 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly-Stage Product Line Validation Using LLMs: A Study on Semi-Formal Blueprint Analysis
Apr 22, 2026We study whether Large Language Models (LLMs) can perform feature model analysis operations (AOs) directly on semi-formal textual blueprints, i.e., concise constrained-language descriptions of feature hierarchies and constraints, enabling early validation in Software Product Line scoping. Using 12 state-of-the-art LLMs and 16 standard AOs, we compare their outputs against the solver-based oracle FLAMA. Results show that reasoning-optimized models (e.g., Grok 4 Fast Reasoning, Gemini 2.5 Pro) achieve 88-89% average accuracy across all evaluated blueprints and operations, approaching solver correctness. We identify systematic errors in structural parsing and constraint reasoning, and highlight accuracy-cost trade-offs that inform model selection. These findings position LLMs as lightweight assistants for early variability validation.
Sustainability Evaluation Metrics for Recommender Systems
Jul 30, 2025Sustainability-oriented evaluation metrics can help to assess the quality of recommender systems beyond wide-spread metrics such as accuracy, precision, recall, and satisfaction. Following the United Nations`s sustainable development goals (SDGs), such metrics can help to analyse the impact of recommender systems on environmental, social, and economic aspects. We discuss different basic sustainability evaluation metrics for recommender systems and analyze their applications.
Recommender Systems for Sustainability: Overview and Research Issues
Dec 04, 2024


Sustainability development goals (SDGs) are regarded as a universal call to action with the overall objectives of planet protection, ending of poverty, and ensuring peace and prosperity for all people. In order to achieve these objectives, different AI technologies play a major role. Specifically, recommender systems can provide support for organizations and individuals to achieve the defined goals. Recommender systems integrate AI technologies such as machine learning, explainable AI (XAI), case-based reasoning, and constraint solving in order to find and explain user-relevant alternatives from a potentially large set of options. In this article, we summarize the state of the art in applying recommender systems to support the achievement of sustainability development goals. In this context, we discuss open issues for future research.
Less is More: Towards Sustainability-Aware Persuasive Explanations in Recommender Systems
Sep 27, 2024Recommender systems play an important role in supporting the achievement of the United Nations sustainable development goals (SDGs). In recommender systems, explanations can support different goals, such as increasing a user's trust in a recommendation, persuading a user to purchase specific items, or increasing the understanding of the reasons behind a recommendation. In this paper, we discuss the concept of "sustainability-aware persuasive explanations" which we regard as a major concept to support the achievement of the mentioned SDGs. Such explanations are orthogonal to most existing explanation approaches since they focus on a "less is more" principle, which per se is not included in existing e-commerce platforms. Based on a user study in three item domains, we analyze the potential impacts of sustainability-aware persuasive explanations. The study results are promising regarding user acceptance and the potential impacts of such explanations.
Sports Recommender Systems: Overview and Research Issues
Dec 06, 2023



Sports recommender systems receive an increasing attention due to their potential of fostering healthy living, improving personal well-being, and increasing performances in sport. These systems support people in sports, for example, by the recommendation of healthy and performance boosting food items, the recommendation of training practices, talent and team recommendation, and the recommendation of specific tactics in competitions. With applications in the virtual world, for example, the recommendation of maps or opponents in e-sports, these systems already transcend conventional sports scenarios where physical presence is needed. On the basis of different working examples, we present an overview of sports recommender systems applications and techniques. Overall, we analyze the related state-of-the-art and discuss open research issues.
Solving Multi-Configuration Problems: A Performance Analysis with Choco Solver
Oct 19, 2023
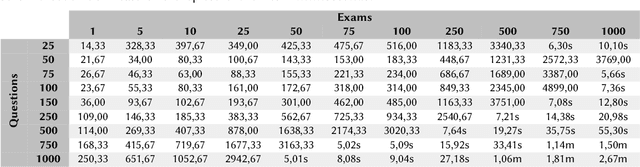
In many scenarios, configurators support the configuration of a solution that satisfies the preferences of a single user. The concept of \emph{multi-configuration} is based on the idea of configuring a set of configurations. Such a functionality is relevant in scenarios such as the configuration of personalized exams, the configuration of project teams, and the configuration of different trips for individual members of a tourist group (e.g., when visiting a specific city). In this paper, we exemplify the application of multi-configuration for generating individualized exams. We also provide a constraint solver performance analysis which helps to gain some insights into corresponding performance issues.
FastDiagP: An Algorithm for Parallelized Direct Diagnosis
May 11, 2023


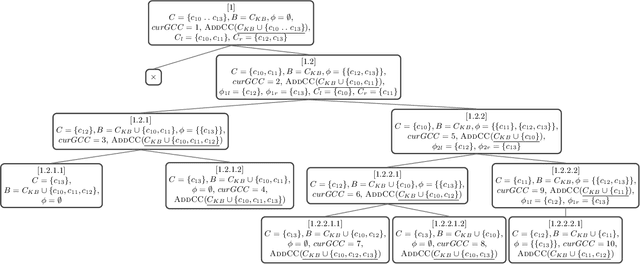
Constraint-based applications attempt to identify a solution that meets all defined user requirements. If the requirements are inconsistent with the underlying constraint set, algorithms that compute diagnoses for inconsistent constraints should be implemented to help users resolve the "no solution could be found" dilemma. FastDiag is a typical direct diagnosis algorithm that supports diagnosis calculation without predetermining conflicts. However, this approach faces runtime performance issues, especially when analyzing complex and large-scale knowledge bases. In this paper, we propose a novel algorithm, so-called FastDiagP, which is based on the idea of speculative programming. This algorithm extends FastDiag by integrating a parallelization mechanism that anticipates and pre-calculates consistency checks requested by FastDiag. This mechanism helps to provide consistency checks with fast answers and boosts the algorithm's runtime performance. The performance improvements of our proposed algorithm have been shown through empirical results using the Linux-2.6.3.33 configuration knowledge base.
Conjunctive Query Based Constraint Solving For Feature Model Configuration
Apr 26, 2023Feature model configuration can be supported on the basis of various types of reasoning approaches. Examples thereof are SAT solving, constraint solving, and answer set programming (ASP). Using these approaches requires technical expertise of how to define and solve the underlying configuration problem. In this paper, we show how to apply conjunctive queries typically supported by today's relational database systems to solve constraint satisfaction problems (CSP) and -- more specifically -- feature model configuration tasks. This approach allows the application of a wide-spread database technology to solve configuration tasks and also allows for new algorithmic approaches when it comes to the identification and resolution of inconsistencies.
Configuring Multiple Instances with Multi-Configuration
Sep 20, 2021Configuration is a successful application area of Artificial Intelligence. In the majority of the cases, configuration systems focus on configuring one solution (configuration) that satisfies the preferences of a single user or a group of users. In this paper, we introduce a new configuration approach - multi-configuration - that focuses on scenarios where the outcome of a configuration process is a set of configurations. Example applications thereof are the configuration of personalized exams for individual students, the configuration of project teams, reviewer-to-paper assignment, and hotel room assignments including individualized city trips for tourist groups. For multi-configuration scenarios, we exemplify a constraint satisfaction problem representation in the context of configuring exams. The paper is concluded with a discussion of open issues for future work.
Group Recommendation Techniques for Feature Modeling and Configuration
Apr 13, 2021In large-scale feature models, feature modeling and configuration processes are highly expected to be done by a group of stakeholders. In this context, recommendation techniques can increase the efficiency of feature-model design and find optimal configurations for groups of stakeholders. Existing studies show plenty of issues concerning feature model navigation support, group members' satisfaction, and conflict resolution. This study proposes group recommendation techniques for feature modeling and configuration on the basis of addressing the mentioned issues.