 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMahalanobis PatchCore: Covariance-Aware and Streaming-Compatible Industrial Anomaly Detection
May 26, 2026Industrial visual anomaly detection is usually one-class: normal images are abundant, while defects are rare, heterogeneous, and often unavailable during system design. PatchCore-style retrieval suits this setting because it scores test images from a memory bank of normal patch features, but the standard Euclidean geometry ignores feature correlations and its offline construction materialises the full patch pool before subsampling. We introduce Mahalanobis PatchCore, a covariance-aware, streaming-compatible extension of PatchCore. Its artificial intelligence contribution is a retrieval detector that estimates a regularised covariance model in reduced feature space and whitens embeddings, so Euclidean nearest-neighbour search after transformation implements Mahalanobis retrieval. A bounded-memory, re-iterable training pipeline builds the memory bank without storing all normal patches at once, using incremental dimensionality reduction, online covariance estimation, and streaming aggregation. The engineering application is automated industrial inspection, where visual anomaly detection must remain accurate under practical memory limits. We evaluate the method on a public 15-category industrial anomaly-detection benchmark and three industrial datasets covering blow-fill-seal strip-ampoule meniscus inspection, amber-glass-ampoule bottom inspection, and lyophilised-cake vial inspection. Mahalanobis PatchCore preserves most offline PatchCore image-level performance on the public benchmark while reducing peak memory from 5.41 to 2.78 GB, and improves the selected industrial mean image area under the receiver operating characteristic curve from 0.981 to 0.986.
Integration of deep generative Anomaly Detection algorithm in high-speed industrial line
Mar 08, 2026Industrial visual inspection in pharmaceutical production requires high accuracy under strict constraints on cycle time, hardware footprint, and operational cost. Manual inline inspection is still common, but it is affected by operator variability and limited throughput. Classical rule-based computer vision pipelines are often rigid and difficult to scale to highly variable production scenarios. To address these limitations, we present a semi-supervised anomaly detection framework based on a generative adversarial architecture with a residual autoencoder and a dense bottleneck, specifically designed for online deployment on a high-speed Blow-Fill-Seal (BFS) line. The model is trained only on nominal samples and detects anomalies through reconstruction residuals, providing both classification and spatial localization via heatmaps. The training set contains 2,815,200 grayscale patches. Experiments on a real industrial test kit show high detection performance while satisfying timing constraints compatible with a 500 ms acquisition slot.
GRD-Net: Generative-Reconstructive-Discriminative Anomaly Detection with Region of Interest Attention Module
Mar 08, 2026Anomaly detection is nowadays increasingly used in industrial applications and processes. One of the main fields of the appliance is the visual inspection for surface anomaly detection, which aims to spot regions that deviate from regularity and consequently identify abnormal products. Defect localization is a key task, that usually is achieved using a basic comparison between generated image and the original one, implementing some blob-analysis or image-editing algorithms, in the post-processing step, which is very biased towards the source dataset, and they are unable to generalize. Furthermore, in industrial applications, the totality of the image is not always interesting but could be one or some regions of interest (ROIs), where only in those areas there are relevant anomalies to be spotted. For these reasons, we propose a new architecture composed by two blocks. The first block is a Generative Adversarial Network (GAN), based on a residual autoencoder (ResAE), to perform reconstruction and denoising processes, while the second block produces image segmentation, spotting defects. This method learns from a dataset composed of good products and generated synthetic defects. The discriminative network is trained using a ROI for each image contained in the training dataset. The network will learn in which area anomalies are relevant. This approach guarantees the reduction of using pre-processing algorithms, formerly developed with blob-analysis and image-editing procedures. To test our model we used challenging MVTec anomaly detection datasets and an industrial large dataset of pharmaceutical BFS strips of vials. This set constitutes a more realistic use case of the aforementioned network.
* Peer-reviewed journal version published. 18 pages, 12 figures, 7 tables
Exploiting Uncertainty for Querying Inconsistent Description Logics Knowledge Bases
Jun 15, 2023



The necessity to manage inconsistency in Description Logics Knowledge Bases (KBs) has come to the fore with the increasing importance gained by the Semantic Web, where information comes from different sources that constantly change their content and may contain contradictory descriptions when considered either alone or together. Classical reasoning algorithms do not handle inconsistent KBs, forcing the debugging of the KB in order to remove the inconsistency. In this paper, we exploit an existing probabilistic semantics called DISPONTE to overcome this problem and allow queries also in case of inconsistent KBs. We implemented our approach in the reasoners TRILL and BUNDLE and empirically tested the validity of our proposal. Moreover, we formally compare the presented approach to that of the repair semantics, one of the most established semantics when considering DL reasoning tasks.
Non-ground Abductive Logic Programming with Probabilistic Integrity Constraints
Aug 06, 2021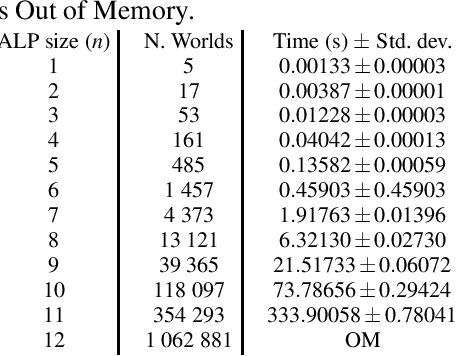

Uncertain information is being taken into account in an increasing number of application fields. In the meantime, abduction has been proved a powerful tool for handling hypothetical reasoning and incomplete knowledge. Probabilistic logical models are a suitable framework to handle uncertain information, and in the last decade many probabilistic logical languages have been proposed, as well as inference and learning systems for them. In the realm of Abductive Logic Programming (ALP), a variety of proof procedures have been defined as well. In this paper, we consider a richer logic language, coping with probabilistic abduction with variables. In particular, we consider an ALP program enriched with integrity constraints `a la IFF, possibly annotated with a probability value. We first present the overall abductive language, and its semantics according to the Distribution Semantics. We then introduce a proof procedure, obtained by extending one previously presented, and prove its soundness and completeness.
A Framework for Reasoning on Probabilistic Description Logics
Oct 02, 2020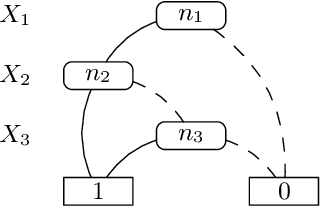


While there exist several reasoners for Description Logics, very few of them can cope with uncertainty. BUNDLE is an inference framework that can exploit several OWL (non-probabilistic) reasoners to perform inference over Probabilistic Description Logics. In this chapter, we report the latest advances implemented in BUNDLE. In particular, BUNDLE can now interface with the reasoners of the TRILL system, thus providing a uniform method to execute probabilistic queries using different settings. BUNDLE can be easily extended and can be used either as a standalone desktop application or as a library in OWL API-based applications that need to reason over Probabilistic Description Logics. The reasoning performance heavily depends on the reasoner and method used to compute the probability. We provide a comparison of the different reasoning settings on several datasets.
Automatic Setting of DNN Hyper-Parameters by Mixing Bayesian Optimization and Tuning Rules
Jun 03, 2020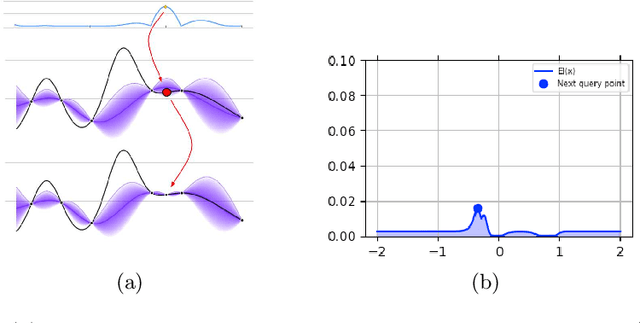

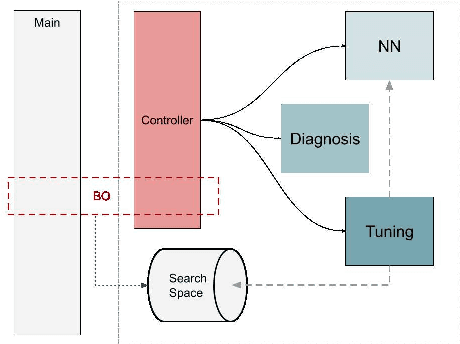

Deep learning techniques play an increasingly important role in industrial and research environments due to their outstanding results. However, the large number of hyper-parameters to be set may lead to errors if they are set manually. The state-of-the-art hyper-parameters tuning methods are grid search, random search, and Bayesian Optimization. The first two methods are expensive because they try, respectively, all possible combinations and random combinations of hyper-parameters. Bayesian Optimization, instead, builds a surrogate model of the objective function, quantifies the uncertainty in the surrogate using Gaussian Process Regression and uses an acquisition function to decide where to sample the new set of hyper-parameters. This work faces the field of Hyper-Parameters Optimization (HPO). The aim is to improve Bayesian Optimization applied to Deep Neural Networks. For this goal, we build a new algorithm for evaluating and analyzing the results of the network on the training and validation sets and use a set of tuning rules to add new hyper-parameters and/or to reduce the hyper-parameter search space to select a better combination.
Probabilistic DL Reasoning with Pinpointing Formulas: A Prolog-based Approach
Sep 17, 2018
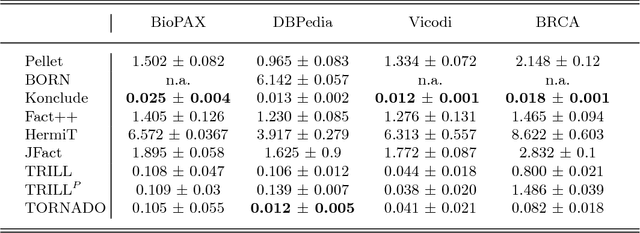

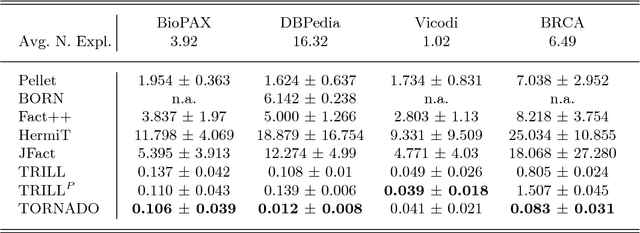
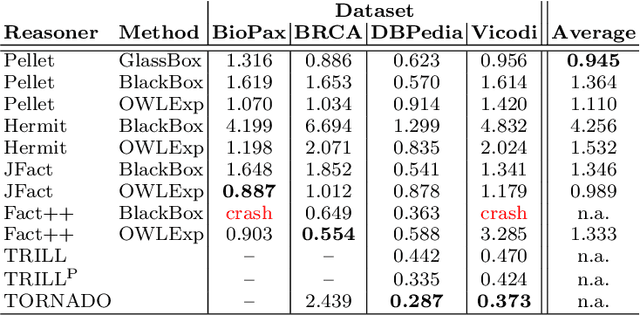
When modeling real world domains we have to deal with information that is incomplete or that comes from sources with different trust levels. This motivates the need for managing uncertainty in the Semantic Web. To this purpose, we introduced a probabilistic semantics, named DISPONTE, in order to combine description logics with probability theory. The probability of a query can be then computed from the set of its explanations by building a Binary Decision Diagram (BDD). The set of explanations can be found using the tableau algorithm, which has to handle non-determinism. Prolog, with its efficient handling of non-determinism, is suitable for implementing the tableau algorithm. TRILL and TRILLP are systems offering a Prolog implementation of the tableau algorithm. TRILLP builds a pinpointing formula, that compactly represents the set of explanations and can be directly translated into a BDD. Both reasoners were shown to outperform state-of-the-art DL reasoners. In this paper, we present an improvement of TRILLP, named TORNADO, in which the BDD is directly built during the construction of the tableau, further speeding up the overall inference process. An experimental comparison shows the effectiveness of TORNADO. All systems can be tried online in the TRILL on SWISH web application at http://trill.ml.unife.it/.
Lifted Variable Elimination for Probabilistic Logic Programming
Oct 10, 2014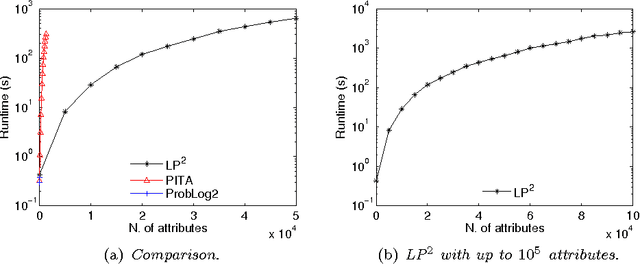
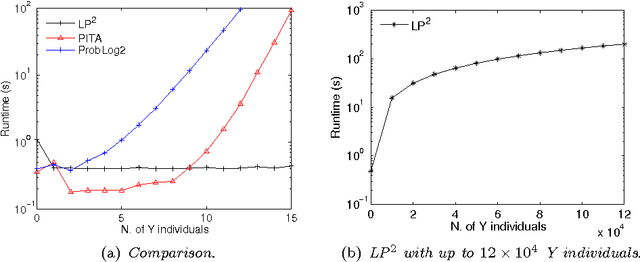
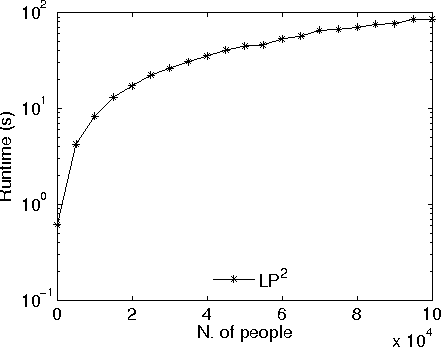
Lifted inference has been proposed for various probabilistic logical frameworks in order to compute the probability of queries in a time that depends on the size of the domains of the random variables rather than the number of instances. Even if various authors have underlined its importance for probabilistic logic programming (PLP), lifted inference has been applied up to now only to relational languages outside of logic programming. In this paper we adapt Generalized Counting First Order Variable Elimination (GC-FOVE) to the problem of computing the probability of queries to probabilistic logic programs under the distribution semantics. In particular, we extend the Prolog Factor Language (PFL) to include two new types of factors that are needed for representing ProbLog programs. These factors take into account the existing causal independence relationships among random variables and are managed by the extension to variable elimination proposed by Zhang and Poole for dealing with convergent variables and heterogeneous factors. Two new operators are added to GC-FOVE for treating heterogeneous factors. The resulting algorithm, called LP$^2$ for Lifted Probabilistic Logic Programming, has been implemented by modifying the PFL implementation of GC-FOVE and tested on three benchmarks for lifted inference. A comparison with PITA and ProbLog2 shows the potential of the approach.
A CHR-based Implementation of Known Arc-Consistency
Aug 24, 2004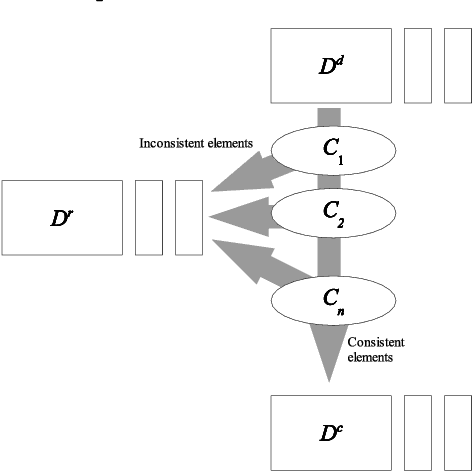
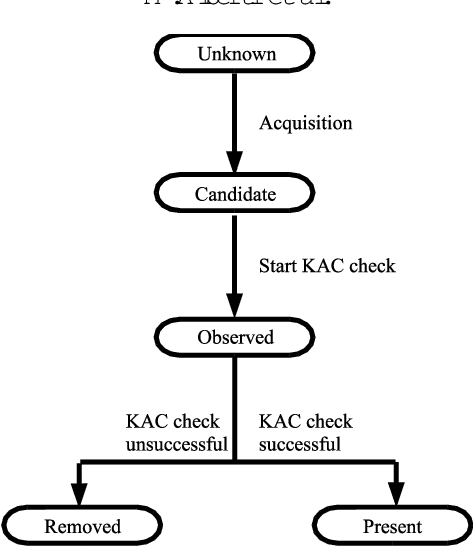
In classical CLP(FD) systems, domains of variables are completely known at the beginning of the constraint propagation process. However, in systems interacting with an external environment, acquiring the whole domains of variables before the beginning of constraint propagation may cause waste of computation time, or even obsolescence of the acquired data at the time of use. For such cases, the Interactive Constraint Satisfaction Problem (ICSP) model has been proposed as an extension of the CSP model, to make it possible to start constraint propagation even when domains are not fully known, performing acquisition of domain elements only when necessary, and without the need for restarting the propagation after every acquisition. In this paper, we show how a solver for the two sorted CLP language, defined in previous work, to express ICSPs, has been implemented in the Constraint Handling Rules (CHR) language, a declarative language particularly suitable for high level implementation of constraint solvers.