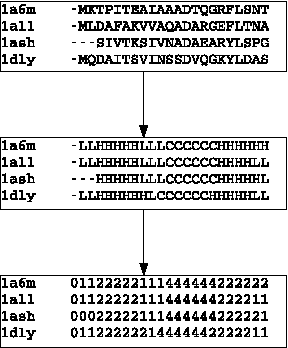
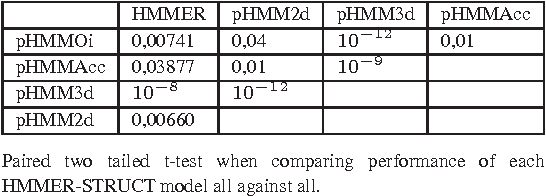
Motivation: Profile hidden Markov Models (pHMMs) are a popular and very useful tool in the detection of the remote homologue protein families. Unfortunately, their performance is not always satisfactory when proteins are in the 'twilight zone'. We present HMMER-STRUCT, a model construction algorithm and tool that tries to improve pHMM performance by using structural information while training pHMMs. As a first step, HMMER-STRUCT constructs a set of pHMMs. Each pHMM is constructed by weighting each residue in an aligned protein according to a specific structural property of the residue. Properties used were primary, secondary and tertiary structures, accessibility and packing. HMMER-STRUCT then prioritizes the results by voting. Results: We used the SCOP database to perform our experiments. Throughout, we apply leave-one-family-out cross-validation over protein superfamilies. First, we used the MAMMOTH-mult structural aligner to align the training set proteins. Then, we performed two sets of experiments. In a first experiment, we compared structure weighted models against standard pHMMs and against each other. In a second experiment, we compared the voting model against individual pHMMs. We compare method performance through ROC curves and through Precision/Recall curves, and assess significance through the paired two tailed t-test. Our results show significant performance improvements of all structurally weighted models over default HMMER, and a significant improvement in sensitivity of the combined models over both the original model and the structurally weighted models.