 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfiguring Multiple Instances with Multi-Configuration
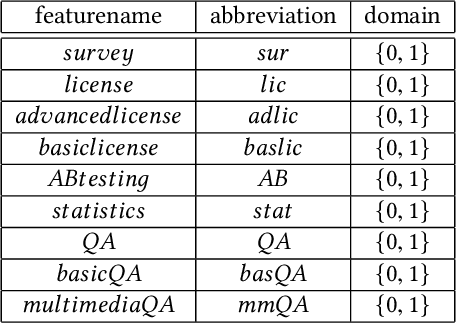
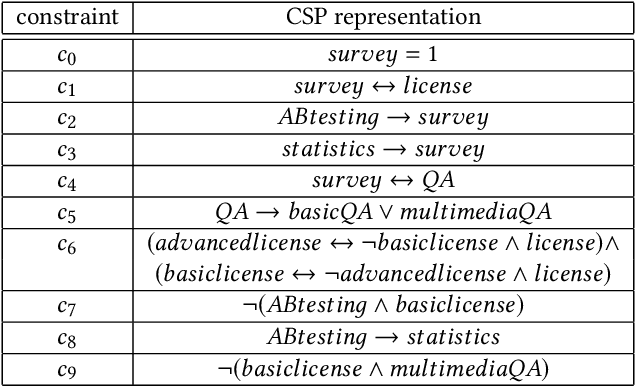
Sep 20, 2021Configuration is a successful application area of Artificial Intelligence. In the majority of the cases, configuration systems focus on configuring one solution (configuration) that satisfies the preferences of a single user or a group of users. In this paper, we introduce a new configuration approach - multi-configuration - that focuses on scenarios where the outcome of a configuration process is a set of configurations. Example applications thereof are the configuration of personalized exams for individual students, the configuration of project teams, reviewer-to-paper assignment, and hotel room assignments including individualized city trips for tourist groups. For multi-configuration scenarios, we exemplify a constraint satisfaction problem representation in the context of configuring exams. The paper is concluded with a discussion of open issues for future work.
Consistency-based Merging of Variability Models
Feb 15, 2021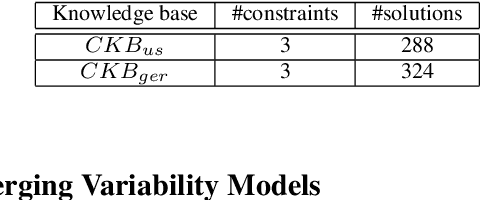

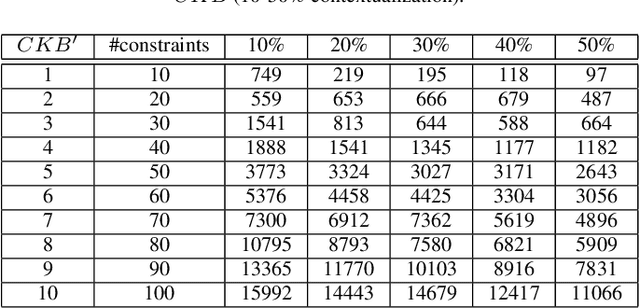
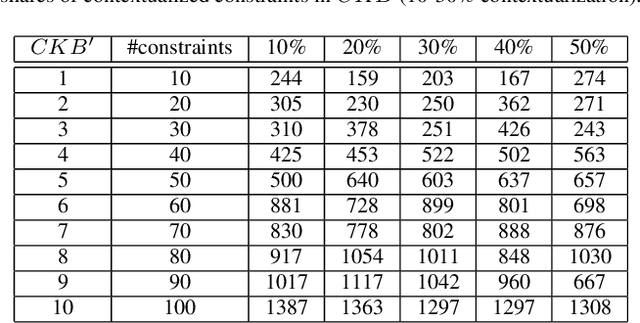
Globally operating enterprises selling large and complex products and services often have to deal with situations where variability models are locally developed to take into account the requirements of local markets. For example, cars sold on the U.S. market are represented by variability models in some or many aspects different from European ones. In order to support global variability management processes, variability models and the underlying knowledge bases often need to be integrated. This is a challenging task since an integrated knowledge base should not produce results which are different from those produced by the individual knowledge bases. In this paper, we introduce an approach to variability model integration that is based on the concepts of contextual modeling and conflict detection. We present the underlying concepts and the results of a corresponding performance analysis.
An Overview of Recommender Systems and Machine Learning in Feature Modeling and Configuration
Feb 12, 2021

Recommender systems support decisions in various domains ranging from simple items such as books and movies to more complex items such as financial services, telecommunication equipment, and software systems. In this context, recommendations are determined, for example, on the basis of analyzing the preferences of similar users. In contrast to simple items which can be enumerated in an item catalog, complex items have to be represented on the basis of variability models (e.g., feature models) since a complete enumeration of all possible configurations is infeasible and would trigger significant performance issues. In this paper, we give an overview of a potential new line of research which is related to the application of recommender systems and machine learning techniques in feature modeling and configuration. In this context, we give examples of the application of recommender systems and machine learning and discuss future research issues.
DirectDebug: Automated Testing and Debugging of Feature Models
Feb 11, 2021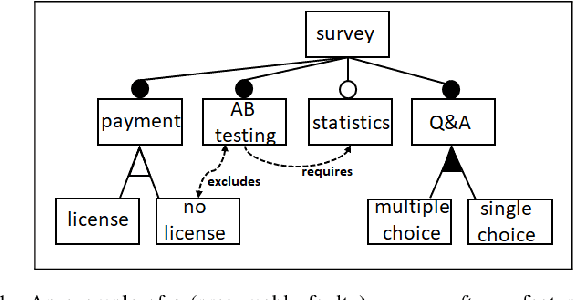



Variability models (e.g., feature models) are a common way for the representation of variabilities and commonalities of software artifacts. Such models can be translated to a logical representation and thus allow different operations for quality assurance and other types of model property analysis. Specifically, complex and often large-scale feature models can become faulty, i.e., do not represent the expected variability properties of the underlying software artifact. In this paper, we introduce DirectDebug which is a direct diagnosis approach to the automated testing and debugging of variability models. The algorithm helps software engineers by supporting an automated identification of faulty constraints responsible for an unintended behavior of a variability model. This approach can significantly decrease development and maintenance efforts for such models.